文章:Deep Clustering for Unsupervised Learning of Visual Features
作者:Mathilde Caron, Piotr Bojanowski, Armand Joulin, and Matthijs Douze
来自于:Facebook AI Research
发表于:ECCV 2018
目录
•相关链接
•相关方法介绍
•文章出发点
•文章亮点与贡献
•方法细节
•实验结果
•分析与总结
相关链接
论文:https://arxiv.org/abs/1807.05520?context=cs
相关方法介绍
深度聚类就是将深度学习与聚类相结合,相比于传统聚类方法,深度聚类较为简单,网络结构容易理解,聚类的效果也比大部分的传统方法要好,通过超参数的调整,往往还能达到更好的效果。
在此推荐一篇文章:Towards K-means-friendly Spaces: Simultaneous Deep Learning and Clustering,文章地址为:https://arxiv.org/abs/1610.04794.
这篇文章是我看的第一篇关于深度聚类的文章,这篇文章利用自编码器(auto-encoder)的方法同时进行网络的学习和聚类,提出了一种DCN的网络模型:
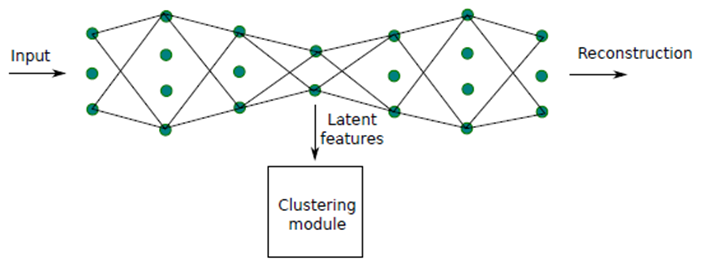
网络由编码器和解码器组成,在瓶颈层(bottleneck layer)前的是编码器,学习输入数据的潜在特征,将高维特征映射到低维子空间中,输入给聚类模型进行聚类,类似于传统的PCA的做法,而解码器则对特征进行”恢复“,使得特征重构成原始数据,这有利于网络学习更加重要的特征,忽略一些不重要的特征。自编码器的方法也成为了深度聚类当中较为常用的方法,当然这种做法也有一些缺陷,容易出现”blue sky problem“, 如果目标与背景大小相差较大,则网络在学习当中容易忽略目标特征。
通过这篇文章,让我对深度聚类有了一个基本认识。这次要分享的论文,更是在深度学习的基础上将聚类与分类结合起来,用聚类来指导分类,采用这种互学习的思想,提高了聚类与分类的效果,使得网络能够更好的应用于其他领域,如:目标检测、图像恢复、分割等领域,并取得更好的效果。
文章出发点
作者写这篇文章的出发点主要有以下几个:
1、深度学习的发展使得很多领域都取得了惊人的进步,特别是在图像分类领域,准确率已经达到超过人类的水平,然而现在通过改变网络的结构对分类准确率的影响已经越来越小,因此人们把关注点放在扩充数据集上,现有的常见数据集规模相对现在深度学习发展水平来说也是有些不够的,然而扩充数据集不是一件简单的事,许多时候需要进行人工的标注,既然有人为的参与就一定会有错误的出现,这些错误的标注也会成为影响训练效果的因素。因此使用无监督的方法生成更大的数据集也成为了现在研究的需求。
2、一些人工设置的特征一般只能在特定的任务取得好效果。
3、几乎没有聚类方法使用端到端的训练来学习特征,之前聚类方法主要是针对固定特征之上的线性模型而设计的,如果要进行特征的同时学习,模型的效果就会微乎其微。
文章亮点与贡献
亮点:文章提出的网络结构将聚类和分类两个任务结合起来,两个任务使用同一个网络,共享网络的参数,通过聚类得到的结果作为伪标签(pseudo-labels),提供给网络的分类器进行训练,更新网络的参数。这种互学习的方法有利两种任务的相互促进,从而各自得到更好的效果。
贡献:
1、可以进行端到端的学习,可以用于任意的标准聚类法方法,如k-means,且不需要过多的额外步骤。
2、在无监督学习中应用的迁移任务的效果达到了世界先进水平。
3、在未处理的不均匀的图像分布上训练最后的表现依然超过了之前的先进方法。
4、提供了一个当前关于无监督特征学习的评估标准的讨论。
方法细节
网络结构图如下所示:
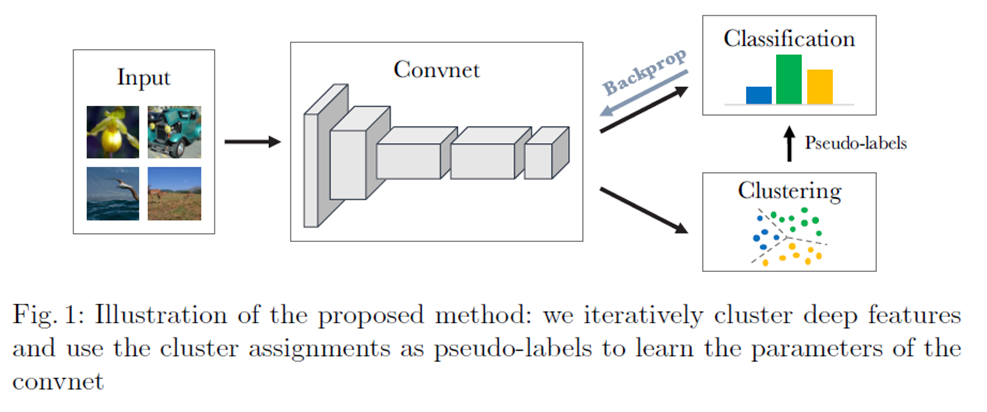
可以看到,网络结构相对还是比较简单的,数据从输入层输入到CNN中,CNN的结构没有限制,本篇文章作者主要使用的是AlexNet和VGG16,网络的输出分为两个分支,一个是聚类分支一个是分类的分支,聚类分支将CNN输出的features输入到clustering model中进行聚类,这里的clustering model使用的是常见的K-means,分类的分支就是简单的分类器。两个分支共享CNN的网络参数,聚类结果作为伪标签提供给分类器进行训练,通过分类的训练进行反向传播优化网络的参数。
作者还提到,之前的一些基于线性模型的聚类方法是基于固定特征之上的,如果要同时学习特征,那么最后的效果就会很差,如果通过CNN学习特征,并且使用这些特征使用K-means等聚类方法进行聚类,通过网络的不断学习,容易陷入平凡解(trivial solution)。所为平凡解,一个简单的解释就是我们在解一个简单的线性方程Ax=0时,如果不进行限定,就有一个零解的情况。反映在聚类当中就是,所有的学习到的特征都为0,最终都被归为一类,它们离聚类中心的距离也都时最小,都为0。作者提出了相应的解决方法,这在后米面会介绍到。
