0 笔记说明
来源于【机器学习】【白板推导系列】【合集 1~23】,我在学习时会跟着up主一起在纸上推导,博客内容为对笔记的二次书面整理,根据自身学习需要,我可能会增加必要内容。
注意:本笔记主要是为了方便自己日后复习学习,而且确实是本人亲手一个字一个公式手打,如果遇到复杂公式,由于未学习LaTeX,我会上传手写图片代替(手机相机可能会拍的不太清楚,但是我会尽可能使内容完整可见),因此我将博客标记为【原创】,若您觉得不妥可以私信我,我会根据您的回复判断是否将博客设置为仅自己可见或其他,谢谢!
本博客为(系列九)的笔记,对应的视频是:【(系列九) 概率图模型1-背景介绍】、【(系列九) 概率图模型2-贝叶斯网络-条件独立性】、【(系列九) 概率图模型3-贝叶斯网络-D-Seperation】、【(系列九) 概率图模型4-贝叶斯网络-例子-具体模型】、【(系列九) 概率图模型5-马尔可夫随机场-Representation-条件独立性】、【(系列九) 概率图模型6-马尔可夫随机场-Representation-因子分解】、【(系列九) 概率图模型7-推断Inference-总体介绍】、【(系列九) 概率图模型8-推断Inference-Variable Elimination】、【(系列九) 概率图模型9-推断Inference-Variable Elimation To Belief Propagation】、【(系列九) 概率图模型10-推断Inference-Belief Propagation】、【(系列九) 概率图模型11-推断Inference-Max Product(1)】、【(系列九) 概率图模型12-推断Inference-Max-Product(2)】、【(系列九) 概率图模型13-概念补充-因子图-Factor Graph】、【(系列九) 概率图模型14-概念补充-道德图Moral Graph】。
下面开始即为正文。
1 背景介绍
1.1 概率公式
设x是一个高维随机变量,x∈Rp,记x=(x1,x2,…,xp)T,若已知x=(x1,x2,…,xp)T的概率即p(x)=p(x1,x2,…,xp),可以求:① 边缘概率p(xi),其中i=1,2,…,p;② 条件概率p(xj|xi),其中i=1,2,…,p,j=1,2,…,p。有以下四条运算法则:
(1)加法法则:若x是连续型随机变量,则p(xi)=∫xjp(xi,xj)dxj;若x是离散型随机变量,则p(xi)=Σxjp(xi,xj);
(2)乘法法则:p(xi,xj)=p(xi)p(xj|xi)=p(xj)p(xi|xj);
(3)链式法则:p(x1,x2,…,xp)=p(x1)·Πi=[2,p] p(xi|x1,x2,…,xi-1),【Πi=[2,p] 】指i从2到p将后面的公式进行连乘;
(4)贝叶斯公式:若x是连续型随机变量,则p(xj|xi)=p(xi,xj)/[∫xjp(xi,xj)dxj]=p(xj)p(xi|xj)/[∫xjp(xj)p(xi|xj)dxj];若x是离散型随机变量,则p(xj|xi)=p(xi,xj)/[Σxjp(xi,xj)]=p(xj)p(xi|xj)/[Σxjp(xj)p(xi|xj)]。
概率计算的难度随维度升高而增大。现在进行一定的简化:
