文章作者信息:

Structural Deep Clustering Network 结构化深度聚类网络
深度聚类算法SDCN,首次将GNN用到聚类上,由北邮、腾讯和清华联合发表在WWW2020上。
Abstract
Deep clustering(deep learning approaches)将深度学习强大的表征能力融入到聚类任务中。有效的学习数据的表征是深度聚类的关键。但是现有的工作仅关注数据自身的特性,在学习表征(representation learning)时很少考虑数据的结构。基于图卷积网络(GCN)对图结构进行编码的巨大成功,我们提出了一种结构深度聚类网络(SDCN),将结构信息集成到深度聚类中。具体来说,我们设计了一个传递算子(delivery operator)将自编码器(autoencoder)学到的表征(representations)传递到对应的GCN层,以及一个双重自监督机制(a dual self-supervised mechanism)来统一这两种不同的的深度神经网络结构(autoencoder和GCN)并指导整个模型的更新。使用这种方法,将数据的多重结构(the multiple structures of data) 从低阶到高阶,与自编码器学习到的表征自然地结合在一起。另外过传递算子(delivery operator),GCN将自编码特有的表示改进为高阶图正则化约束,而自编码器帮助缓解了GCN中的过平滑问题。通过全面的实验,我们证明了我们提出的模型比当前最先进的技术表现得更好。
1 Introduction
深度聚类的基本思想是将聚类的目标集成到深度学习强大的表征能力中。因此,学习有效的数据表示是深入聚类的重要前提。尽管深度聚类很成功,但它们通常只关注数据本身的特征,在学习表示时很少考虑数据的结构。结构信息在数据表示学习中有着至关重要的作用,然而很少用于深度聚类。最近出现的图卷积网络(GCN)同时对图结构和节点属性进行编码用于节点的表征。
将结构化信息集成到深度聚类中需要解决的问题:(1)深度聚类中需要考虑哪些结构信息?结构信息反映了数据样本之间潜在的相似性。但是这种结构是非常复杂的,不仅有直接关系(低阶结构)也有高阶结构,高阶结构对样本的one-hop关系添加了相似性约束。以二阶结构为例,两个样本之间不是直接关系,而是有许多共同的邻居样本,但是仍然有相似性的表示。数据的结构非常稀疏时,高阶结构就显得非常重要。在深度聚类中,仅仅利用低阶结构远远不够,首要问题是能够有效的考虑高阶结构。(2)结构信息与深度聚类的关系是什么?深度聚类的基本组成是深度神经网络(DNN),例如自编码器由多层网络组成,每层网络捕获不同的潜在信息。数据之间在存在不同的结构信息,我们可以使用某种方式的结构来规范化(regularize)由自编码器学到的表征。但是我们也可以从结构本身学习表征,如何优雅(elegantly)将数据结构与自编码器进行结合是另一个问题。
捕获结构信息:构造K近邻(KNN)图来捕获结构信息,我们提出了由多层图卷积层组成的GCN模块去学习GCN特有的表征(GCN-specific representation)。