损失函数分为两类:(1)网络损失;(2)聚类损失
1、网络损失

网络的损失也是比较简单的,上文中提到,网络的训练是通过分类的分支来进行的,所以该损失也是我们常见的分类损失。
其中,ƒΘ(x)表示CNN在网络参数Θ下对输入x进行的特征映射,gw(·)表示分类器对特征进行分类的结果,l(·;y)则表示多项式逻辑损失(multinomial logistic loss),常用于一对多的分类任务上,也即我们所熟知的softmax损失。
2、聚类损失
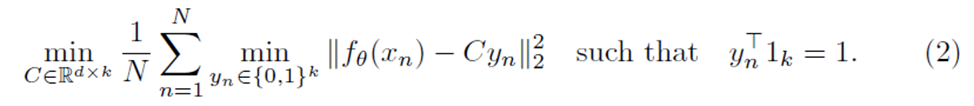
该聚类损失就是我们常见的K-means的损失函数,这篇文章也就是使用的K-means来做聚类,ƒΘ(xn)已经提到过是通过CNN所获得的特征表示,C是聚类中心矩阵,文中它应该是个d * k为的矩阵,d为特征的维度,k为中心个数,yn则表示样本n属于哪一个簇,是0和1组成的k维列向量,举个例子,如果样本n属于第0个簇,则yn = [1, 0, 0, 0.......0]T
在前文中已经提到了特征和聚类同时进行学习会产生平凡解的问题,针对这个问题,作者提出了一些解决方法:
1、避免平凡(无效)解
当一个簇变空时,随机选择一个非空簇,并使用带有小随机扰动的质心作为空簇的新质心。 然后,将属于非空簇的点重新分配给两个结果簇。
2、避免平凡(无效)参数
如果输入的数据分布不均匀,则学习的网络参数θ则会专门去区分它们,参数θ会导致网络只有相同的输出。解决方法是对输入数据进行重新采样使得分布均匀,或使用伪标签,这等价于公式(1)中1/N起到对输入对损失函数的贡献进行加权。
其他细节
训练集:ImageNet
基础网络框架:文章主要使用了两种网络框架,并且做了实验对比了文中方法在两个网络框架上的性能,分别是:AlexNet(移除局部响应规范化层,使用BN);VGG16(with BN);在数据输入网络前使用了基于Sobel filters的固定的线性变换移除颜色,增加局部对比度。
优化:
在网络训练上:中央图像裁剪以获得更好的特征;数据增强提高训练效果;dropout(a constant step size);对权重参数使用l2惩罚;使用0.9的动量。
在聚类过程中:对特征使用PCA 将特征维度降成 256 维,使用l2正则化,使用白化减少特征间的相关性,使得特征具有相同的方差。
超参数的选择:使用Pascal VOC的验证集上的目标分类任务未微调的超参。
实验