(1)假设xj与xi之间相互独立,其中i=1,2,…,p,j=1,2,…,p,且i≠j,则p(x1,x2,…,xp)=Πi=[1,p] p(xi);
(2)齐次马尔可夫假设:xj⊥xi+1|xi,其中i=1,2,…,p,j=1,2,…,p,且j<i。可以这样理解:当前为i时刻,xj是过去的状态,xi+1是未来的状态,xi是现在的状态,即给定现在的状态的情况下,未来的状态与过去的状态相互独立,⊥表示相互独立;
(3)条件独立性:XA、XB、XC是三个互无交集的集合,给定任一个集合的情况下,另外两个集合相互独立,举个栗子,XA⊥XB|XC。
1.2 概率图简介
概率图模型是用图来表示变量概率依赖关系的理论,结合了概率论与图论的知识,利用图来表示与模型有关的变量的联合概率分布。
1.2.1 表示
概率图模型(Probabilistic Graphical Model,PGM)表示方法,研究如何利用概率网络中的独立性来简化联合概率分布的方法表示。根据边有无方向性分类,PGM可以分为三类:
1、有向图模型,也称为贝叶斯网(Bayesian Network,BN),其网络结构使用有向无环图;
2、无向图模型,也称为马尔可夫网(Markov Network,MN),其网络结构为无向图;
3、局部有向模型,即同时存在有向边和无向边的模型,包括条件随机场(Conditional Random Field,CRF)和链图(Chain Graph)。
1.2.2 推断
概率图模型推断方法分为两类:精确推断和近似推断,其中近似推断方法有:① 确定性近似,如变分推断;② 随机近似,如马尔可夫链蒙特卡洛方法(Markov Chain Monte Carlo,MCMC)。
1.2.3 学习
概率图模型学习算法分为参数学习与结构学习。
1.2.4 决策
本博文不做介绍。
1.3 图
概率图中的结点表示随机变量,边表示随机变量间的关系,结点之间若是有向边,则代表两个随机变量之间存在条件关系。下面是示例:
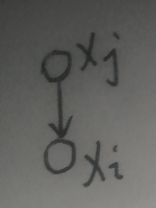
xj是xi的父结点,对于上图的有向边,箭头那一端称为head,另一边称为tail,上图表示的概率为p(xi|xj)。
2 贝叶斯网络
2.1 条件独立性
因子分解:p(x1,x2,…,xp)=Πi=[1,p] p(xi|xpa(i)),xpa(i)指xi的父结点集合。下面是一个示例:

任何复杂的有向图均可拆成下面三种局部图:
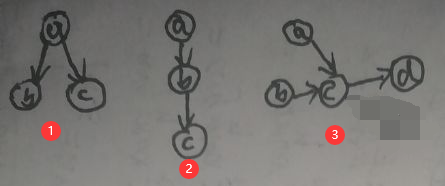
(1)图①中,对于a来说是tail to tail:若a被观测,则路径被阻塞,此时b和c独立,即b⊥c|a;
(2)图②中,对于b来说是head to tail:若b被观测,则路径被阻塞,此时a和c独立,即a⊥c|b;
(3)图③中,对于c来说是head to head:c为d的父结点。默认情况下a与b独立。若c或d被观测,则路径连通,此时a和b有关系且不独立。下面证明默认情况下a与b独立:
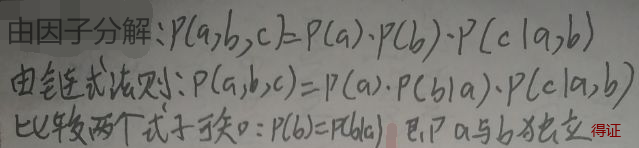
2.2 D-Seperation
XA、XB、XC是三个互无交集的集合,集合之间的路径是这样定义的:比如说XA与XC之间的路径是结点a途经结点bi到达结点c,其中a∈XA,c∈XC,bi∈XB或bi∉XB,有以下三种情况:
(1)若bi为head to tail,且bi∈XB,则XA⊥XC|XB;
(2)若bi为tail to tail,且bi∈XB,则XA⊥XC|XB;
(3)若bi为head to head,且bi∉XB,则XA⊥XC|XB。
上面三条是等价的,即(1)⇔(2)⇔(3),称为全局马尔可夫性。
为了方便解释,设x是连续型随机变量。记x-i为去掉xi后的其他结点,即x1,…,xi-1,xi+1,…,xp,则p(xi|x-i)为:

接下来讨论Δ杠是啥。假设xi及其有关系的结点的图如下:
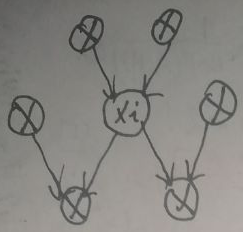
上上一个图片提到:记Δ杠为与xi/xj有关的式子,Δ杠是这些式子:① p(xi|xpa(i))和p(xj|xpa(j)),其中xpa(i)、xpa(j)分别指xi、xj的父结点集合;② p(xchild(i)|xi,xparentchild(i))和p(xchild(j)|xj,xparentchild(j)),xchild(i)、xchild(j)分别指xi、xj的子结点集合,xparentchild(i)、xparentchild(j)分别指xi、xj的子结点们的另一个双亲所构成的集合。
综上所述,与xj/xi有关系的结点为xj/xi的双亲、孩子及孩子的另一个双亲。
马尔可夫毯:结点xi的马尔可夫毯由相邻结点的集合组成。若以图中所有剩余变量为条件,xi的条件概率分布只依赖于马尔可夫毯中的变量,即结点只条件依赖于相邻结点,而条件独立于任何其他的结点。对于上一张图片中的xi,其马尔可夫毯为其他6个的结点。
2.3 具体模型
从单一模型到混合模型,时间从有限到无限,随机变量可以是连续型的也可以是离散型的:
(1)单一模型,如朴素贝叶斯(Naive Bayesian,NB),该算法用于分类,做出的假设是:p(x|y)=p(x1,x2,…,xp|y)=Πi=[1,p] p(xi|y),其中x∈Rp,y={0,1},NB的概率图如下,由下图可得:xi⊥xj|y,即给定y的情况下,x1,x2,…,xp相互独立:

(2)混合模型,如高斯混合模型(Gaussian Mixed Model,GMM),该算法用于分类,引入了离散的隐变量z:z=1,…,k,其中k为最终分类得到的类别数,做出的假设是:x|z~N(μ,ε),即给定z的情况下,x服从高斯分布。GMM的概率图如下:
(3)引入时间,如马尔可夫链(Markov Chain, MC)和高斯过程(Gaussian Process, GP),二者均是随机过程的一种,后者是无限维的高斯分布。
(4)混合模型+引入时间,即动态模型,如:① 隐马尔可夫模型(Hidden Markov Model,HMM),其中的隐状态是离散的;② 线性动态系统(Linear Dynamical System,LDS),即卡尔曼滤波;③ 粒子滤波(Particle Filter,PF)。
(5)连续,如高斯贝叶斯网络(Gaussian Bayesian Network,GBN)。
3 马尔可夫随机场
马尔可夫随机场(Markov Random Field , MRF),也被称为马尔可夫网络(Markov Network,MN),包含一组结点,每个结点都对应着一个变量或一组变量,边都是无向的,不含有箭头。
