文章目录
写在前面
这篇文章发布于2017年Arxiv,并没有正式得发出去。写了这么多关于聚类得文章,我发现以前没有把注意力转移到聚类得原理上面,深入剖析聚类得内部原理,所以从这篇文章开始,我将围绕“如何聚类“来展开文章。
0. 摘要
- 1.说呀,现在在聚类领域有个很流行的假设:数据是从一个低维的非线性流型单元中产生的(生成模型),所以聚类就是将这些流型分开。
- 2.MIXAE包括两部分:{自编码器的集合(K个),概率分配网络},然后同时优化这两部分,将数据分配给它所属的簇,从而学习到每个簇的流型。

1. 介绍
- 理想情况下,每个自编码器都会对应一个特定的簇。作者定义了一个损失函数用来联合优化自编码器和概率分配网络,还说这种方式在很多其他的无监督模型上表现也很好。
- 这种方式的主要优点在于把聚类和表示学习相互结合起来可以减小模型的复杂度并且提高模型的表达能力,即隐向量允许较小的神经网络来进行分类,并且可以通过聚类来得到良好的分离。
- 文章的主要贡献:模型结构、LOSS、实验


2. 相关工作
- 这一段提到了三个模型,我都写了博客,这一段指出了DEC、VaDE、GMVAE都需要非常谨慎的对模型的参数进行初始化,并且在训练开始前,就已经展现出很好的分离效果。
- 相反,MIXAE模型从一开始就随机初始化(From scratch)

3. 用MIXAE来聚类
- 下面就要开始介绍作者提出的模型了,并且给出了模型结构和目标函数的直观理解。

3.1 自编码器
- 不讲,略
3.2 MIXAE模型
- 我们的目标就是将数据X聚成K类,因此我们假设每个簇中的数据是从不同的低维流型中采样出来的。
- 概率分配是由额外的网络来完成的,它推理出类别标签

- 这里其实存在一个很大的漏洞:
理论上,我们是希望数据集经过概率分配网络后,不同类别对应不同的softmax最大值的位置,我们如何确保这一点,作者并没有提,作者在本篇文章中只是确保了softmax值偏向于one_hot向量,确保了在一个batch中对每个自编码器的选择是平均的。或许如果数据本身就有很明显的类别区分,softmax值也会对用不同的最大值,需要调参数来解决这个问题。当然这只是我的一些思考。

