此文章主要是结合哔站shuhuai008大佬的白板推导视频:sigmoid信念网络_92min
全部笔记的汇总贴:机器学习-白板推导系列笔记
对应花书19.5、20.10
一、背景介绍
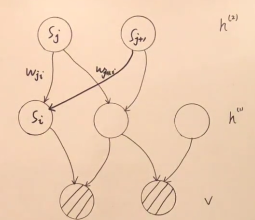
sigmoid信念网络是一种具有特定条件概率分布的有向图模型的简单形式。一般我们将sigmoid信念网络视为具有二值向量的状态 s s s,其中状态的每个元素都受其祖先的影响。
s = { s 1 , s 2 , ⋯ , s T } = { v , h } = { v , h ( 1 ) , h ( 2 ) } σ ( x ) = 1 1 + exp ( − x ) s=\{s_1,s_2,\cdots,s_T\}=\{v,h\}=\{v,h^{(1)},h^{(2)}\}\\\sigma(x)=\frac1{1+\exp(-x)} s={ s1,s2,⋯,sT}={ v,h}={ v,h(1),h(2)}σ(x)=1+exp(−x)1 1 − σ ( x ) = 1 + exp ( − x ) 1 + exp ( − x ) − 1 1 + exp ( − x ) = exp ( − x ) 1 + exp ( − x ) = 1 1 + exp ( x ) = σ ( − x ) 1-\sigma(x)=\frac{1+\exp(-x)}{1+\exp(-x)}-\frac1{1+\exp(-x)}\\=\frac{\exp(-x)}{1+\exp(-x)}=\frac1{1+\exp(x)}=\sigma(-x) 1−σ(x)=1+exp(−x)1+exp(−x)−1+exp(−x)1=1+exp(−x)exp(−x)=1+exp(x)1=σ(−x)
P ( s i = 1 ∣ s j : j < i ) = σ ( ∑ j < i w j i ⋅ s j ) P ( s i = 0 ∣ s j : j < i ) = 1 − σ ( ∑ j < i w j i ⋅ s j ) = σ ( − ∑ j < i w j i ⋅ s j ) P(s_i=1|s_{j:j<i})=\sigma(\sum_{j<i}w_{ji\cdot s_j})\\P(s_i=0|s_{j:j<i})=1-\sigma(\sum_{j<i}w_{ji\cdot s_j})\\=\sigma(-\sum_{j<i}w_{ji\cdot s_j}) P(si=1∣sj:j<i)=σ(j<i∑wji⋅sj)P(si=0∣sj:j<i)=1−σ(j<i∑wji⋅sj)=σ(−j<i∑wji⋅sj)
P ( s i ∣ s j : j < i ) = σ ( s i ∗ ∑ j < i w j i ⋅ s j ) s i ∗ = 2 s i − 1 P(s_i|s_{j:j<i})=\sigma(s_i^*\sum_{j<i}w_{ji}\cdot s_j)\\s_i^*=2s_i-1 P(si∣sj:j<i)=σ(si∗j<i∑wji⋅sj)si∗=2si−1
二、Gradient of log-likelihood
这里为了推导方便,我们没有考虑偏执 b b b。
P ( s ) = ∏ i P ( s i ∣ s j : j < i ) = P ( v , h ) P(s)=\prod_iP(s_i|s_{j:j<i})=P(v,h) P(s)=i∏P(si∣sj:j<i)=P(v,h)
log-likelihood:
∑ v ∈ V l o g P ( v ) \sum_{v\in V}log P(v) v∈V∑logP(v)
∂ ∂ w i j log P ( v ) = 1 P ( v ) ∂ ∂ w i j P ( v ) = 1 P ( v ) ∂ ∑ h P ( v , h ) ∂ w i j = ∑ h 1 P ( v ) ∂ P ( v , h ) ∂ w i j = ∑ h P ( h ∣ v ) P ( h , v ) ∂ P ( v , h ) ∂ w i j = ∑ h P ( h ∣ v ) 1 P ( s ) ∂ P ( s ) ∂ w i j \frac{\partial}{\partial w_{ij}}\log P(v)=\frac1{ P(v)}\frac{\partial}{\partial w_{ij}} P(v)\\=\frac1{ P(v)}\frac{\partial\sum_hP(v,h)}{\partial w_{ij}}\\=\sum_h\frac1{ P(v)}\frac{\partial P(v,h)}{\partial w_{ij}}\\=\sum_h\frac{ P(h|v)}{ P(h,v)}\frac{\partial P(v,h)}{\partial w_{ij}}\\=\sum_h{ P(h|v)}{\color{red}\frac1{ P(s)}\frac{\partial P(s)}{\partial w_{ij}}} ∂wij∂logP(v)=P(v)1∂wij∂P(v)=P(v)1∂wij∂∑hP(v,h)=h∑P(v)1∂wij∂P(v,h)=h∑P(h,v)P(h∣v)∂wij∂P(v,h)=h∑P(h∣v)P(s)1∂wij∂P(s)