3.1 条件独立性
a、b、c、d、e、f是互无交集的集合,集合之间的路径是这样定义的:比如说a与c之间的路径是a中的结点途经结点集Δ中的某结点最后到达c中的结点。MRF中有下面三种情况:
(1)全局马尔可夫性:图①中,若a到c的路径中途径的结点至少有一个存在于b,则a⊥c|b;
(2)局部马尔可夫性:图②中,a⊥(全部结点-a-a的邻居),即a⊥{e,f}|{b,c,d};
(3)成对马尔可夫性:记x-i-j为去掉xi、xj后的其他结点,则xi⊥xj|x-i-j。
3.2 因子分解
首先给出无向图中的团与最大团的定义:无向图中任何两个结点均有边连接的结点子集称为团。若C是无向图G的一个团,并且不能再加进任何一个G的结点使其成为一个更大的团,则称此C为最大团。
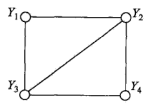
上图表示由4个结点组成的无向图。图中由2个结点组成的团有5个:{Y1,Y2},{Y2,Y3},{Y3,Y4},{Y4,Y2}和{Y1,Y3}。有2个最大团:{Y1,Y2,Y3}和{Y2,Y3,Y4}。而{Y1,Y2,Y3,Y4}不是一个团,因为Y1和Y4没有边连接。
将无向图模型的联合概率分布表示为其最大团上的随机变量的函数的乘积形式的操作,称为无向图模型的因子分解。
设无向图为G,Ci为G上的最大团,最大团的数量一般不唯一,设最大团有k个,即最大团为C1,C2,…,Ck,xCi表示最大团Ci对应的随机变量,则无向图模型的联合概率分布P(x)可写作图中所有最大团C上的函数φ(xCi)的乘积形式,即:
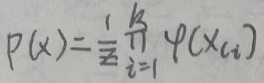
其中,z是规范化因子,由下面的公式给出:
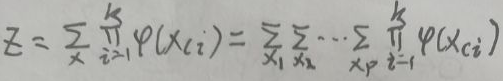
规范化因子保证P(x)构成一个概率分布。函数φ(xCi)称为势函数。这里要求势函数φ(xCi)是严格正的,通常定义为指数函数:φ(xCi)=exp{-E(xi)},up主说E为能量函数,不知道是啥,以后用到的话可能会补充。
Hammersley-Clifford定理:无向图模型的联合概率分布P(x)可以表示为如下形式:
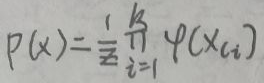
其中,z是规范化因子,由下面的公式给出:
其中,Ci是无向图的最大团,最大团的数量一般不唯一,设最大团有k个,即最大团为C1,C2,…,Ck,xCi是最大团Ci的结点对应的随机变量,φ(xCi)是Ci上定义的严格正函数,乘积是在无向图所有的最大团上进行的。
马尔可夫随机场⇔Gibbs分布,二者等价。
4 Inference
4.1 总体介绍
4.1.1 推断即求概率
Inference即推断,简单来说就是求概率——边缘概率、条件概率、最大后验概率。概率图中的所有结点都对应着某一个随机变量,记x为随机变量集,x∈Rp,记x=(x1,x2,…,xp),将x分为未知的随机变量集xA和已知的观测变量集xB,即x=xA∪xB,给定联合分布p(x)=p(x1,x2,…,xp),求下面三种概率:
(1)边缘概率:p(xi)=Σx1Σx2…Σxi-1Σxi+1…Σxpp(x);
(2)条件概率:p(xA|xB);
