此文章主要是结合哔站shuhuai008大佬的白板推导视频:生成模型综述_109min
全部笔记的汇总贴:机器学习-白板推导系列笔记
一、定义
从概率分布的角度考虑,对于一堆样本数据,每个均有特征 X i X_i Xi对应分类标记 y i y_i yi。
生成模型:学习得到联合概率分布 P ( x , y ) P(x,y) P(x,y),即特征 x x x和标记 y y y共同出现的概率,然后求条件概率分布。能够学习到数据生成的机制,关注的时样本分布的本身。
判别模型:学习得到条件概率分布 P ( y ∣ x ) P(y|x) P(y∣x),即在特征x出现的情况下标记 y y y出现的概率。
数据要求:生成模型需要的数据量比较大,能够较好地估计概率密度;而判别模型对数据样本量的要求没有那么多。
简单的说,生成模型是从大量的数据中找规律,属于统计学习;而判别模型只关心不同类型的数据的差别,利用差别来分类。
生成式模型:
朴素贝叶斯
混合高斯模型
隐马尔科夫模型(HMM)
贝叶斯网络
Sigmoid Belief Networks
马尔科夫随机场(Markov Random Fields)
深度信念网络(DBN)
判别式模型:
K近邻(KNN)
线性回归(Linear Regression)
逻辑回归(Logistic Regression)
神经网络(NN)
支持向量机(SVM)
高斯过程(Gaussian Process)
条件随机场(CRF)
CART(Classification and Regression Tree)扫描二维码关注公众号,回复: 12192673 查看本文章
二、监督VS非监督
分类、回归、标记、降维、聚类、特征学习、密度估计、生成数据
{ 监 督 { 概 率 模 型 { 判 别 模 型 ( p ( Y ∣ X ) ) : L R , M E M M , C R F 生 成 模 型 非 概 率 模 型 : P L A , S V M , K N N , N N , T r e e M o d e l 非 监 督 { 概 率 模 型 : 生 成 模 型 非 概 率 模 型 : P C A , L S A , K − m e a n s , A u t o − e n c o d e r \left\{\begin{matrix} 监督\left\{\begin{matrix} 概率模型\left\{\begin{matrix} 判别模型(p(Y|X)):LR,MEMM,CRF\\\\{\color{blue}生成模型} \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\ \end{matrix}\right.\\\\非概率模型:PLA,SVM,KNN,NN,Tree\;Model \;\;\;\;\;\;\;\end{matrix}\right.\\\\\;\;\;\;\;\;\;\;\;\;\;\;非监督\left\{\begin{matrix} {\color{blue}概率模型:生成模型}\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\\\\非概率模型:PCA,LSA,K-means,Auto-encoder\;\;\;\;\;\;\;\;\;\;\;\;\;\ \end{matrix}\right. \end{matrix}\right. ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧监督⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧概率模型⎩⎨⎧判别模型(p(Y∣X)):LR,MEMM,CRF生成模型 非概率模型:PLA,SVM,KNN,NN,TreeModel非监督⎩⎨⎧概率模型:生成模型非概率模型:PCA,LSA,K−means,Auto−encoder
生成模型:
- Naive Bayes 朴素贝叶斯
- Mixture Model 混合模型 eg: GMM高斯混合模型
- Time-series Model 时间连续模型 eg:HMM隐马尔可夫模型,KF卡曼滤波,PF粒子滤波
- Non-parameteric Bayesian Model eg:GP高斯过程回归,DP迪利克雷过程
- Mixed Memership Model eg:LDA
- Factorial Model eg:FA,P-PCA,ICA
- Energy-based Model eg:BM
- VAE
- GAN,GSA
- Autoregressive Model
- Flow-based Model
PCA ⟶ \longrightarrow ⟶P-PCA ⟶ \longrightarrow ⟶FA
K-means ⟶ \longrightarrow ⟶GMM
Auto-encoder ⟶ \longrightarrow ⟶VAE
LSA ⟶ \longrightarrow ⟶PLSA ⟶ \longrightarrow ⟶LDA
三、表示、推断、学习
任务:Supervised VS. Unsupervised
(一)表示
