此文章主要是结合哔站shuhuai008大佬的白板推导视频:深度信念网络_72min
全部笔记的汇总贴:机器学习-白板推导系列笔记
对应花书20.3
一、介绍
DBN(深度信念网络 )的引入开始了当前深度学习的复兴。实质上是一个混合模型
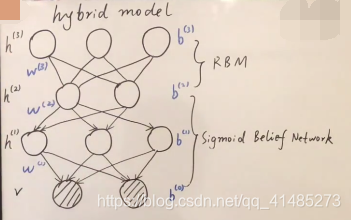
P ( v , h ( 1 ) , h ( 2 ) , h ( 3 ) ) = P ( v ∣ h ( 1 ) , h ( 2 ) , h ( 3 ) ) ⋅ P ( h ( 1 ) , h ( 2 ) , h ( 3 ) ) = P ( v ∣ h ( 1 ) ) ⋅ P ( h ( 1 ) , h ( 2 ) , h ( 3 ) ) = P ( v ∣ h ( 1 ) ) ⋅ P ( h ( 1 ) ∣ h ( 2 ) ) ⋅ P ( h ( 2 ) , h ( 3 ) ) = ∏ i P ( v i ∣ h ( 1 ) ) ⋅ ∏ j P ( h j ( 1 ) ∣ h ( 2 ) ) ⋅ P ( h ( 2 ) , h ( 3 ) ) P(v,h^{(1)},h^{(2)},h^{(3)})=P(v|h^{(1)},h^{(2)},h^{(3)})\cdot P(h^{(1)},h^{(2)},h^{(3)})\\=P(v|h^{(1)})\cdot P(h^{(1)},h^{(2)},h^{(3)})\\=P(v|h^{(1)})\cdot P(h^{(1)}|h^{(2)})\cdot P(h^{(2)},h^{(3)})\\=\prod_iP(v_i|h^{(1)})\cdot\prod_jP(h_j^{(1)}|h^{(2)})\cdot P(h^{(2)},h^{(3)}) P(v,h(1),h(2),h(3))=P(v∣h(1),h(2),h(3))⋅P(h(1),h(2),h(3))=P(v∣h(1))⋅P(h(1),h(2),h(3))=P(v∣h(1))⋅P(h(1)∣h(2))⋅P(h(2),h(3))=i∏P(vi∣h(1))⋅j∏P(hj(1)∣h(2))⋅P(h(2),h(3))
θ = { w ( 1 ) , w ( 2 ) , w ( 3 ) , b ( 0 ) , b ( 1 ) , b ( 2 ) , b ( 3 ) } w : , i : i t h c o l u m n n e c t o r o f w \theta=\{w^{(1)},w^{(2)},w^{(3)},b^{(0)},b^{(1)},b^{(2)},b^{(3)}\}\\w_{:,i}:i \;th\;column\;nector\;of\;w θ={ w(1),w(2),w(3),b(0),b(1),b(2),b(3)}w:,i:ithcolumnnectorofw
P ( v i ∣ h ( 1 ) ) = s i g m o i d ( w : , i ( 1 ) T ⋅ h ( 1 ) + b i ( 0 ) ) P(v_i|h^{(1)})=sigmoid({w_{:,i}^{(1)}}^T\cdot h^{(1)}+b_i^{(0)}) P(vi∣h(1))=sigmoid(w:,i(1)T⋅h(1)+bi(0))
\;
P ( h j ( 1 ) ∣ h ( 2 ) ) = s i g m o i d ( w : , i ( 2 ) T ⋅ h ( 2 ) + b j ( 1 ) ) P(h_j^{(1)}|h^{(2)})=sigmoid({w_{:,i}^{(2)}}^T\cdot h^{(2)}+b_j^{(1)}) P(hj(1)∣h(2))=sigmoid(w:,i(2)T⋅h(2)+bj(1))
\;
P ( h ( 2 ) , h ( 3 ) ) = 1 Z exp { h ( 3 ) T ⋅ w ( 3 ) ⋅ h ( 2 ) + h ( 2 ) T ⋅ b ( 2 ) + h ( 3 ) T ⋅ b ( 3 ) } P(h^{(2)},h^{(3)})=\frac1Z\exp\{ {h^{(3)}}^T\cdot w^{(3)}\cdot h^{(2)}+{h^{(2)}}^T\cdot b^{(2)}+{h^{(3)}}^T\cdot b^{(3)}\} P(h(2),h(3))=Z1exp{ h(3)T⋅w(3)⋅h(2)+h(2)T⋅b(2)+h(3)T⋅b(3)}
二、Stacking RBM
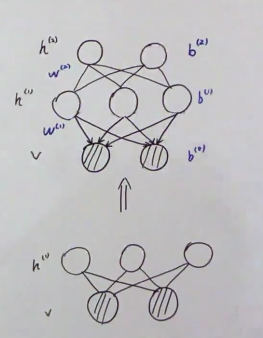
P ( v ) = ∑ h ( 1 ) P ( v , h ( 1 ) ) = ∑ h ( 1 ) P ( h ( 1 ) ) ⏟ p r i o r P ( v ∣ h ( 1 ) ) ⏟ f i x e d P(v)=\sum_{h^{(1)}}P(v,h^{(1)})\\=\sum_{h^{(1)}}\underset{prior}{\underbrace{P(h^{(1)})}}\underset{fixed}{\underbrace{P(v|h^{(1)})}} P(v)=h(1)∑P(v,h(1))=h(1)∑prior P(h(1))fixed P(v∣h(1))