(3)最大后验概率MAP:z=arg max p(z|x),其中z是一个离散序列,z=(z1,z2,…,zm)。其中由条件概率公式p(z|x)=p(z,x)/p(x),而MAP是主要求z而不是求概率,因为p(x)与z无关,所以z=arg max p(z,x)。
4.1.2 分为两类
4.1.2.1 精确推断
(1)VE,Variable Elimination,即变量消除;
(2)BP,Belief Propagation,即信念传播(或称Sum-Product Algorithm),是针对树结构的概率图的算法;
(3)Junction Tree Algorithm,即联合树算法,是针对普通的图结构的概率图的算法。
4.1.2.2 近似推断
(1)LBP,Loop Belief Propagation,即循环信念传播,是针对有环图结构的概率图的算法;
(2)Monte Carlo Simulation Inference,即蒙特卡洛推断,包括Importance Sampling(重要性采样)、MCMC(Markov Chain Monte Carlo,即马尔科夫链蒙特卡洛方法)等;
(3)Variational Inference,即变分推断。
4.2 Variable Elimination
VE,Variable Elimination,即变量消除。直接举栗:给定下图(是一条马氏链),求p(d):
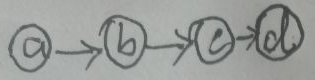
假设a、b、c、d是离散的二值随机变量,可取{0,1}中的其中一个值,则:
P(d)=Σa,b,cP(a,b,c,d)=Σa,b,cP(a)·P(bla)·P(clb)·P(dlc)=
P(a=0)·P(b=0la=0)·P(c=0lb=0)·P(d|c=0)+
P(a=1)·P(b=0la=1)·P(c=0lb=0)·P(dlc=0)+…+
P(a=1)·P(b=1la=1)·P(c=1lb=1)·P(d|c=1)。
即p(d)是8个因子积的和,8是这样来的——有4个变量a、b、c、d,每个变量有两种取值,对a、b、c三个变量的所有可能取的值求和,所以23=8。若变量有p个,若要对这p个变量的所有可能取的值求和,而每个变量可取k个值,则需要求kp个因子积的和。很明显,进行了多次的重复运算。现在对P(d)=Σa,b,cP(a,b,c,d)=Σa,b,cP(a)·P(bla)·P(clb)·P(dlc)做这样的运算:

简单来说上图运用的就是乘法对加法的分配律,通过一步步对变量的消除,简化了运算,也同时省去重复计算的时间。
4.3 VE to BP
本节主要讨论从VE到BP的过渡。
Belief Propagation算法适用于树结构的图,树中的边是无向的。下面是一颗树的示例:
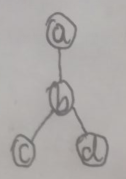
则a、b、c、d的联合概率可表示为:
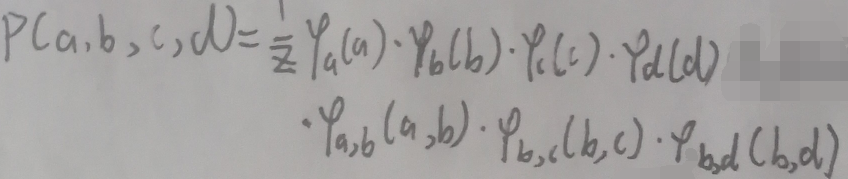
使用下面的方法(去掉了归一化因子1/z)求p(a):

上图的mb→a(a)可以写成:
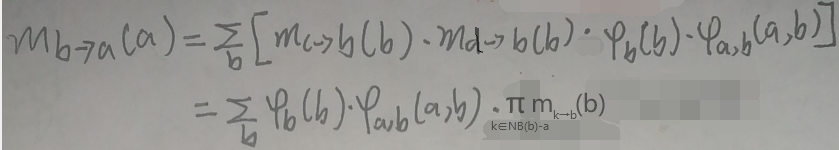
