Deep Multimodal Subspace Clustering Networks
作者:Mahdi Abavisani , Student Member, IEEE, and Vishal M. Patel , Senior Member, IEEE IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, VOL. 12, NO. 6, DECEMBER 2018
这是一篇关于多视图聚类的文章:接下来我粘贴一些文章的原文,为了方便阅读,直接粘贴汉语了。
Abstract
提出了一种基于卷积神经网络的无监督多模态子空间聚类算法。该框架主要由三部分组成:多模态编码器、自表达层和多模态解码器。编码器以多模态数据为输入,将其融合到一个潜在的空间表示中。自表达层负责增强自表达性并获得与数据点对应的亲和矩阵。解码器重建原始输入数据。该网络利用译码器的重构与原始输入之间的距离进行训练。我们研究了早期、晚期和中期的融合技术,并提出了三种不同的用于空间融合的编码器。对于不同的空间融合方法,自表达层和多模态解码器本质上是相同的。除了各种空间融合方法外,还提出了一种基于亲和融合的网络,该网络中不同模式对应的自表达层是相同的。在三个数据集上的大量实验表明,所提出的方法明显优于目前最先进的多模态子空间聚类方法。
作者就是其实提出了两种方法,一个是前面说的基于早期、晚期、中期的融合技术,三种技术的区别就是编码器不同,对于自表达层和解码器层都是相同的(下图abc),作者称之为:SPATIAL FUSION-BASED DEEP MULTIMODAL SUBSPACE CLUSTERING:基于空间融合的深多模态子空间聚类。后一种就是基于亲和融合的网络(下图d),作者称之为AFFINITY FUSION-BASED DEEP MULTIMODAL SUBSPACE CLUSTERING:基于亲和力融合的深多模态子空间聚类。接下来分别讲一下这两种方法