将结构信息引入(introduce)到深度聚类:引入自编码器模型学习原始数据中(the raw data)自编码器特有的表征,并提出了一个delivery operator 来将其与GCN的特定表征相结合。从理论上证明了delivery operator能够协助于自编码器和GCN的集成。GCN对于自编码器的表征学习提供了一个近似的二阶图正则化,而自编码器学习的表征可以缓解GCN的过平滑(over-smoothing)问题。
对于自编码器和GCN模块提出了双重自监督模块来统一指导,通过自监督模块,可以对整个模型进行端到端(end-to-end)的训练,实现聚类的任务。
SDCN将自编码器和GCN的优势进行结合,并且提出传送算子(delivery operator)和双自监督模块(a dual self-supervised mechanism)。这是第一次明确地将结构信息应用到深度聚类中。6个真实数据集上进行广泛实验,与baseline相比取得显著改善(17% on NMI, 28% on ARI)。
2 Related Work
深度聚类方法旨在将深度学习与聚类的目的(objective)相结合,深度聚类将聚类结果作为标签可以用于训练大数据集的深度神经网络。然后之前的工作都只关注从样本本身学习数据的表示,另一个重要信息即数据的结构,在很大程度上被忽略了。而基于GCN的方法都依赖于重建邻接矩阵来更新模型,这些方法只能从图结构中学习数据表示,忽略了数据本身的特点。
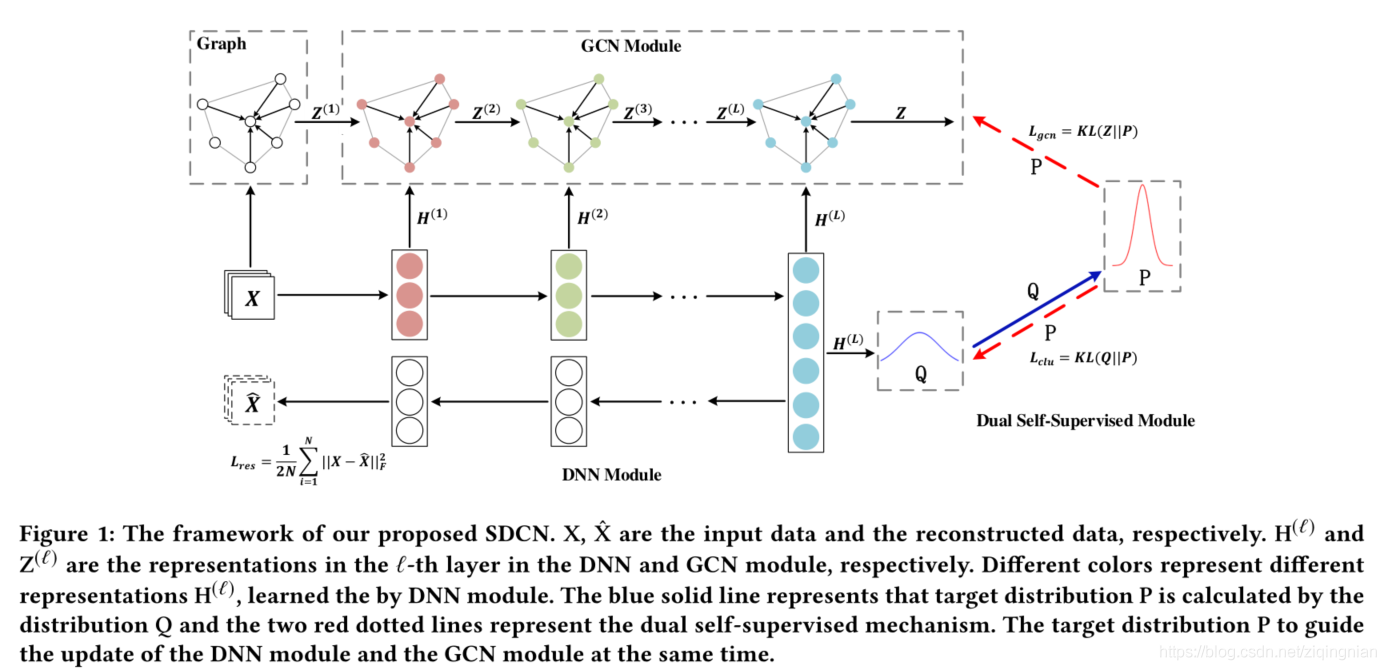
图片1:X和X_hat分别是输入数据和重建(reconstructed)数据, H(l)和Z(l)分别是第l层的DNN和GCN模块的表征,不同的颜色表示通过DNN学习到的不同的表征。蓝色实现表示目标分布P是由分布Q计算得到的,两条红色虚线表示的是双重自监督机制。目标分布P同时指导DNN模块和GCN模块的更新。
3 The Proposed Model
首先构造一个基于原始数据的KNN图,然后将原始数据与KNN图分别输入到自编码器和GCN中,将自编码器的每一层与对应的GCN层连接起来,这样就可以通过delivery-operator将自编码器的特定表征集成到感知结构表示(structure-aware representation)中。同时双重自监督机制监督自编码器和GCN。
3.1 KNN Graph
假设原始数据X(N*d),N为样本数,d为维数。对于每个样本我们首先找到它的top-K个相似的邻接样本,并且使用边(edges)将其与其邻居进行连接。需要计算样本的相似性矩阵,采用以下方式:
- Heat Kernel 样本i和j,t是时间参数,公式用于连续数据如图像

- Dot-product 用于离散数据,如bag-of-word

本模型也用于非图结构的数据,需要构建无向图,提取邻接矩阵A,用于GCN
计算相似度矩阵S后,选择每个样本的top-k个相似样本作为其邻点,构建无向k近邻图,这样可以从非图数据中得到邻接矩阵A。
3.2 DNN Model