上图右下角的k∈NB(b)-a是这样的:k取【除去结点a后的b的邻接点(NB,neighbor)】,也就是取b的邻接点但是不包括a。
不失一般性,将结点a、b看作结点i、j,用xi、xj表示结点i、j对应的随机变量,则mj→i(xi)为:
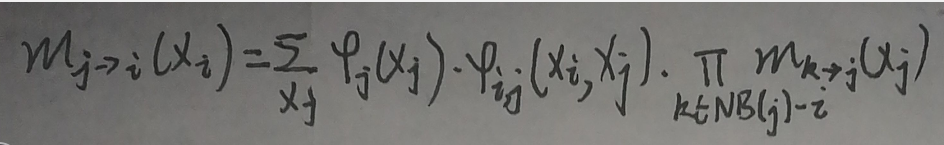
则p(xi)为:
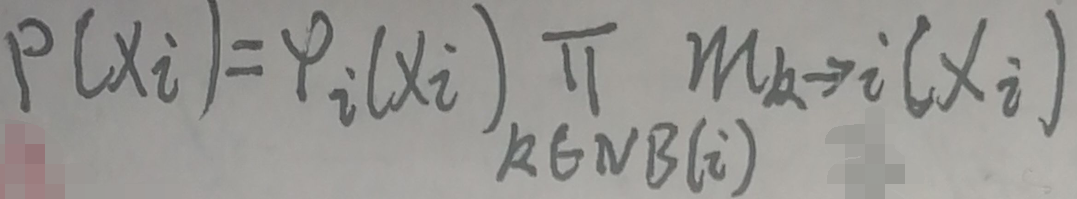
其中k∈NB(i)指k取结点i的邻接点。上面两个图片中的公式就是变量消除法(VE,Variable Elimination)在无向图中的计算公式。求边缘概率p(xi)的主要工作就是求各种mj→i(xi)。
4.4 Belief Propagation
我重写了一遍上一节的倒数第二张图片,如下:
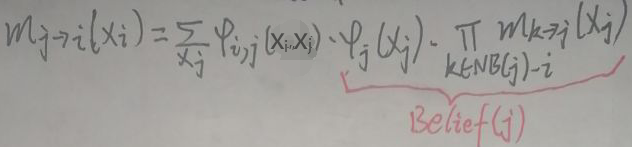
Belief Propagation算法将上图标红的部分称为Belief,Belief(j)表示结点j能从自己的子结点中接受的信念(即信息),则mj→i(xi)为:
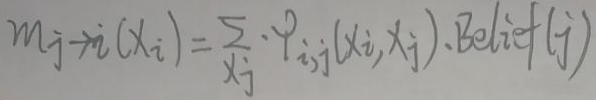
mj→i(xi)指结点j到结点i传递的信念(即信息)。
简单来说,Belief Propagation算法就是【Variable Elimination算法】+【Catching】,Catching指计算mj→i(xi)并且记录结果。BP通过求必要的mj→i(xi)去求边缘概率p(xi)。BP的算法过程如下:
(1)任选一个结点作为Root结点;
(2)收集信息:对于Root结点的所有邻接点i对应的随机变量xi,收集所有xi的信息即计算mj→i(xi),结点j为结点i的所有邻接点(除去结点i),xj是邻接点j(除去结点i)对应的随机变量;
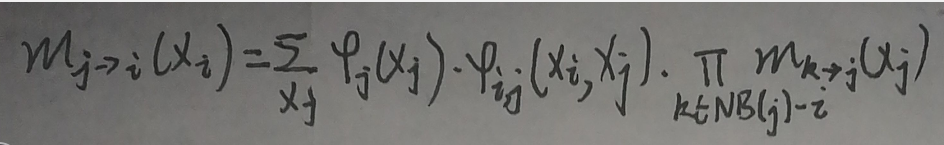
(3)分发信息:对于Root结点的所有邻接点i,计算mi→j(xj),结点j为结点i的所有邻接点(除去结点i),xj是邻接点j(除去结点i)对应的随机变量。
算法结束后,就可以得到所有的mj→i(xi),结点i、结点j属于整个图中的所有结点的集合,而x∈Rp,记x=(x1,x2,…,xp),便可以求出边缘概率p(xi),i=1…N。
4.5 Max Product
BP又称为Sum-Product算法,而Max Product算法是对BP的改进,修改上一节的mj→i(xi)的求和符号Σ为max,其他保持不变:
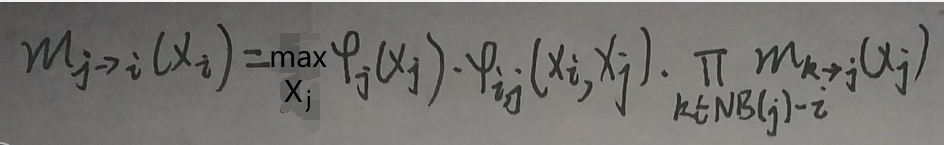
直接举例,如下图:
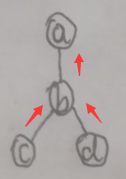
上图与【4.3 VE to BP】一节的第一张图片完全一致,只是加了三个箭头——这是为了方便计算,所以先假定一个信息传递的次序,即信息传递次序为:【c→b、d→b、b→a】,因此需要求【mc→b(xb)、md→b(xb)、mb→a(xa)】,按照本节第一张图片的公式计算如下:
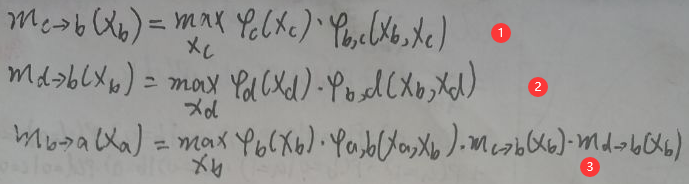
则:
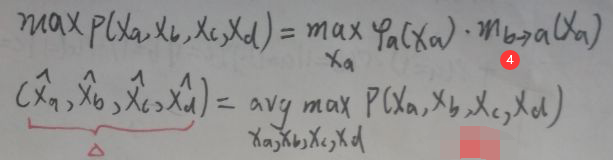