1 P ( s ) ∂ P ( s ) ∂ w i j = 1 ∏ k P ( s k ∣ s j : j < k ) ∏ k ≠ i P ( s k ∣ s j : j < k ) ∂ P ( s i ∣ s j : j < i ) ∂ w i j = 1 P ( s i ∣ s j : j < i ) ∂ P ( s i ∣ s j : j < i ) ∂ w i j = 1 P ( s i ∣ s j : j < i ) ∂ σ ( s i ∗ ∑ j < i w j i ⋅ s j ) ∂ w i j = 1 σ ( s i ∗ ∑ j < i w j i ⋅ s j ) ⋅ σ ( s i ∗ ∑ j < i w j i ⋅ s j ) ⋅ σ ( − s i ∗ ∑ j < i w j i ⋅ s j ) s i ∗ ⋅ s j = σ ( − s i ∗ ∑ j < i w j i ⋅ s j ) s i ∗ ⋅ s j \frac1{ P(s)}\frac{\partial P(s)}{\partial w_{ij}}=\frac1{ \prod_kP(s_k|s_{j:j<k})}\frac{\prod_{k\neq i}P(s_k|s_{j:j<k})\partial P(s_i|s_{j:j<i})}{\partial w_{ij}}\\=\frac1{ P(s_i|s_{j:j<i})}\frac{\partial P(s_i|s_{j:j<i})}{\partial w_{ij}}\\=\frac1{ P(s_i|s_{j:j<i})}\frac{\partial \sigma(s_i^*\sum_{j<i}w_{ji}\cdot s_j)}{\partial w_{ij}}\\=\frac1{ \sigma(s_i^*\sum_{j<i}w_{ji}\cdot s_j)}\cdot \sigma(s_i^*\sum_{j<i}w_{ji}\cdot s_j)\cdot\sigma(-s_i^*\sum_{j<i}w_{ji}\cdot s_j)s_i^*\cdot s_j\\=\sigma(-s_i^*\sum_{j<i}w_{ji}\cdot s_j)s_i^*\cdot s_j P(s)1∂wij∂P(s)=∏kP(sk∣sj:j<k)1∂wij∏k=iP(sk∣sj:j<k)∂P(si∣sj:j<i)=P(si∣sj:j<i)1∂wij∂P(si∣sj:j<i)=P(si∣sj:j<i)1∂wij∂σ(si∗∑j<iwji⋅sj)=σ(si∗∑j<iwji⋅sj)1⋅σ(si∗j<i∑wji⋅sj)⋅σ(−si∗j<i∑wji⋅sj)si∗⋅sj=σ(−si∗j<i∑wji⋅sj)si∗⋅sj
所以,
∂ ∂ w i j ∑ v ∈ V log P ( v ) = ∑ v ∈ V ∑ h P ( h ∣ v ) σ ( − s i ∗ ∑ j < i w j i ⋅ s j ) s i ∗ ⋅ s j = ∑ v ∈ V ∑ h P ( h , v ∣ v ) σ ( − s i ∗ ∑ j < i w j i ⋅ s j ) s i ∗ ⋅ s j = ∑ v ∈ V ∑ h P ( s ∣ v ) σ ( − s i ∗ ∑ j < i w j i ⋅ s j ) s i ∗ ⋅ s j = E ( v , h ) ∼ P ( s ∣ v ) , v ∼ P d a t a [ σ ( − s i ∗ ∑ k < i w k i ⋅ s j ) s i ∗ ⋅ s j ] \frac{\partial}{\partial w_{ij}}\sum_{v\in V}\log P(v)=\sum_{v\in V}\sum_h{ P(h|v)}\sigma(-s_i^*\sum_{j<i}w_{ji}\cdot s_j)s_i^*\cdot s_j\\=\sum_{v\in V}\sum_h{ P(h,v|v)}\sigma(-s_i^*\sum_{j<i}w_{ji}\cdot s_j)s_i^*\cdot