(一)Title
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CFuleInG-1689159806259)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230711103238551.png)]](https://img-blog.csdnimg.cn/edf407c9a53c4c69949cf283817ef095.png)
写在前面: ByteTrack作者今年3月的新作品,升级了的V2版本并不是仅仅将ByteTrack扩展到三维场景,而是在二阶段匹配的框架下,结合了JDT和TBD常用的两种基于运动模型进行匹配的方法,提出了一种新的运动匹配模式,思路新颖,在三维MOT数据集nuScence上也达到了state-of-the-art。注意该笔记是针对初稿版本!!
(二)Abstract
背景介绍
MOT的任务是estimating bounding boxes and identities of objects。从具体任务上大致有3部分工作:检测(估计对象的bounding boxes),匹配和预测(确定对象的identities),目前检测任务上的改进的主要思路还是基于当前一些SOTA的检测框架,在本文中提供了一个匹配上的改进思路。
当前方法存在的问题
随着目标运动场景的变化,其检测分数也随随着变化,目前的做法一般为obtain identities by associating detection boxes whose scores are higher than a threshold。对于分数低的bounding boxes会直接丢弃,最终导致true object misssing以及fragmented trajectories。简单来说,从检测任务到下游跟踪任务时,通常为了防止过高的False Positive,采用一个比较高的固定阈值过滤掉检测器输出的低分边界框,使得检测信息出现丢失,造成跟踪过程出现中断的情况,使得跟踪任务对检测任务的要求过高。
本文方法
提出了一种简单、有效、通用的association方法,该方法可用于二维或三维场景。对每一个检测框而不是高分检测框进行跟踪,对于low score的检测框利用他们同轨迹的相似性恢复真实目标,并过滤掉背景。将检测得到的边界框和预测结果进行二次关联,减少由遮挡产生的Fragmented trajectories和ID switch
在三维场景中,提出了一种将检测速度和Kalman Filter相结合的互补运动策略来处理短期遮挡和运动突变等情况。
实验表现
- 在相机(56.4% AMOT A)和激光雷达(70.1% AMOT A)模式上都领先于nuScenes 3D MOT排行榜。
(三)Introduction
ByteTrack
最基本的Tracking by Detection范式,由检测、运动预测和数据关联组成。首先通过目标检测器生成2D or 3D的bounding box 和置信度confidence。随后利用运动预测模块,通常是Kalman Filter,预测下一帧的轨迹位置。最后根据一定的空间相似性将检测框和轨迹的预测位置关联起来。
但是当前多目标跟踪存在着的一个难于解决的问题是:如下图中的(a)所示,当前目标检测的框架通过置信度阈值输出最终的边界框,当设置的阈值过大时,会出现missing detection以及。作者分析其原因为在将检测的bounding boxes给到data association时设置了较高的阈值,导致一些低置信度的bounding boxes信息出现丢失,而这些低置信度的bounding boxes往往包含着被遮挡的目标。

这种高阈值的设置是目前MOT中常常使用的方式,但是造成跟踪任务的missing detection的影响是不可逆的。
为了避免低分检测框信息的丢失,需要额外的解决low confidence带来的False Positive问题。因此,作者引入了二次关联,将能够同tracklets匹配上的low confidence boxes加入到tracklets中,而无法匹配的boxes视作背景,成功解决掉当前问题。
具体的实现方法为:
- 首先基于motion similarity将高置信度的detection boxes匹配到tracklets上。同样使用kalman滤波器预测当前轨迹在下一帧的位置。motion similarity的计算方式,通过计算kalman预测的boxes和low confidence boxes之间的IoU表示。
- 然后将unmatched tracklets和low confidence boxes通过IOU进行二次匹配。此时因遮挡的低置信度边界框能够得到很好地匹配,恢复身份,同时背景也能够过滤出来。
ByteTrackV2
以往基于运动预测的方法主要分为两种,一是基于速度检测,该方法在遇到不可预测的速度突变和低帧率视频时具有较好的鲁棒性,但是由于缺乏历史运动信息,该方法很难进行长期关联;二是基于Kalman Filter,该方法结合了历史信息会产生更加平滑的运动预测,但很难应对速度突变等情况
三维MOT中物体短暂的速度突变和遮挡可能会导致ID的变化。与二维场景不同,三维天然补充了深度信息,相比于二维,其运动信息更加丰富,空间相似性更容易区分物体。
Different from 2D MOT, it is easier for trackers to predict accurate velocities in the world coordinate.