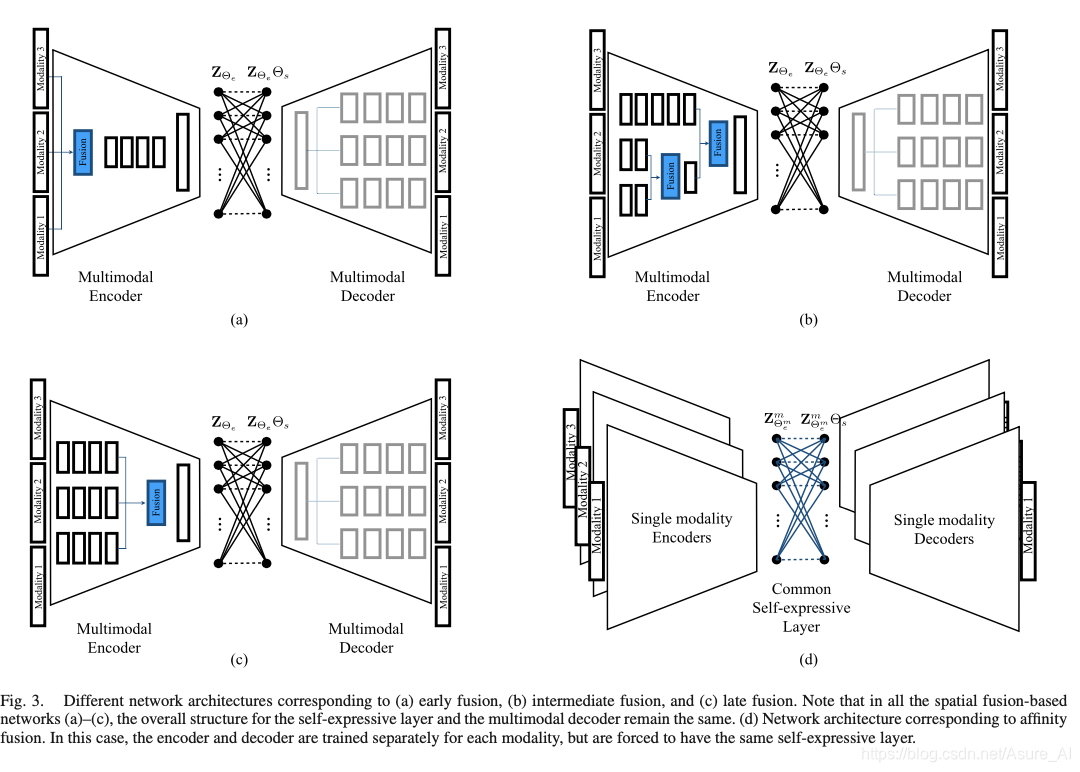
SPATIAL FUSION-BASED DEEP MULTIMODAL SUBSPACE CLUSTERING
我们构建了深模态子空间聚类网络。我们的框架由三个主要组件组成:编码器、完全连接的自表达层和解码器。我们建议使用编码器来实现空间融合,然后将融合的表现形式反馈给一个自表达层,该层本质上利用了联合表现的自表达特性。由自表达层的输出产生的联合表示然后被馈送给一个多模态解码器,该解码器从联合潜在表示重建不同的模式。
我感觉就是是升级版的AutoEncoder,就是输入是多个,然后融合一下输入,然后就获得了中间隐藏层,然后再把中间隐藏层优化一下,获得了自表达层,然后再把新获得的自表达层进行解码,再获得多个输出,然后通过输入和输出的差值来构建loss。
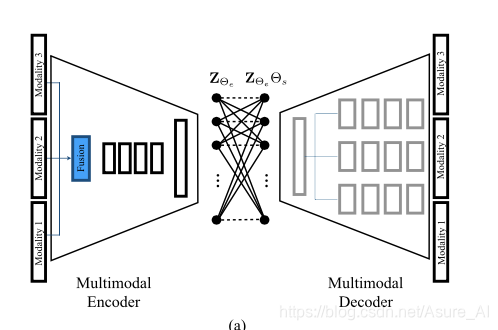
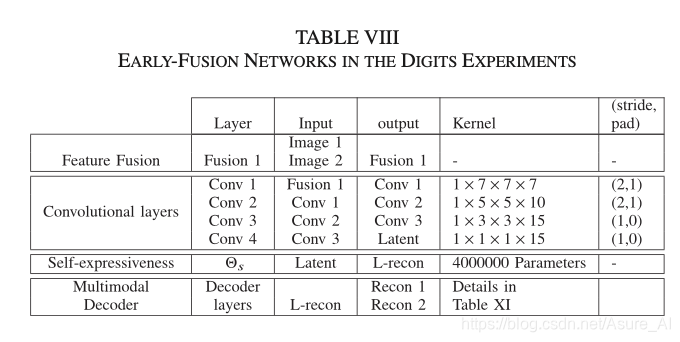
上图就是早期融合,是指将多模态数据在特征级阶段进行融合,然后再将其输入网络进行卷积,然后得到中间层,中间层再弄个自表达。然后在把自表达层decoder得到输出结果。
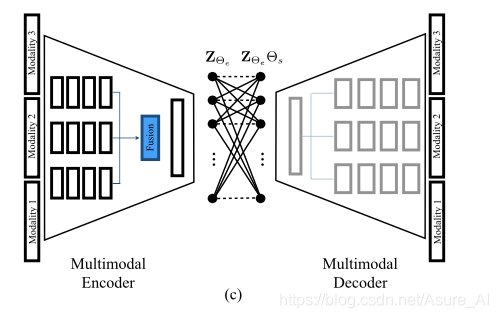
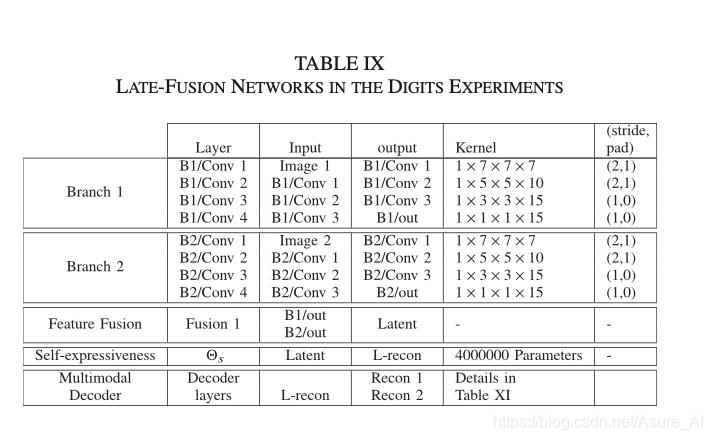
然后就是后期融合技术,其实就是先卷积,再融合,和前期差别不大。
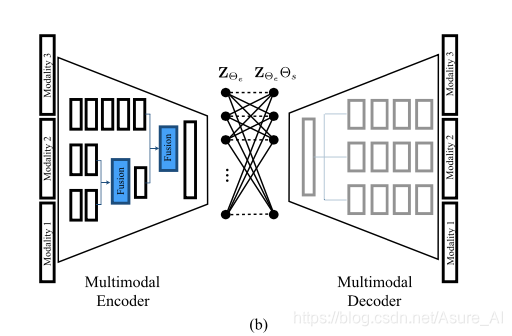
再然后就是中期融合了,这个和前两个还是有区别的。在这种融合中,来自网络中间层的特征映射被组合在一起,以实现更好的联合表示。通常的做法是在早期阶段将较弱或相关的模式聚集在一起,在深入阶段将剩余的强模式合并在一起。