s_j\\=\sum_{v\in V}\sum_h{ P(s|v)}\sigma(-s_i^*\sum_{j<i}w_{ji}\cdot s_j)s_i^*\cdot s_j\\=E_{(v,h)\sim P(s|v),v\sim P_{data}}\bigg[\sigma(-s_i^*\sum_{k<i}w_{ki}\cdot s_j)s_i^*\cdot s_j\bigg] ∂wij∂v∈V∑logP(v)=v∈V∑h∑P(h∣v)σ(−si∗j<i∑wji⋅sj)si∗⋅sj=v∈V∑h∑P(h,v∣v)σ(−si∗j<i∑wji⋅sj)si∗⋅sj=v∈V∑h∑P(s∣v)σ(−si∗j<i∑wji⋅sj)si∗⋅sj=E(v,h)∼P(s∣v),v∼Pdata[σ(−si∗k<i∑wki⋅sj)si∗⋅sj]
精确推断无法求解,所以我们需要进行近似推断,这里需要用到的算法是醒眠算法(花书P398-19.5)。
三、醒眠算法
(一)介绍
学成近似推断是把推断视作一个函数。显式地通过迭代方法(不动点方程、基于梯度的优化)来进行优化通常代价高耗时巨大,我们通过学成一个近似推断来避免这种代价。将优化过程视作将一个输入 v v v投影到一个近似分布 q ∗ = arg max q Γ ( v , q ) q^*=\argmax_q\varGamma(v,q) q∗=qargmaxΓ(v,q)的一个 f f f的函数。一旦我们将多步的迭代优化过程看作函数,就可以用一个近似函数为 f ^ ( v ; θ ) \hat f(v;\theta) f^(v;θ)的神经网络来近似它。
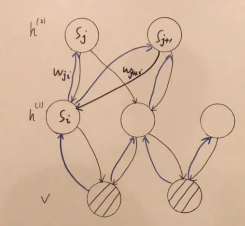
我们将正向的 W W W称为Generative Connection,将反向的 W W W用 R R R来表示,称为Recognition Connection。
醒眠算法属于学成近似推断,是一个迭代算法,每一步分为两个阶段,第一个阶段称为Wake Phase,第二个阶段称为Sleep Phase。醒眠算法并非一个严谨的算法,他是一个启发式算法,是通过引入一个Recognition Connection来近似后验分布。
Wake Phase:
- Bottom-up 从可见变量 v v v出发,激活neuron(获得各层样本)
- Learning Generative Connection(求 W W W)
Sleep Phase:
- Top-down 从最顶层出发,激活neuron(获得各层样本)
- Learning Recognition Connection(求 R R R)
(二)KL-Divergence
Generative model: p θ ( v , h ) ( θ = w ) p_{\theta}(v,h)\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;(\theta=w) pθ(v,h)(θ=w)
Recognition Generative model: q ϕ ( h ∣ v ) ϕ = R q_\phi(h|v)\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\phi=R qϕ(h∣v)ϕ=Rlog p ( v ) = E L B O + K L ( q ∣ ∣ p ) \log p(v)=ELBO+KL(q||p) logp(v)=ELBO+KL(q∣∣p) E L B O = L = E q ( h ∣ v ) [ log p ( v , h ) q ( h ∣ v ) ] = E q ( h ∣ v ) [ log p ( v , h ) ] + H [ q ] ELBO=L=E_{q(h|v)}\Big[\log\frac{p(v,h)}{q(h|v)}\Big]\\=E_{q(h|v)}\Big[\log p(v,h)\Big]+H[q] ELBO=L=Eq(h∣v)[logq(h∣v)p(v,h)]=Eq(h∣v)[logp(v,h)]+H[q]
Wake Phase:(类似于EM算法中的M步)
E q ϕ ( h ∣ v ) [ log p θ ( v , h ) ] ≈ 1 N ∑ i = 1 N log p θ ( v , h i ) E_{q_\phi(h|v)}\Big[\log p_{\theta}(v,h)\Big]\approx\frac1N\sum_{i=1}^N\log p_\theta(v,h_i) Eqϕ(h∣v)[logpθ(v,h)]≈N1i=1∑Nlogpθ(v,hi)