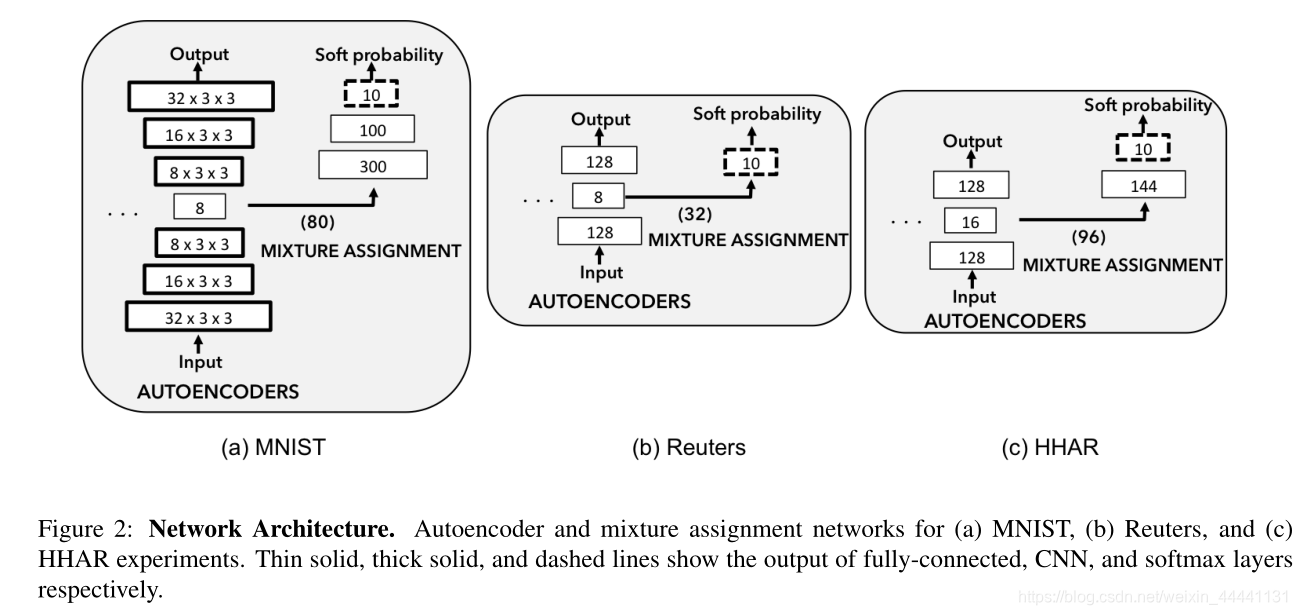
- 下面是模型结构图,看这图解释损失函数会好一些。

- 下面介绍损失函数的三个项,第一项:加权重构项
这里用的是平方损失,直观上看,当模型达到最优值时,概率分配向量会变成one_hot向量,表示该样本是从某一个自编码器中产生的。这样说太抽象,举个例子:
以MNIST数据集为例,假设模型快训练好了,但是还差几个epochs,现在有一个样本”2“作为input进入模型,产生了p_vector=[0.01,0.01,0.01,0.01,0.90,0.02,0.01,0.01,0.01],这样模型在第5个自编码器产生的重构误差会很大,对第五个自编码器的参数更新也会比其他AE大,即对于该样本,模型选择从第5个AE中产生。


- 样本熵项
保证p_vector是一个one_hot向量,即保证某个样本是从某一个AE中产生的。

- Batch-wise entropy
其实,这一项损失是与样本熵矛盾的,这一项损失是让样本均匀的去选择哪一个AE,避免样本熵损失造成的局部解,即无论什么样本都会去选择固定的一个AE。所以需要给他们分别加上系数来调和其中的矛盾,这也是实验的一大难点,调节超参数。

- 整合三项得到损失函数
- 实验表明动态的改变超参数α和β比静态的表现好。
- 参数调节过程:首先我们应该最优化batch wise entropy 和 sample-wise entropy,避免局部最优解;然后重点优化重构损失和sample-wise entropy。
- 实践中,在训练初期选择比较大的α和β值,随着训练的进行,我们调节两个超参数值来让三项损失近似相等。(这里优点不太懂,文中解释的也不太清楚)

4. 实验
- 挑重点的讲
4.1 评估指标
- 这个评估指标经常在聚类中出现,非常有必要说一下,核心是Hungarian algorithm算法来解决真实标签和聚类标签之间的映射