什么是强模式,什么是弱模式呢?看看作者怎么说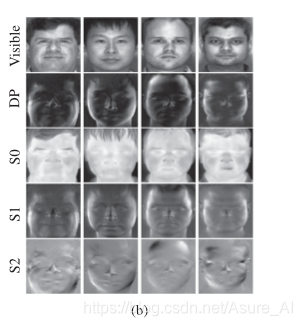
在本实验中,我们在多模态方法中加入以下中间空间结构。假设可见域是主要模态,我们将第二层的S0、S1和S2模态进行积分,并将其融合后的输出与第三层的DP样本相结合。最后,我们将结果与可见域融合在编码器的最后一层。就是作者认为S0,S1,S2是弱模式,所以先融合,然后在和DP融合,最后好visible融合为,因为越最后融合的,在新的表达中所占的比重就会越大一点。太早之前的占得比重会慢慢变小。
融合方式有三种

就是这里三个表达式,不难看出,第一个就是把几个表示中相同位置的特征加起来。第二个就是取最大,第三个就是把本来的一维特征转换为M(视图的数量)维度的张量。这就是三种融合方法,接下来介绍段对端的训练优化函数
End-to-End Training Objective
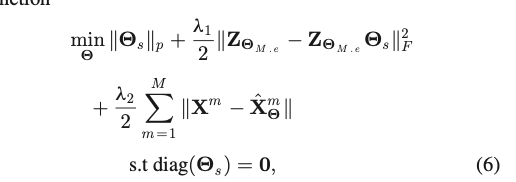
首先最小化 Θs,然后最小化模型输入?中间层和自表达层之间的差值,然后最小化各个形态与各个形态输出的差值,λ1 and λ2 是两个正则化参数,and ∥ · ∥p can be either l1 or l2 norm.
AFFINITY FUSION-BASED DEEP MULTIMODAL SUBSPACE CLUSTERING
其实有了上面的基础,这个就简单了,
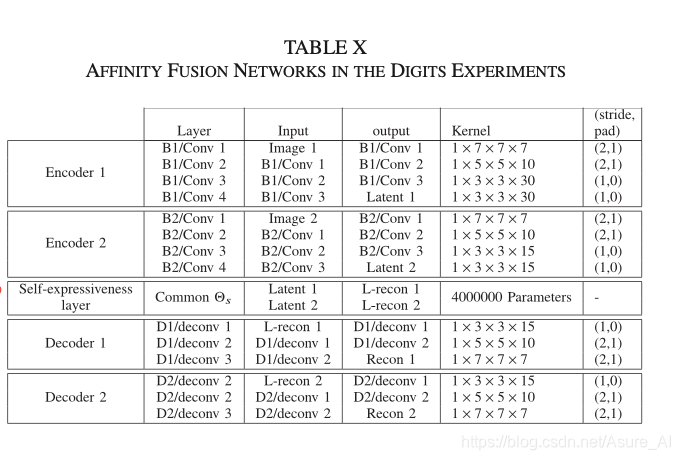