不是很能理解,为什么三维可以更准确的预测其速度?
为了解决物体突然运动和短期消失的问题,作者提出了一种将检测到的物体速度和Kalman Filter相结合的互补运动预测方法。
具体的实现方法为:
通过检测器检测到的速度进行反向预测进行短期关联,这对突然运动具有更好的鲁棒性;当目标由于遮挡短期消失时,Kalman Filter通过前向预测missing object的位置可以平滑保持其位置,并在目标再次出现时关联从而恢复其身份。
这个方法很妙,利用速度预测关联往往是JDT的做法,比如centertrack等;而KF则是TBD一贯的做法,作者将JDT中比较work的思想引入到了TBD中,使KF面对复杂的运动变化更具有鲁棒性。何为反向预测,何为前向预测,具体做法将在方法论中展开介绍。
ByteTrack专注于如何利用低分数的检测框来减少数据关联策略中missing detection和 fragmented trajectories,是一个大的数据关联框架创新;而ByteTrackV2则聚焦于如何提高frame by frame 的关联质量,是一个细化的关联方法创新。在ByteTrack的基础上引入了这项互补运动预测方法,成为了ByteTrackV2,使其不仅在2D MOT中能有优秀的表现,在3D MOT中也能应对更复杂的运动环境。
本文的贡献如下:
1、Unified 2D and 3D Data Association. 将两阶段数据关联应用在2D 3D MOT中。
2、Complementary 3D Motion Prediction. 将速度预测和KF预测结合,成为一种新的互补运动预测方法。
3、Thorough Experiments on 3D MOT Benchmarks under Different Modalities. 在nuScenes上针对不同模态的输入进行详细实验,并达到了SOTA性能,证明其可行性。
(四)Related Work
主要介绍了四部分的内容,2D/3D detection 2D/3D tracking,原文写的比较详细,这里只针对部分内容进行一个概述
1、2D Object Detection
2、3D Object Detection
基于激光雷达的三维目标检测方法包含了准确的三维结构信息,精度很高,但是高成本限制了其应用。
基于相机的方法由于其低成本和丰富的上下文信息受到广泛关注,但是从2D图像进行3D感知本身就是一个ill-posed问题,因为图像本身缺乏最重要的深度信息,哪怕转换为伪深度图像,其不准确的深度信息会严重影响网络对三维空间的理解,
以视觉为中心的多视角BEV感知方法(多相机) 缩小了基于相机和基于激光雷达的性能差距,是一种主流趋势。
目前3D MOT主流的检测器使用的是激光雷达,因其能提供准确的位置信息,其次,基于图像的三维目标检测器也开始被应用,因为图像信息可以提供外观线索。
ByteTrackV2的跟踪框架与输入模态无关,因此可以对接任何形式的3D目标检测器
3、 2D Multi-Object Tracking
data association是多目标跟踪任务的核心,它首先计算轨迹同检测框之间的相似度,然后根据相似度来进行匹配。主要涉及两个核心问题:如何计算检测框和轨迹的相似度,如何根据相似度实现检测框和轨迹的匹配
4、3D Multi-Object Tracking
3D MOT与2D MOT有许多方面都类似,特别是数据关联。由于额外引入了深度信息,因此使用位置和运动线索进行关联,会得到更加准确和可靠的结果。
AB3DMOT是SORT在三维场景中的衍生,根据3D IOU进行匹配;