作者先是比较了自己的方法与其他方法在AlexNet上取出各层特征进行分类的性能:
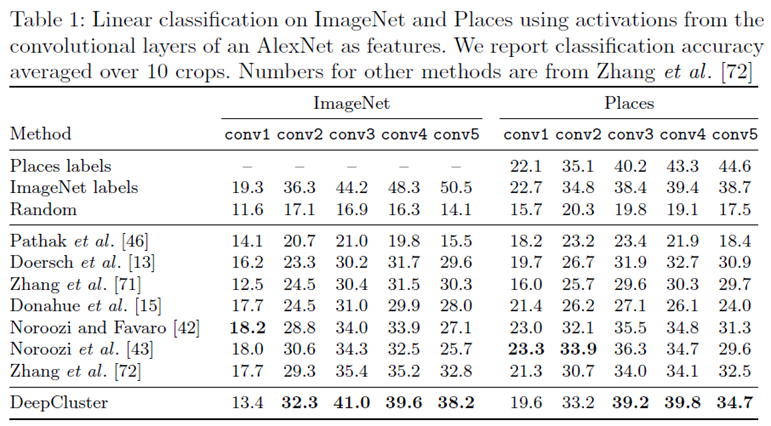
如上图所示,“Places labels”,“ImageNet labels”,“Random”分别是在Place数据集、ImageNet数据集与随机标注的有监督的方法,之后是多个无监督的方法,最后一个是作者自己的方法,分别用了各自的方法在各个层上获得的特征在两个数据集上进行分类的效果。可以看到,作者的方法都超过了其他无监督方法,比有监督的方法略低一些,这说明作者的完全无监督的方法,使得网络获得的特征进行分类的效果已经接近了有监督方法。还可以看到,作者的方法结果最好的是conv3,往后效果反而下降了,这主要是因为conv3的对于图像纹理的捕捉要好于conv5,conv5似乎只是简单的对conv3的纹理特征进行复用,从下图可以看出:


作者还比较各个方法在PASCAL VOC上进行分类、检测、分割等任务的效果:
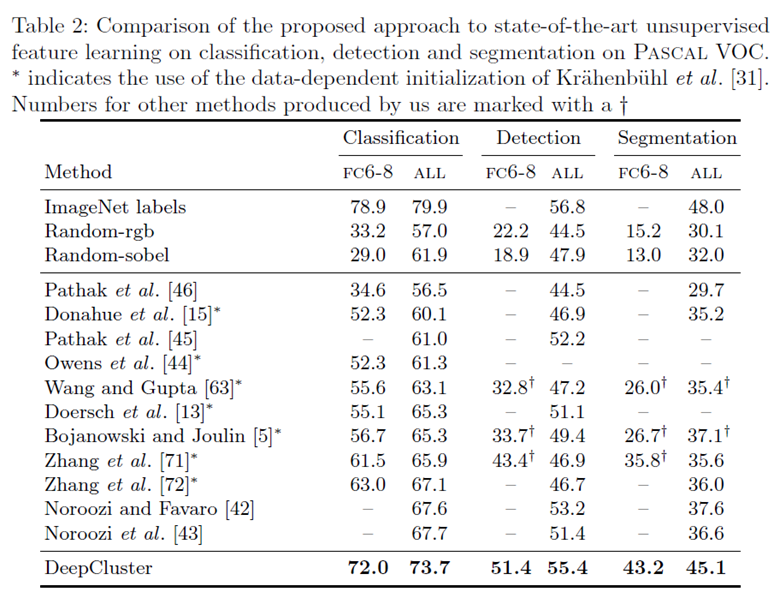
其中FC6-8表示只训练AlexNet的全连接层6-8的效果,All表示训练所有的层。可以看到作者的方法比其他无监督的方法效果要好很多,也是接近于有监督的方法。还有一个有意思的现象是,随机标签的有监督方法,在所有层上训练获得的效果要比只训练全连接层要提高很多。
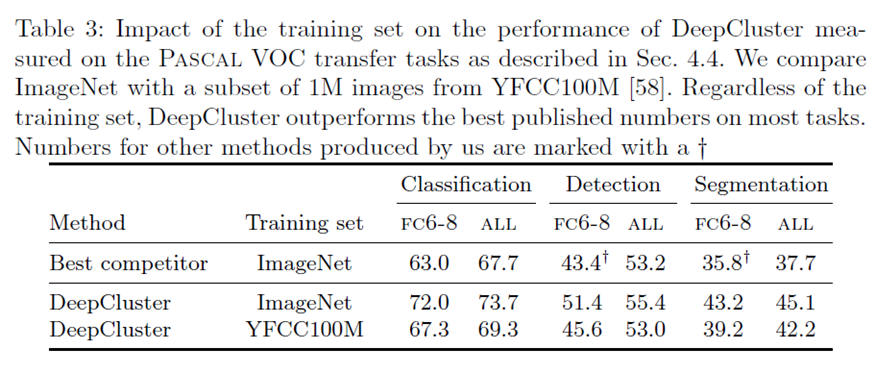
接下来,作者做了一个不同数据集上的对比试验:
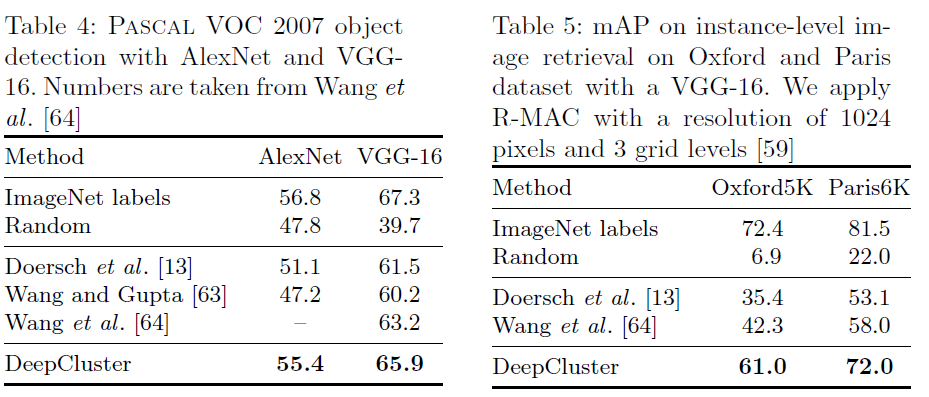
最后,作者做了在不同网络结构上的效果对比,和在图像恢复任务上的试验。按道理说,实验的效果会根据网络结构的变化而变化,网络结构越好最终的效果也越高,作者的实验也证明了,他的方法确实符合这个规则,也证明了他的模型的鲁棒性。
总结
这篇文章提出了一种可扩展的聚类方法,用于无监督的网络学习,它可以进行端到端的学习,可将网络得到的特征直接用于聚类,得到的聚类伪标签提供给分类任务。它是完全的无监督方法,不需要特定的先验知识,对输入没有过多的限制,这使得本方法可以很好的适应于标签稀缺的领域,该方法可以广泛应用在多个领域并且能够取得良好的效果。这篇文章的一大亮点就是应用了多任务学习,互学习的思想,将聚类与分类结合起来,使它们在训练的过程中相互促进,这也给予了我很大的启发,以后在研究过程中可以不仅仅只关注一个特定的任务,而是可以将多任务结合起来,进行同时学习,说不定能达到更好的效果。