在本节中,我们提出了一种融合跨数据模式的关联以实现更好的聚类的新方法。空间融合方法需要对不同模式的样本进行对齐(见图4),以获得更好的聚类效果。与此相反,所提出的亲和融合方法结合了自表达层的相似性来获得多模态数据的联合表示。这是通过强制网络具有联合亲和矩阵来实现的。这避免了对齐数据或增加融合输出输出的维数的问题(例如,,连接)。执行共享关联矩阵的动机是,在一种模式中相似(不同)的数据在其他模式中也应该相似(不同)。图5显示了通过强制模式共享相同的亲和矩阵而提出的亲和融合方法的示例。
在DSC框架[16]中,亲和矩阵由自表达层权值计算如下
W=|Θs |+|ΘsT |,
Θs对应的自我表现的层权重学习通过端到端的培训策略[16]。因此共享Θs导致一个共同模式W。我们执行模式共享一个公共Θs虽然有不同的编码器,解码器和潜在的表征。
然后他的网络架构就是

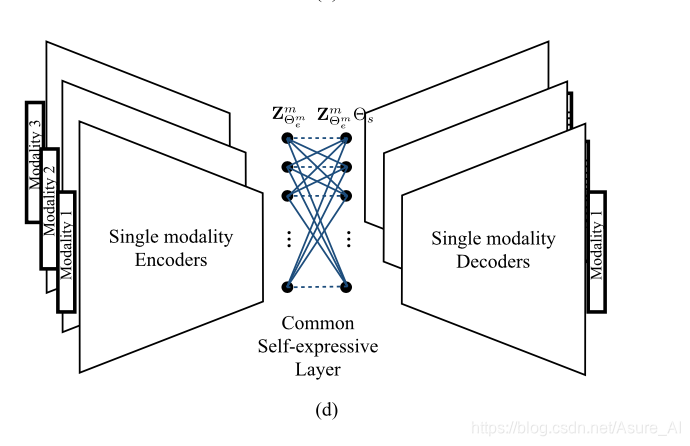
这个没有用融合技术,它是强制自表达层相同,一起训练自表达层,所以每个视图分开训练,那它的段对端表达式就和上面不一样了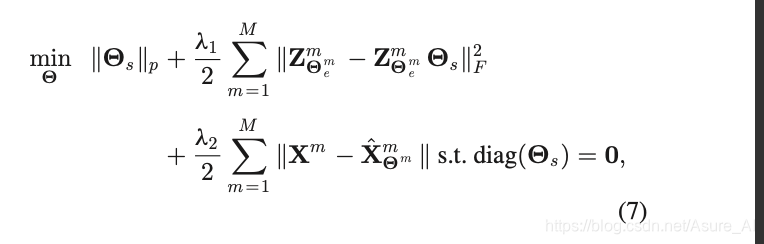
上面的是所有视图融合之后用一个自表达层,这个是每个视图有一个自己的表达层,最然他们一样。但是表达层的loss也需要累加。so,也就差不多那个意思。
Conclusion
提出了一种用于多模态数据聚类的深多模态子空间聚类网络。特别提出了空间融合和亲和融合两种融合技术。我们观察到,在深度多模态子空间聚类任务中,空间融合方法依赖于模式间的空间对应。另一方面,所提出的亲和融合在所有模式中找到一个共享的亲和,在所有进行的实验中提供了最先进的结果。该方法对扩展的Yale-B数据集中的图像进行聚类,其计算能力为99.22%,归一化互信息为98.89%,调整rand指数为98.38%。
最后都得到了,亲和度矩阵W,然后目的也就达到了。

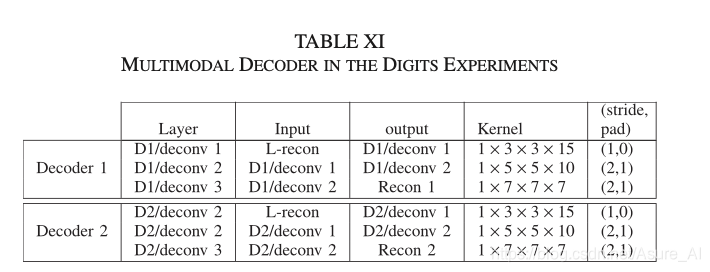
这里的C就是 Θs。下面贴一点代码执行的网络架构,看了应该会更清楚点,具体文档可以百度下载。