CenterPoint是基于CenterTrack,将基于中心点跟踪的范式扩展到了三维场景,利用预测的物体速度作为等速运动模型,在突发运动条件下具有较好的效果;
还有许多三维跟踪器都是基于二维跟踪器进行改进。
ByteTrackV2只是用了运动线索进行数据关联,方便用同一个框架进行2D和3D的MOT。
(五)Method
ByteTrack pipeline,终于来了,仅仅是针对二阶段匹配的官方流程图:
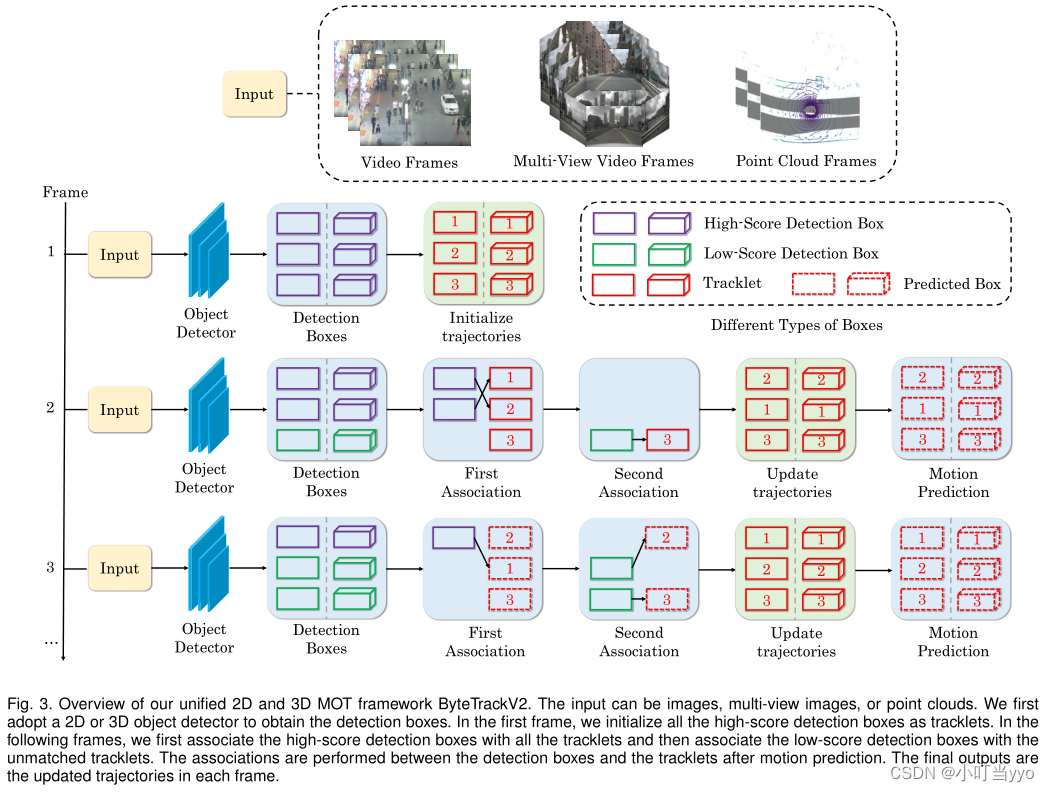
1、Preliminary
作者采用anchor-free的YOLOX作为2D MOT的detector
目前很多2D MOT算法都是采用这个检测器,当然不同的训练技巧对最后的结果影响也很大,ByteTrack系列就是针对不同数据集都精心设计了不同的训练技巧以此达到了一个SOTA的成绩。
使用基于BEV的多相机目标检测器PETRv2。
不了解这个检测器,好像是旷视去年的作品。作者提到该检测器是基于transformer架构的,并且利用了前一帧的时间信息来提高检测性能,因此也能预测速度
使用了Center-Point和TransFusion-L作为基于激光雷达的目标检测器
前者是YOLO同期作品centernet在3D场景中的衍生,后者是22年CVPR上的作品,简单了解了一下是基于transformer架构处理Lidar-Camera Fusion的目标检测器
==注意:==由于该跟踪框架通用性强,本身与输入模态无关,与对接的检测器无关,因此本人并没有深入去了解这些detector,有兴趣可以去了解学习一下近几年来的比较流行的感知算法。
使用恒速运动Kalman Filter和线性观测模型作为基本运动模型。
在二维场景中,定义状态向量为 ( u , v , a , b , u ˙ , v ˙ , a ˙ , b ˙ ) (u,v,a,b,\dot{u},\dot{v},\dot{a},\dot{b}) (u,v,a,b,u˙,v˙,a˙,b˙),其中 P 2 d = ( u , v , a , b ) P^{2d}=(u,v,a,b) P2d=(u,v,a,b)表示二维检测框的中心点坐标、长宽比、边界框高度; V 2 d = ( u ˙ , v ˙ , a ˙ , b ˙ ) V^{2d}=(\dot{u},\dot{v},\dot{a},\dot{b}) V2d=(u˙,v˙,a˙,b˙)表示对应的变化速度。
在三维场景中,定义状态向量为 ( x , y , z , θ , l , w , h , x ˙ , y ˙ , z ˙ ) (x,y,z,\theta,l,w,h,\dot{x},\dot{y},\dot{z}) (x,y,z,θ,l,w,h,x˙,y˙,z˙),其中 P 3 d = ( x , y , z ) P^{3d}=(x,y,z) P3d=(x,y,z)表示三维检测框的中心点坐标, ( l , w , h ) (l,w,h) (l,w,h)表示边界框的长宽高、 θ \theta θ表示检测框的偏航角度; V 3 d = ( x ˙ , y ˙ , z ˙ ) V^{3d}=(\dot{x},\dot{y},\dot{z}) V3d=(x˙,y˙,z˙)表示中心点对应的变化速度。
Different from [7], we define the state space in the 3D world coordinates to eliminate the effects of ego-motion.