θ ^ = arg max θ E q ϕ ( h ∣ v ) [ log p θ ( v , h ) ] , w i t h ϕ f i x e d = arg max θ L ( θ ) \hat\theta=\argmax_\theta E_{q_\phi(h|v)}\Big[\log p_{\theta}(v,h)\Big],with\;\;\phi\;\;fixed\\=\argmax_\theta L (\theta) θ^=θargmaxEqϕ(h∣v)[logpθ(v,h)],withϕfixed=θargmaxL(θ)
Sleep Phase:(类似于EM算法中的E步)
ϕ ^ = arg max ϕ E p θ ( v , h ) [ log q ϕ ( h ∣ v ) ] = arg max ϕ ∫ p θ ( v , h ) log q ϕ ( h ∣ v ) d h = arg max ϕ ∫ p θ ( v ) p θ ( h ∣ v ) log q ϕ ( h ∣ v ) d h = arg max ϕ ∫ p θ ( h ∣ v ) log q ϕ ( h ∣ v ) d h = arg max ϕ ∫ p θ ( h ∣ v ) log ( q ϕ ( h ∣ v ) d h p θ ( h ∣ v ) ⋅ p θ ( h ∣ v ) ) d h = arg max ϕ ∫ ( p θ ( h ∣ v ) log q ϕ ( h ∣ v ) d h p θ ( h ∣ v ) + p θ ( h ∣ v ) log p θ ( h ∣ v ) ) d h = arg max ϕ ∫ p θ ( h ∣ v ) log q ϕ ( h ∣ v ) d h p θ ( h ∣ v ) d h = arg max ϕ − K L ( p θ ( h ∣ v ) ∣ ∣ q ϕ ( h ∣ v ) ) = arg min ϕ K L ( p θ ( h ∣ v ) ∣ ∣ q ϕ ( h ∣ v ) ) \hat\phi=\argmax_\phi E_{p_{\theta}(v,h)}\Big[\log q_\phi(h|v)\Big]\\=\argmax_\phi\int p_{\theta}(v,h) \log q_\phi(h|v){d}h\\=\argmax_\phi\int p_\theta(v)p_{\theta}(h|v) \log q_\phi(h|v){d}h\\=\argmax_\phi\int p_{\theta}(h|v) \log q_\phi(h|v){d}h\\=\argmax_\phi\int p_{\theta}(h|v) \log\Big( \frac{q_\phi(h|v){d}h}{p_{\theta}(h|v)}\cdot p_{\theta}(h|v)\Big){d}h\\=\argmax_\phi\int \Big(p_{\theta}(h|v) \log\frac{q_\phi(h|v){d}h}{p_{\theta}(h|v)}+p_{\theta}(h|v) \log p_{\theta}(h|v)\Big){d}h\\=\argmax_\phi\int p_{\theta}(h|v) \log\frac{q_\phi(h|v){d}h}{p_{\theta}(h|v)}{d}h\\=\argmax_\phi-KL\Big(p_{\theta}(h|v)||q_\phi(h|v)\Big)\\=\argmin_\phi KL\Big(p_{\theta}(h|v)||q_\phi(h|v)\Big) ϕ^=ϕargmaxEpθ(v,h)[logqϕ(h∣v)]=ϕargmax∫pθ(v,h)logqϕ(h∣v)dh=ϕargmax∫pθ(v)pθ(h∣v)logqϕ(h∣v)dh=ϕargmax∫pθ(h∣v)logqϕ(h∣v)dh=ϕargmax∫pθ(h∣v)log(pθ(h∣v)qϕ(h∣v)dh⋅pθ(h∣v))dh=ϕargmax∫(pθ(h∣v)logpθ(h∣v)qϕ(h∣v)dh+pθ(h∣v)logpθ(h∣v))dh=ϕargmax∫pθ(h∣v)logpθ(h∣v)qϕ(h∣v)dhdh=ϕargmax−KL(pθ(h∣v)∣∣qϕ(h∣v))=ϕargminKL(pθ(h∣v)∣∣qϕ(h∣v))
可以看出得到的KL表达式与Wake Phase所对应的KL并不相同,一个 q q q在前 p p p在后,另一个则恰好相反。原因是Sleep Phase中采用的样本并不是训练样本,而是全部都是抽样得到的生成样本。
下一章传送门:白板推导系列笔记(二十七)-深度信念网络