形 神 兼 备 { 形 { D i s c r e t e V S . C o n t i n u o u s D i r e c t e d M o d e l V S . U n d i r e c t e d M o d e l L a t e n t V a r i a b l e M o d e l V S . F u l l y − o b s e r v e d M o d e l S h a l l o w V S . D e e p ( 层 ) S p a r s e V S . D e n s e ( 连 接 ) 神 { P a r a m e t e r i c M o d e l V S . N o n − p a r a m e t e r i c I m p l i c i t D e n s i t y V S . E x p l i c i t D e n s i t y 形神兼备\left\{\begin{matrix} 形\left\{\begin{matrix} Discrete\;VS.\;Continuous\\\\Directed\;Model\;VS.\;Undirected\;Model\\\\Latent\;Variable\;Model\;VS.\;Fully-observed\;Model\\\\Shallow\;VS.\;Deep\;(层)\\\\Sparse\;VS.\;Dense\;(连接)\end{matrix}\right. \\\\神\left\{\begin{matrix} Parameteric\;Model\;VS.\;Non-parameteric\\\\Implicit\;Density\;VS.\;Explicit\;Density\end{matrix}\right. \end{matrix}\right. 形神兼备⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧形⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧DiscreteVS.ContinuousDirectedModelVS.UndirectedModelLatentVariableModelVS.Fully−observedModelShallowVS.Deep(层)SparseVS.Dense(连接)神⎩⎨⎧ParametericModelVS.Non−parametericImplicitDensityVS.ExplicitDensity
(二)推断
tractable VS. intractable
(三)学习
likelihood-based Model VS. likelihood-free Model
四、模型分类
M a x i m u m l i k e l i h o o d { b a s e d : e x p l i c i t d e n s i t y { t r a c t a b l e { F u l l y O b s e r v e d ( A u t o r e g r e s s i v e M o d e l ) C h a n g e O f V a r i a b l e ( F l o w − b a s e d M o d e l , N o n − l i n e a r I C A ) a p p r o x i m a t e i n f e r e n c e { V a r i a t i o n a l ( V A E ) M C ( E n e r g y − b a s e d M o d e l ) f r e e : i m p l i c i t d e n s i t y { D i r e c t ( G A N ) M C ( G S N 生 成 随 机 网 络 ) Maximum \;likelihood \left\{\begin{matrix} based:explicit\;density\left\{\begin{matrix} tractable\left\{\begin{matrix} Fully\;Observed(Autoregressive\;Model)\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\\\\Change\;Of\;Variable(Flow-based\;Model,Non-linear\;ICA) \end{matrix}\right.\\\\approximate\;inference \left\{\begin{matrix} Variational(VAE)\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\\\\MC(Energy-based\;Model) \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\end{matrix}\right.\end{matrix}\right.\\\\free:implicit\;density \left\{\begin{matrix} Direct(GAN)\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\\\\MC(GSN\;生成随机网络)\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\; \end{matrix}\right.