原文当中这句话没看懂,可能是太久没看AB3DMOT了,下次重新读一下之后来更新解释
2D和3D跟踪场景中第 t + 1 t + 1 t+1帧的运动预测过程可表示为:
P t + 1 2 d = P t 2 d + V t 2 d P^{2d}_{t+1}=P^{2d}_{t}+V^{2d}_{t} Pt+12d=Pt2d+Vt2d
P t + 1 3 d = P t 3 d + V t 3 d P^{3d}_{t+1}=P^{3d}_{t}+V^{3d}_{t} Pt+13d=Pt3d+Vt3d
最后由Kalman Filter的更新步将检测和预测框进行融合更新,作为当前帧的轨迹。
2、Complementary 3D Motion Prediction
该节中提出了一种互补的三维运动预测策略,以解决驾驶场景中的突然运动和短期物体消失问题。具体而言,作者采用检测速度进行短期关联,卡尔曼滤波进行长期关联。
做MOT的都很熟悉卡尔曼滤波来进行运动预测这个套路了,在开始前,回顾一下怎么利用预测速度进行运动预测
举CenterTrack来说明,有三个输入分支,分别是当前帧/上一帧的RGB图像、前一帧目标中心分布的heatmap,有四个输出分支,分别是Heatmap、Confidence、Height&Width以及Displacement Prediction,其中最后一个输出分支输出的就是当前帧相对于前一帧的速度,通过预测的速度回溯到前一帧目标可能存在的位置,并根据相似程度进行关联。
这是一个很经典的JDT跟踪器,由于只是预测两帧间的速度,所以用这个方法更多侧重于帧与帧之间的关联,很难形成长期的关联和依赖,哪怕是短时遮挡也很容易造成ID switch,这也是基于速度预测的运动模型的缺点。
在三维场景中,得益于一些检测器的发展,能够通过时间建模准确预测短期速度,可以很好应对速度突变,在短期关联上很有优势;而卡尔曼滤波通过基于历史信息的状态更新对平稳的长期速度进行建模,有利于在丢失检测后也能平滑维持轨迹的状态。因此,作者通过双边预测策略最大化了两种运动模型的优势。
1、采用卡尔曼滤波进行前向预测,前向预测用于丢失轨迹的长期关联;
2、采用检测到的物体速度进行后向预测,后向预测负责存活轨迹的短期关联;
前向预测:Kalman Filter的预测步是基于当前时刻的后验状态,通过运动方程预测下一时刻的先验状态,预测的是未来的状态,因此称之为前向预测;
反向预测:基于检测器的速度预测(如CenterTrack)是输入t帧和t-1帧的图像信息,来预测两帧之间目标的位移量,也就是速度;注意,这里的速度是由t-1帧到t帧产生的,因此可以通过这个速度,把t时刻产生的这个检测回溯到t-1时刻的位置,因此称之为反向预测;
假设在 t t t时刻有 M M M个检测目标 D t ∈ R M × 7 D^t\in{R^{M\times7}} Dt∈RM×7以及在 x , y x,y x,y方向上他们的速度为 V t ∈ R M × 2 V^t\in{R^{M\times2}} Vt∈RM×2。通过反向预测 t − 1 t-1 t−1时刻的位置可以描述为:
D x t − 1 ^ = D x t − V x t \hat{D^{t-1}_x}=D^{t}_x-V^{t}_x Dxt−1^=Dxt−Vxt
D y t − 1 ^ = D y t − V y t \hat{D^{t-1}_y}=D^{t}_y-V^{t}_y Dyt−1^=Dyt−Vyt
假设在 t − 1 t-1 t−1时刻有 N N N条轨迹 T t − 1 ∈ R N × 7 T^{t-1}\in{R^{N\times7}} Tt−1∈RN×7,根据上文公式,通过卡尔曼滤波前向预测后,t时刻的位置为:
T x , y , z t = T x , y , z t − 1 + T ˙ x , y , z t − 1 T^t_{x,y,z}=T^{t-1}_{x,y,z}+\dot{T}^{t-1}_{x,y,z} Tx,y,zt=Tx,y,zt−1+T˙x,y,zt−1
在双边预测之后,使用ByteTrack中提到的二阶段匹配。在第一个高分关联中,反向预测的检测结果 D t − 1 D^{t-1} Dt−1和轨迹 T t − 1 T^{t-1} Tt−1之间的相似度矩阵 S t ∈ R M × N S_{t}\in{R^{M\times N}} St∈RM×N可以由以下公式计算
S t ( i , j ) = G I O U ( D i t − 1 , T j t − 1 ) S_{t}(i,j)=GIOU(D^{t-1}_i,T^{t-1}_j) St(i,j)=GIOU(Dit−1,Tjt−1)
当前帧检测和轨迹的相似度,来源于检测反向传播到前一帧的位置和前一帧轨迹的GIOU。
作者用的是GIOU,原因是因为三维场景目标运动速度较大或者帧率较低,相邻两帧同一目标的IOU较小甚至为0,可能会被直接过滤掉导致错误关联
最后还是利用匈牙利算法对相似度矩阵进行分配。在成功关联后,利用匹配的t帧检测和轨迹t帧的前向预测结果按照卡尔曼更新步骤进行更新。
当轨迹丢失的时候,只利用前向预测,较为“平滑”的更新保留轨迹的位置,以便观测出现时的重新关联,这一步骤作者称为“rebirth”(其实就是遮挡后的身份恢复)
在第二阶段的匹配中,也就是低分检测和未关联上的轨迹进行匹配,关联的方法遵循第一阶段匹配的方法。
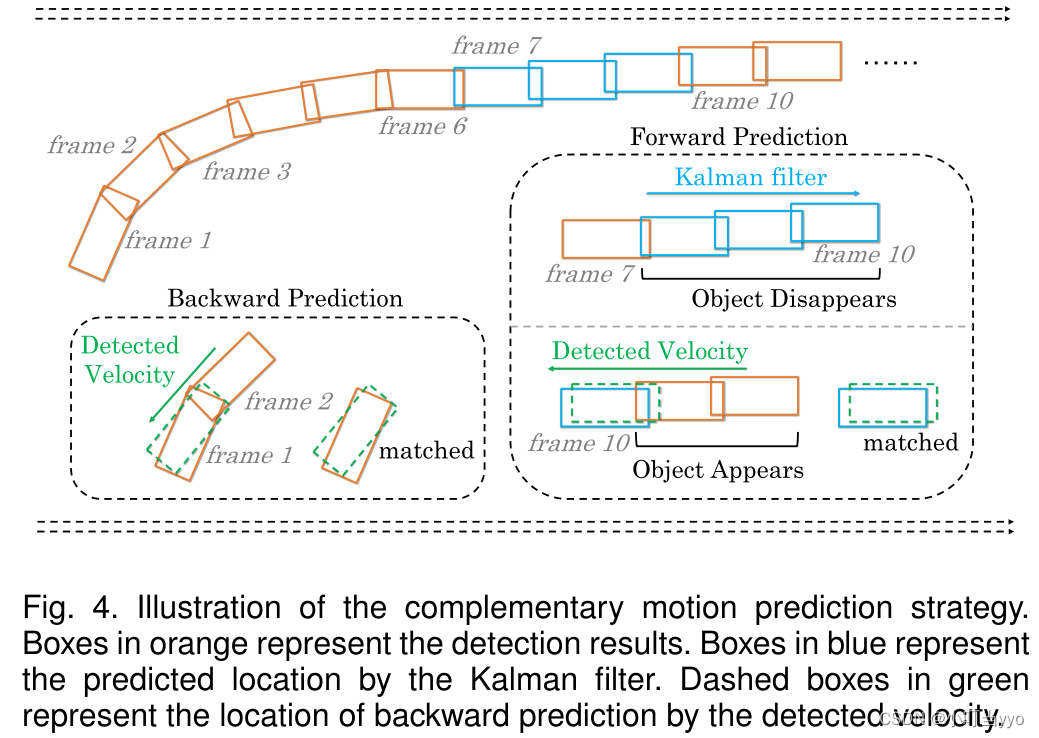
通常做法中判断检测属于哪个ID,是通过计算检测和轨迹KF预测的相似度进行分配的。
而ByteTrackV2中,作者给出判断当前帧检测属于哪个id的方法,就是通过速度反向预测该观测在前一帧中的位置,看与哪个轨迹的GIOU最大,就把该轨迹的id赋给该观测,然后通过KF的更新步,将该观测和该轨迹的t时刻KF预测结果进行更新;
说白了,KF的前向预测每一帧都进行,当运动场景简单,无遮挡情况下,KF预测结果只作更新使用;若出现遮挡等情况,KF前向预测的作用就是为了暂时延续该轨迹;
另外,作者受到GIAOTracker中NSA Kalman的启发,将检测分数融合进卡尔曼更新步骤中,自适应更新卡尔曼滤波中观测协方差矩阵R:
R t j ^ = α ( 1 − s t j ) 2 R t j \hat{R^j_t}=\alpha(1-s^j_t)^2R^j_t Rtj^=α(1−stj)2Rtj
将检测分数带入不确定性矩阵,使KF滤波对不同质量的检测具有更强的鲁棒性
3、Unified 2D and 3D Data Association
实现过程与ByteTrack类似:
首先,使用所有的检测框,将检测框分为高分检测框和低分检测框。 t时刻,基于高分检测框匹配已有的轨迹,对于当前没有边界框能够匹配得上的轨迹,分析原因是occlusion或者motion blur产生的low confidence的边界框 将低置信度的匹配框同未匹配轨迹进行二次匹配,恢复低置信度边界框,同时将背景过滤掉
对应伪代码实现过程:

这里注意几个细节:
- Track rebirth: 轨迹丢失检测后最多保留30帧,超过即删除
- Track birth: 在第一次关联中,未匹配上的高分检测框,作为新生目标,初始化为新的轨迹
作者解释了二阶段关联这个框架 比较work的原因是因为当遮挡发生的时候,往往检测分数会下降,高分检测框代表着那些未被遮挡的目标,因此要先将他们进行匹配。如果有tracklet不匹配任何的高分框,则极有可能该轨迹被遮挡,检测分数对应下降,因此在第二阶段关联中,要把低分框和这些未匹配上的tracklet进行匹配,以此来跟踪被遮挡的目标。对于低分的FP,因为没有轨迹与之匹配,也相应的被过滤掉。