为了通用性使用基本的自编码器来学习原始数据的表征,以适应不同类型数据。假设自编码器有L层,l表示层数。第l层的编码器的部分可以表示为:
![]() ,最外层为全连接层的激活函数如Relu,W、b分别是权重和偏置。编码器后面与译码器相连接,译码器根据方程通过几个全连接层重构输入数据。
,最外层为全连接层的激活函数如Relu,W、b分别是权重和偏置。编码器后面与译码器相连接,译码器根据方程通过几个全连接层重构输入数据。
![]() W、b分别是译码器的权重和偏置。
W、b分别是译码器的权重和偏置。
译码器的输出部分是原始数据的重建X_hat=H(l),目标函数为
![]()
3.3 GCN Model
自编码器从数据本身学习表征如H(l),但是忽略样本之间的关系。使用GCN模块传播由DNN模块生成的这些表征。一旦DNN模块学习的所有表征都集成到GCN中,那么GCN-learnable表征将能够适应两种不同类型的信息,即数据本身和数据之间的关系。特别是,权重矩阵W表示第l层GCN学习到的表征,Z(l)可以通过下面的卷积操作得到
![]() ,GCN的输出表示和原GCN一样。
,GCN的输出表示和原GCN一样。
将Z(l-1)和H(l-1)进行结合
![]()
ϵ为平衡系数,一般为0.5。通过这种方式将自编码器与GCN层层相连,然后将Z_hat(l-1)在GCN中作为第l层的输入产生Z(l)作为表征。
![]()
自编码器的表征H(l-1)将会由通过邻接矩阵A的标准化进行传播。为了尽可能保留信息,将每层DNN学习到的表征转移到对应的GCN层。传递算子(delivery operator)在整个模型中工作l次。
第一层GCN的输入为X
![]()
GCN的最后一层为带有softmax功能的多重分类器
![]()
结果zi表示样本i属于聚类中心的概率,可以将Z视为一个概率分布。
3.4 Dual Self-Supervised Model
自编码器一般应用在无监督场景,而GCN则应用在半监督场景,他们都不能直接应用于聚类问题。提出的双自监督模块将两个模块统一在一个框架中,有效地对这两个模块进行端到端的聚类训练。
对于第i个样本和第j个类别,我们使用Student’s t-distribution作为衡量数据表征hi和类别中心向量uj的相似度

hi为H(l)的第i行,uj是通过在预训练自编码器k-means初始化的表征,v是Student’s t-distribution的自由度,qij可以被认为样本i被分配给类别j的概率,Q=[qij]为样本分配的分布。
得到聚类分布Q后,我们想使数据表征更接近类别中心,从而提高类别凝聚性(cluster cohesion),因此计算目标分布P为
![]()
fj为第j个类别中的qij求和,![]() ,在目标分布P中,Q的每个值都会被平方后归一化,使最终拥有更高的置信度,则目标函数为
,在目标分布P中,Q的每个值都会被平方后归一化,使最终拥有更高的置信度,则目标函数为
![]()
通过最小化Q分布和P分布之间的KL散度损失,目标分布P可以使数据表征更靠近簇中心,这被认为是一种自监督机制,因为P由Q计算得到,而P反过来监督Q的更新。
对于GCN模块的训练,GCN也会输出聚类分布Z,我们用分布P监督分布Z