上图左下角的Δ是变量xa,xb,xc,xd的一个序列,这个序列使得联合概率P(xa,xb,xc,xd)最大,求这个序列的方法就是取上面两张图片中的①②③④式中各自使后面函数的值最大时的xi。
5 Factor Graph
Factor Graph即因子图。将一个具有多变量的全局函数进行因子分解,可以得到几个局部函数的乘积,以此为基础得到的图叫做因子图。
因子图是一类无向概率图模型,包括变量节点和因子节点。变量节点和因子节点之间有无向边相连。与某个因子节点相连接的变量节点,为该因子的变量。定义在因子图上的联合概率分布可以表示为各个因子的连乘积,若x∈Rp,则p(x)=p(x1,x2,…,xp)=πsf(xs),其中s为图中全部结点的结点子集,xs是结点集s对应的随机变量集,f(xs)为随机变量集xs的函数,称其为因子,因此πsf(xs)是所有因子的连乘积。
需要强调的是因子图不是唯一的,如下无向概率图①:
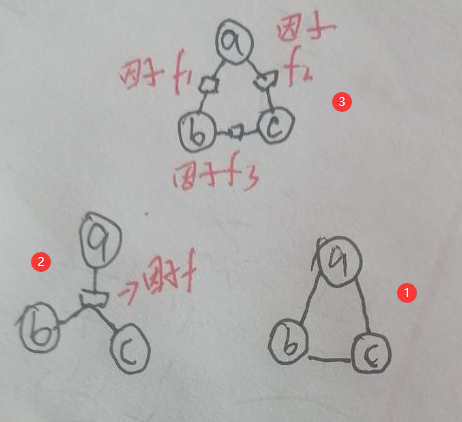
图①为原概率图,图②、图③为图①的两个因子图:
(1)图②:p(x)=f(xa,xb,xc);
(2)图③:p(x)=f1(xa,xb)f2(xa,xc)f3(xb,xc)。
6 Moral Graph
为了把有向图转化为无向图,引入了道德图(Moral Graph)。
6.1 局部图的转换
对于【2.1 条件独立性】一节第二张图片中的三种局部图(图③去掉了结点d):
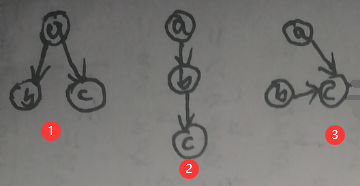
进行如下转换:
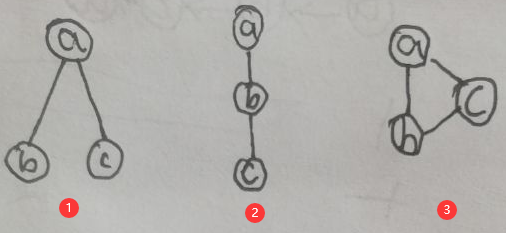
下面进行详细说明:
(1)有向图①中,对于a来说是tail to tail:p(a,b,c)=p(a)p(b|a)p(c|a),其中p(a)p(b|a)可以看作φ(a,b),p(c|a)可以看作φ(a,c),即a、b与a、c分别构成无向图中的最大团,即无向图①;
(2)有向图②中,对于b来说是head to tail:p(a,b,c)=p(a)p(b|a)p(c|b),其中p(a)p(b|a)可以看作φ(a,b),p(c|b)可以看作φ(b,c),即a、b与b、c分别构成无向图中的最大团,即无向图②;
(3)有向图③中,对于c来说是head to head:p(a,b,c)=p(a)p(b)p(c|a,b),只能将p(a)p(b)p(c|a,b)看作φ(a,b,c),即a、b、c构成无向图中的最大团,即无向图③。
6.2 全局图的转换
将待转换的有向图记为G,将G转换为无向图的步骤为:(1)对于G中全部结点xi,xi的全部父结点构成的集合记为parent(xi),将parent(xi)中的全部结点使用无向边两两连接;(2)将剩余的有向边的箭头去掉,改为无向边即可。
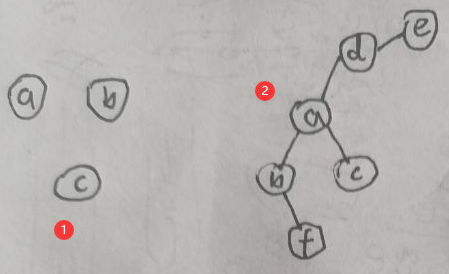
经过上述步骤,最终得到的就是一个无向图,称为道德图(Moral Graph)。下图是一个例子:

左面是有向图G,右面是转换后的道德图M(G),M(G)是无向图。
一般地,道德图M(G)与有向图G有这样的关系,比如说在M(G)中有一个separation(划分):a,b|c,则在G中有同样有一个D separation:a,b|c。即G中的划分与M(G)的划分等价。
END