(六)DATASETS AND METRICS
这部分主要讲了使用的数据集和评价指标。
主要使用的数据集为:
MOT17 dataset
MOT20 dataset
HiEve dataset
BDD100K dataset
nuScenes dataset
具体训练细节可以参照原文,这里不多说明
(七)EXPERIMENTS
7.1 Implementation Details
介绍了2D和3D的训练方法和超参数设置
比较有意思的是,作者针对不同的数据集都设计了不同的训练技巧用于刷榜。具体操作可以看原文,这里不多介绍。
7.2 2D MOT
这部分与ByteTrack内容一样,所谓ByteTrackV2在2D MOT中的应用,就是ByteTrack
7.2.1 Ablation Studies
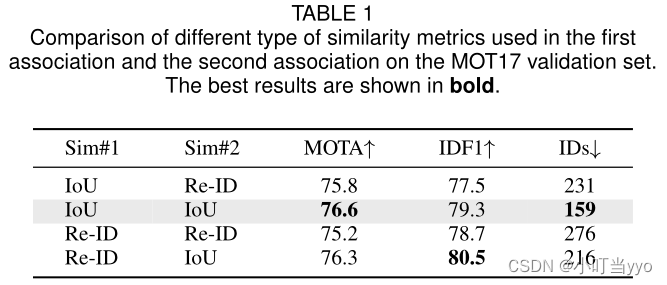
- Similarity analysis
二阶段匹配中每个阶段使用的相似性度量,发现在高分框的第一次匹配中,使用IOU和Re-ID都能获得不错的效果,IOU更有利于MOTA,而Re-ID更有利于IDF1;而在第二次对低分框进行匹配中,使用IOU效果更好,原因在于遮挡情况下,Re-ID提取到的外观特征并不可靠。
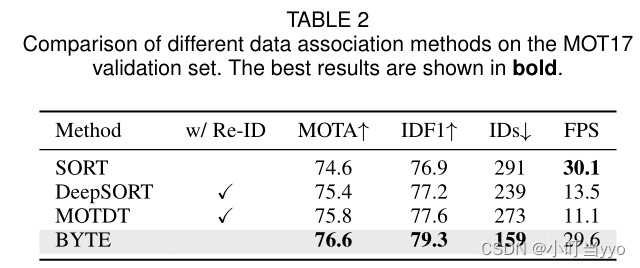
- Comparisons with other association methods
比较了二阶段关联Byte和其他关联算法,发现Byte在精度和速度上都很有优势;说明在检测精度足够高的情况下,仅仅用IOU也能获得不错的效果
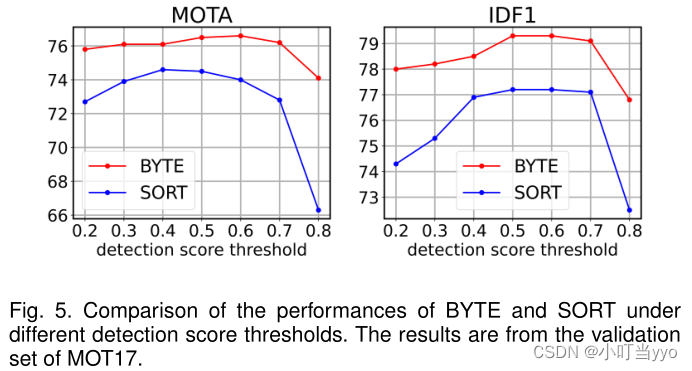
- Robustness to detection score threshold
Byte对检测阈值变化的鲁棒性更强,因为Byte恢复了低分检测框匹配的权力,可以恢复更多因遮挡产生的漏检
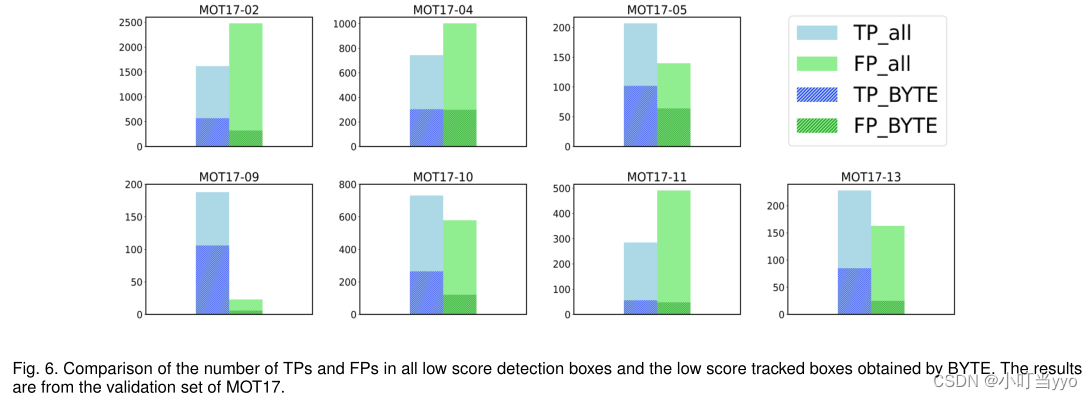
- Analysis on low score detection boxes
可以看到Byte能在低分检测框中恢复更多的TP,而不会引入更多的FP
7.2.1 Benchmark Evaluation
MOT 17
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vpMKzdHw-1689159806263)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230712155743030.png)]](https://img-blog.csdnimg.cn/9c63a5f13e3f4708a3b3ec29674d06f1.png)
MOT 20
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ffeB4zTe-1689159806263)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230712155804494.png)]](https://img-blog.csdnimg.cn/2a4a7e7336cc465099dcec5fa35ccec3.png)
HiEve