P ( h ( 1 ) ) = ∑ h ( 2 ) P ( h ( 1 ) , h ( 2 ) ) P(h^{(1)})=\sum_{h^{(2)}}P(h^{(1)},h^{(2)}) P(h(1))=h(2)∑P(h(1),h(2))
我们通过ELBO来看这两个模型,我们先看上图中下面的模型,
log p ( v ) = log ∑ h ( 1 ) p ( v , h ( 1 ) ) = log ∑ h ( 1 ) q ( h ( 1 ) ∣ v ) p ( v , h ( 1 ) ) q ( h ( 1 ) ∣ v ) = log E q ( h ( 1 ) ∣ v ) [ p ( v , h ( 1 ) ) q ( h ( 1 ) ∣ v ) ] ≥ E q ( h ( 1 ) ∣ v ) [ log p ( v , h ( 1 ) ) q ( h ( 1 ) ∣ v ) ] = ∑ h ( 1 ) q ( h ( 1 ) ∣ v ) [ log p ( v , h ( 1 ) ) − log q ( h ( 1 ) ∣ v ) ] = ∑ h ( 1 ) q ( h ( 1 ) ∣ v ) [ log p ( h ( 1 ) ) + log p ( v ∣ h ( 1 ) ) − log q ( h ( 1 ) ∣ v ) ] \log p(v)=\log\sum_{h^{(1)}}p(v,h^{(1)})\\=\log\sum_{h^{(1)}}q(h^{(1)}|v)\frac{p(v,h^{(1)})}{q(h^{(1)}|v)}\\=\log E_{q(h^{(1)}|v)}\Big[\frac{p(v,h^{(1)})}{q(h^{(1)}|v)}\Big]\\\geq E_{q(h^{(1)}|v)}\Big[\log\frac{p(v,h^{(1)})}{q(h^{(1)}|v)}\Big]\\=\sum_{h^{(1)}}q(h^{(1)}|v)\Big[\log p(v,h^{(1)})-\log q(h^{(1)}|v)\Big]\\=\sum_{h^{(1)}}q(h^{(1)}|v)\Big[{\color{blue}\log p(h^{(1)})}+\log p(v|h^{(1)})-\log q(h^{(1)}|v)\Big] logp(v)=logh(1)∑p(v,h(1))=logh(1)∑q(h(1)∣v)q(h(1)∣v)p(v,h(1))=logEq(h(1)∣v)[q(h(1)∣v)p(v,h(1))]≥Eq(h(1)∣v)[logq(h(1)∣v)p(v,h(1))]=h(1)∑q(h(1)∣v)[logp(v,h(1))−logq(h(1)∣v)]=h(1)∑q(h(1)∣v)[logp(h(1))+logp(v∣h(1))−logq(h(1)∣v)]
2nd layer RBM Learning等价于maximum log-likelihood over p ( h ( 1 ) ) p(h^{(1)}) p(h(1))
我们增加一层就是为了让 p ( h ( 1 ) ) p(h^{(1)}) p(h(1))的似然达到最大,也就是improve了上式中的蓝色部分,也就提高了ELBO。
三、贪心预训练
log p ( v ) ≥ E L B O = ∑ h ( 1 ) q ( h ( 1 ) ∣ v ) ⋅ log p ( v , h ( 1 ) ) − ∑ h ( 1 ) q ( h ( 1 ) ∣ v ) log q ( h ( 1 ) ∣ v ) \log p(v)\geq ELBO=\sum_{h^{(1)}}q(h^{(1)}|v)\cdot\log p(v,h^{(1)})-\sum_{h^{(1)}}q(h^{(1)}|v)\log q(h^{(1)}|v) logp(v)≥ELBO=h(1)∑q(h(1)∣v)⋅logp(v,h(1))−h(1)∑q(h(1)∣v)logq(h(1)∣v)
q ( h ( 1 ) ∣ v ) = ∏ i q ( h i ( 1 ) ∣ v ) = ∏ i s i g m o i d ( w i , : ( 1 ) ⋅ v + b i ( 1 ) ) q(h^{(1)}|v)=\prod_i q(h_i^{(1)}|v)=\prod_isigmoid(w_{i,:}^{(1)}\cdot v+b_i^{(1)}) q(h(1)∣v)=i∏q(hi(1)∣v)=i∏sigmoid(wi,:(1)⋅v+bi(1))
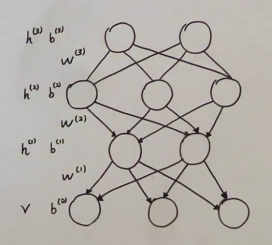
DBN ⟶ \longrightarrow ⟶ ELBO is relatively loose.
下一章传送门:白板推导系列笔记(二十八)-玻尔兹曼机