![]()
目标函数有两个优点:(1)与传统的多分类损失函数相比,KL散度以更“温和”的方式更新整个模型,防止数据表示受到严重干扰;(2) GCN和DNN模块统一在同一个优化目标上,使得它们在训练过程中的结果趋于一致。由于DNN模块和GCN模块的目标是近似目标分布P,这两个模块之间有很强的联系,我们称之为双重自监督机制。
最终的总损失函数为
![]()
α> 0为平衡原始数据聚类优化和局部结构保留的超参数,β> 0是控制GCN模块对embedding 空间干扰的系数。
经过训练,直到最大epoch,SDCN将会收敛得到稳定的结果。然后我们可以为样本设置标签。我们选通过分布Z计算选择最终的聚类结果,分配给样本的标签为
![]()
Zij是公式10计算所得。
整个算法流程如图所示:

3.5 Theory Analysis
3.6 Complexity Analysis
4 Experiments
4.1 Datasets

SDCN使用表中的6个数据集进行评估
USPS:USPS数据集包含9298张灰度手写数字图像,大小为16x16像素。特征为图像中像素点的灰度值,所有特征归一化为[0,2]。
HHAR:异质性人类活动识别(HHAR)数据集包含了来自智能手机和智能手表的10299条传感器记录。所有的样本被划分为6类人类活动,包括骑自行车,坐着,站着,走路,上楼梯和下楼梯。
Reuters:它是一个文本数据。集,包含约81万篇带有分类树标签的英语新闻报道。我们使用4个根类别:企业/工业、政府/社会、市场和经济作为标签,并随机抽取10000个示例子集进行聚类。
ACM:这是一个来自ACM数据集的论文网络。如果两篇论文是由同一作者写的,那么这两篇论文之间就有优势。论文的特征是关键词的包词。选取在KDD、SIGMOD、SIGCOMM、MobiCOMM上发表的论文,根据研究领域将论文分为三类(数据库、无线通信、数据挖掘)。
DBLP:这是一个来自DBLP数据集的作者网络。如果两位作者是共同作者,那么他们之间就有优势。作者分为四个领域:数据库,数据挖掘,机器学习和信息检索。我们根据每个作者提交的会议来标记他们的研究领域。作者特性是由关键字表示的单词包中的元素。
Citeseer:它是一个引文网络,包含每个文献的稀疏词包特征向量和文献之间的引文链接列表。标签包含六个领域:代理、人工智能、数据库、信息检索、机器语言和HCI。
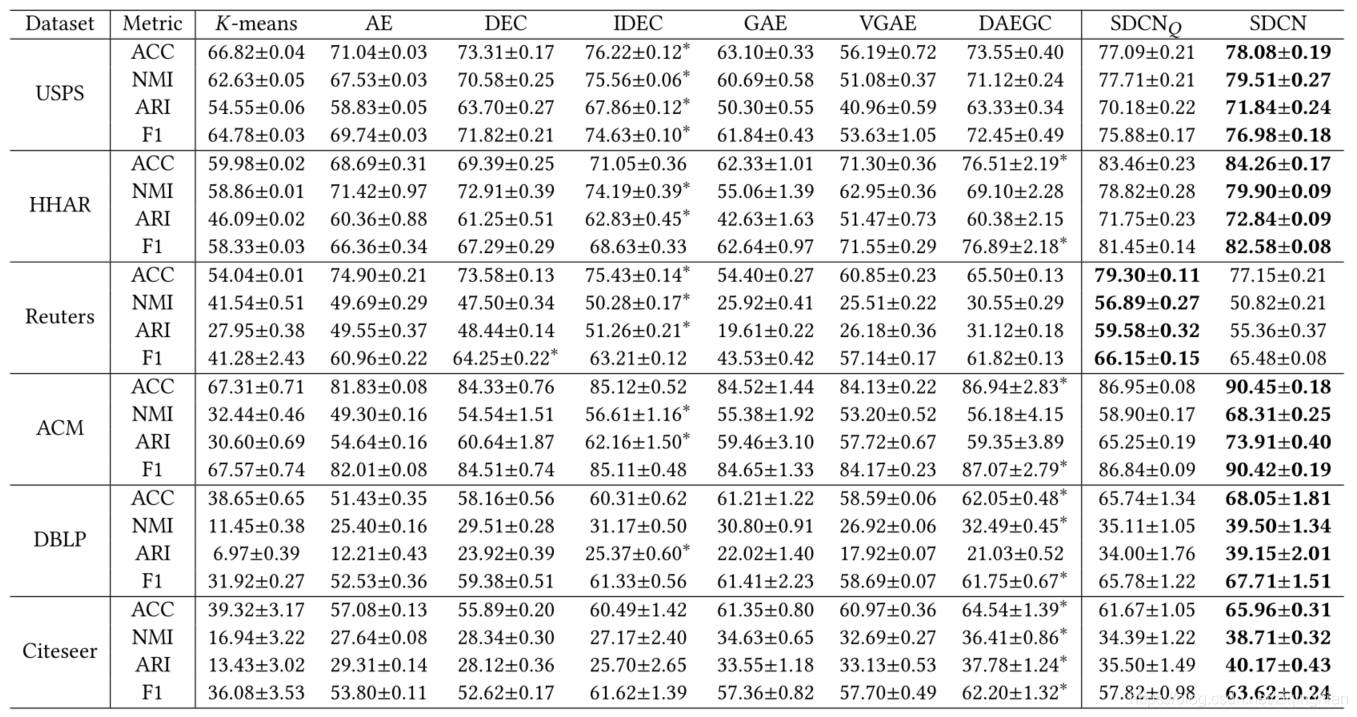
我们将我们提出的方法SDCN与三种方法进行了比较,分别是基于原始数据的聚类方法、基于DNN的聚类方法和基于GCN的图的聚类方法。
K-means为基于原始数据的聚类方法
AE为两阶段深度聚类算法,DEC和IEDC为深度聚类算法
GAE & VGAE和DAEGC为基于GCN的图的聚类方法
SDCNQ为分布Q的SDCN的变体。
度量标准(Metrics):我们使用四个流行的指标:准确性(ACC)、归一化互信息(NMI)、平均兰德指数(ARI)和宏观F1分数(F1)。对于每个指标,较大的值意味着较好的聚类结果。
Parameter Setting:
有时间再看其他部分