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rjswQrLx-1689159806264)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230712155901906.png)]](https://img-blog.csdnimg.cn/4eb9272b3e9e4415825d9d8908f7e585.png)
BDD100K
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5xmdrUOl-1689159806264)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230712155956172.png)]](https://img-blog.csdnimg.cn/0bb7f264def343038422ceb7a0d0537d.png)
作者还给了具体的可视化结果,对于严重遮挡的低分检测目标,Byte依旧能够成功关联其身份信息,大大减少了FN和ID switch。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NT55TDqX-1689159806264)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230712160234839.png)]](https://img-blog.csdnimg.cn/c1d3995a10364e8fb79bfcdb1f1d3608.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6w80lZhm-1689159806264)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230712160246026.png)]](https://img-blog.csdnimg.cn/6ddd4f41908b4cfe89dd21bb2759359f.png)
7.3 3D MOT
7.3.1 Ablation Studies
- Complementary motion prediction
可以看到在相机模式下和激光雷达模式下,KF 和DV的差距不同,说明了激光雷达下可以得到更加准确的检测结果,有利于KF滤波器得到更准确的估计;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NDcDDItl-1689159806265)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230712160602367.png)]](https://img-blog.csdnimg.cn/76ec3d73ec5a4529a66d291e89180872.png)
- Data association strategy
说明二阶段关联算法Byte在三维场景下的可行性,并且不需要考虑不同的输入模态
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I4Mxah0Y-1689159806265)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230712162158639.png)]](https://img-blog.csdnimg.cn/410be2b7d1ac4642a45b689959d1dca7.png)
- Hyperparameter search
检测分数的阈值和GIOU匹配分数阈值的消融实验。