\end{matrix}\right. Maximumlikelihood⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧based:explicitdensity⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧tractable⎩⎨⎧FullyObserved(AutoregressiveModel)ChangeOfVariable(Flow−basedModel,Non−linearICA)approximateinference⎩⎨⎧Variational(VAE)MC(Energy−basedModel)free:implicitdensity⎩⎨⎧Direct(GAN)MC(GSN生成随机网络)
五、概率图vs神经网络
概率图就是对概率分布的表示;神经网络就是一个函数逼近器,只不过这个函数可能会很复杂。
但二者也不是没有联系,二者的关系不是非此即彼的(男人和女人),而是有区别也有联系的(男人和医生),例如玻尔兹曼机既属于无向图模型,也属于神经网络。
神经网络可以分为确定性神经网络(前馈神经网络,CNN,RNN)和随机神经网络(BM)。
我们进行对比,主要是用Bayesian Network VS. Neural Network
- 表示:
BN:结构化的、稀疏(条件独立性假设)、浅层,具备可解释性
NN:深层、稠密、计算图,可解释性未知
- 推断:
BN:精确、近似(MC、变分)
NN:推断很容易,但没有意义
- 学习:
BN:likelihood Maxi;EM
NN:梯度下降(BP后向传播:一种高效的求导方法,链式求导法则+动态规划(递归+缓存))
- 适合场景:
BN:high level reasoning
NN:表示学习,low level reasoning
六、重参数化技巧(随机后向传播)
(一)概率分布
P ( y ) = N ( μ , σ 2 ) θ = { μ , σ 2 } Z ∼ N ( 0 , 1 ) y = μ + σ ⋅ Z Z ( i ) ∼ N ( 0 , 1 ) y ( i ) = μ + σ ⋅ Z ( i ) y = f ( μ , σ , Z ) P(y)=N(\mu,\sigma^2)\;\;\;\theta=\{\mu,\sigma^2\}\\Z\sim N(0,1)\\y=\mu+\sigma\cdot Z\\Z^{(i)}\sim N(0,1)\\y^{(i)}=\mu+\sigma\cdot Z^{(i)}\\y=f(\mu,\sigma,Z) P(y)=N(μ,σ2)θ={
μ,σ2}Z∼N(0,1)y=μ+σ⋅ZZ(i)∼N(0,1)y(i)=μ+σ⋅Z(i)y=f(μ,σ,Z)
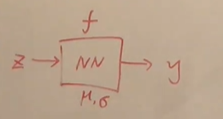
J ( y ) : 目 标 函 数 J(y):目标函数 J(y):目标函数
∇ J ( y ) ∇ θ = ∇ J ( y ) ∇ y ∇ y ∇ θ \frac{\nabla J(y)}{\nabla \theta}=\frac{\nabla J(y)}{\nabla y}\frac{\nabla y}{\nabla \theta} ∇θ∇J(y)=∇y∇J(y)∇θ∇y
(二)条件概率分布
P ( y ∣ x ) = N ( x ; μ , σ 2 ) Z ∼ N ( 0 , 1 ) y = μ θ ( x ) + σ θ ( x ) ⋅ Z P(y|x)=N(x;\mu,\sigma^2)\\Z\sim N(0,1)\\y=\mu_\theta(x)+\sigma_\theta(x)\cdot Z P(y∣x)=N(x;μ,σ2)Z∼N(0,1)y=μθ(x)+σθ(x)⋅Z
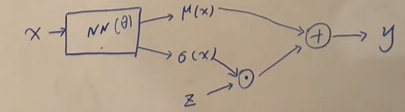
J θ ( y ) = ∑ i = 1 N ∣ ∣ y − y ( i ) ∣ ∣ 2 J_\theta(y)=\sum_{i=1}^N{||y-y^{(i)}||}^2 Jθ(y)=i=1∑N∣∣y−y(i)∣∣2
∇ J θ ( y ) ∇ θ = ∇ J θ ( y ) ∇ y ∇ y ∇ μ ∇ μ ∇ θ + ∇ J θ ( y ) ∇ y ∇ y ∇ σ ∇ σ ∇ θ \frac{\nabla J_\theta(y)}{\nabla \theta}=\frac{\nabla J_\theta(y)}{\nabla y}\frac{\nabla y}{\nabla \mu}\frac{\nabla \mu}{\nabla \theta}+\frac{\nabla J_\theta(y)}{\nabla y}\frac{\nabla y}{\nabla \sigma}\frac{\nabla \sigma}{\nabla \theta} ∇θ∇Jθ(y)=∇y∇Jθ(y)∇μ∇y∇θ∇μ+∇y∇Jθ(y)∇σ∇y∇θ∇σ
下一章传送门:白板推导系列笔记(三十一)-生成对抗网络