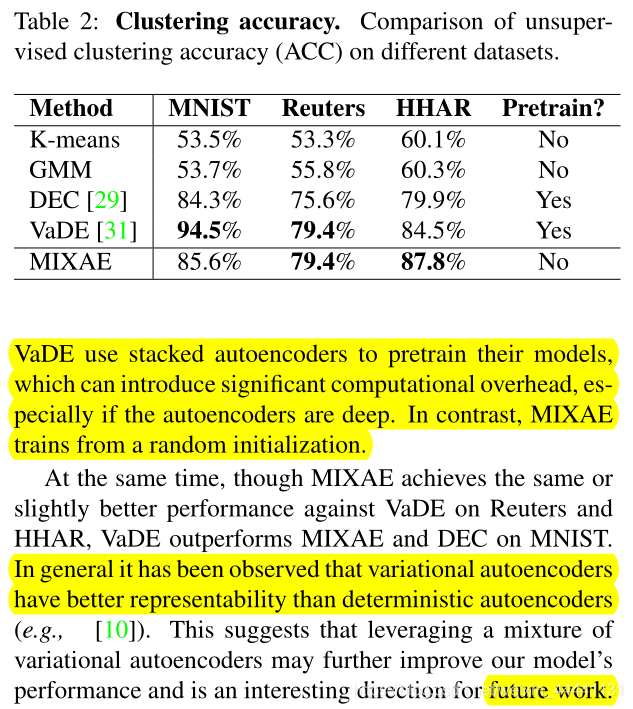
4.2 MIXAE不如VaDE
作者给出原因:VaDE用了Pretraining,尤其是在网络比较神的时候(因为作者对不同的数据集使用了不同的神经网络结构)
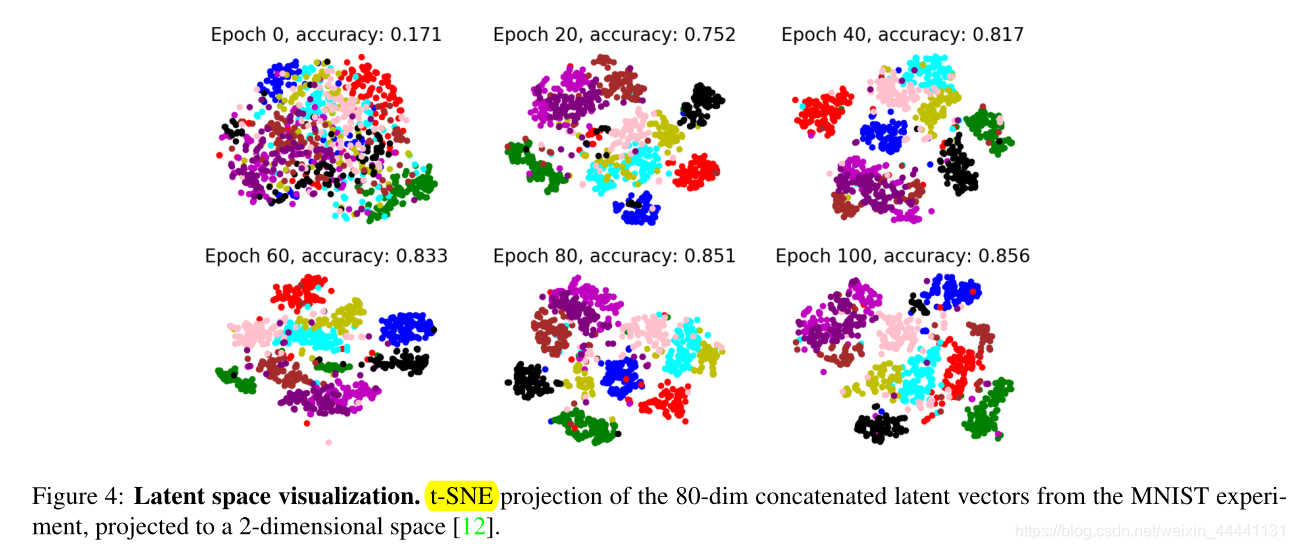
4.3 展示聚类效果
这些图片是通过聚类标签来选择样本放入网络生成的,因为MIXAE并不是一个生成模型,它不能生成图片

5. 回答如何聚类
我们可以从损失函数理解聚类的原理,但是存在一个漏洞,我们之前讨论过:
-
这里其实存在一个很大的漏洞:
理论上,我们是希望数据集经过概率分配网络后,不同类别对应不同的softmax最大值的位置,我们如何确保这一点,作者并没有提,作者在本篇文章中知识确保了softmax值偏向于one_hot向量,确保了在一个batch中对每个自编码器的选择是平均的。或许如果数据本身就有很明显的类别区分,softmax值也会对用不同的最大值,需要调参数来解决这个问题。当然这只是我的一些思考。 -
这个问题在DEC、GMVAE、VaDE中都存在,对实验超参数的调解要求很高,所以复现起来很困难,这可能也是深度聚类中存在的一大问题。