从图8左边看到由于AMOTA对对象的召回率要求比较高,所以检测分数阈值越低,AMOTA越高;然而降低检测分数阈值会带来大量错误关联,从而影响跟踪性能,通过网格搜索,发现基于Camera的最佳阈值为0.25,基于Lidar的最佳阈值为0.2;右边观察到无论是Camera还是Lidar匹配分数阈值在0.5左右AMOTA最高
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LBfVuPbK-1689159806265)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230712162402223.png)]](https://img-blog.csdnimg.cn/b5b386676ed841d08b6c728aa51c7a27.png)
7.3.1 Benchmark Evaluation
在nuScenes上分别使用Camera和Lidar对其验证集和测试集进行性能测试
Camera modality
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gsOSmT7W-1689159806265)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230712163226603.png)]](https://img-blog.csdnimg.cn/aab57600db3d4363a1cdfdc0c7cb1f8b.png)
LiDAR modality
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dnazscwv-1689159806266)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230712163327777.png)]](https://img-blog.csdnimg.cn/f7723fdc9d2145e5a84245c7a2c799d3.png)
(七)Conclusion
本文在二维场景中ByteTrack基础上,扩展到三维场景,并提出了一种基于速度预测和卡尔曼滤波预测融合的互补运动预测策略,在二维和三维的不同数据集上都能到达SOTA指标。该算法对遮挡环境比较鲁棒,并且可以对接不同模态的检测器输入。
本文的思路:
首先分析了通常算法会设置一个较高的检测阈值来过滤掉不可靠的检测,以减少False Positive。但这种做法实则是舍弃low confidence对应的occluded objects,这种做法是不可逆的,相当于在后续跟踪过程中无法将这些the occluded objects与tracklets进行关联,从而导致missing detection以及fragmented trajectories,同时由于没有检测的更新,KF参数也会随着遮挡时间的增加而发散,导致遮挡结束后依然会发生错误关联。
接着,考虑使用low confidence的boxes用于数据关联。但同时也要思考如何解决引入低置信度带来的false positive问题。
最后提出二阶段匹配的关联模式,第一次采用高置信度的boxes匹配tracklets(高置信度是为了避免引入背景),接着将low confidence的box与一阶段中未匹配的tracklets进行匹配(unmatched tracklets可能是因为目标被遮挡而得到了一个low confidence),同时由低分检测引入的背景因没匹配的轨迹也将被过滤。
在三维场景中,考虑了目标可能容易出现运动突变或者帧率较低等情况,除了使用KF预测以保持轨迹的长期运动信息外,还结合了JDT模式中的速度预测,用于短期的数据关联,作者称之为互补运动预测。