Unsupervised Learning Using Generative Adversarial Training And Clustering 翻译
摘要:
在本文中,我们提出了一种无监督学习方法,它使用了两个组成部分; 深度层次特征提取器,以及更传统的聚类算法。 我们使用生成对抗训练以纯粹无监督的方式训练特征提取器,并在此过程中,使用生成模型作为对手研究学习的优势。 我们还表明,在生成对抗网络(GAN)中进行的对抗性训练不足以自动将数据分组到分类群集中。 相反,我们使用更传统的分组算法k-means聚类来聚集使用对抗性训练学习的特征。 我们在三个众所周知的数据集CIFAR-10,CIFAR-100和STL-10上进行了实验。 实验表明,所提出的方法与监督学习方法的表现相似,并且在具有少量标记训练数据和大量未标记数据的情况下甚至可能更好。
1 引言
最近在机器学习和计算机视觉方面的许多工作都集中在高级任务的学习技术上,如图像分类。许多最先进的模型采用卷积神经网络(CNN)通过使用多层卷积处理输入数据来提取高阶特征表示,通常随后进行一些非线性变换。 CNN已成功证明可以产生高质量的特征表示,在各种任务上产生最先进的结果,不仅可以用于图像分类(如上所述),还可以用于语义分割,边界检测和物体检测等。这些模型经过训练,可以使用反向传播生成高质量的特征,通常是通过预训练大型数据集(如ImageNet),然后对相关数据集进行微调。不幸的是,监督学习受到某些挑战的困扰,特别是在可扩展性方面,因为它需要大量标记数据。标记数百万张图像需要大量工作并且耗时。此外,使用预定义的一组类进行监督训练,限制了学习的特征表示对新类的普遍性。
为了克服标记大量训练数据的困难,已经努力开发半监督和无监督学习技术。无监督学习技术的目标是学习可解释的表示,可以容易地转移到新的任务和新的对象类别,并且从纯粹来自未标记的数据中解开数据的信息表示与烦扰变量(例如照明,观点等)。用于无监督学习的常见且广泛使用的方法是使用k-Means进行聚类。 k-Means聚类是一种将输入要素分组到不同聚类中的简单方法。传统上,这种方法主要使用低级特征,如原始像素强度,HOG特征,GIST特征,SIFT特征等。虽然k-means对这些特征的性能通常较差,但Wang等人使用深度网络特征并采用k均值聚类在对分组对象时显示出强大的性能。但是,用于提取特征的深层网络是使用类标签监督在ImageNet上预先训练的(因此,对象知识是已知的)。如果能够以纯粹无监督的方式使用分层特征学习来学习强大的特征,那将是一种自然的延伸。然而,由于无监督学习的目标不像监督学习的目标那样具体,因此使用反向传播优化深层次模型变得困难。
已经尝试提出“借口”目标函数,这些函数通常由“常识”要求驱动,以进行无监督学习。 这些目标的一些例子包括最小化重建误差,训练模型以识别替代类别,预测图像斑块的空间位置 ,并最小化视频序列中一段时间内跟踪的对象在表示空间中的距离。
最近,人们对对抗训练产生了很大的兴趣。 生成性对抗网络(GAN)对这项工作特别感兴趣。 GAN的进步使得在过去几年中产生的图像质量得到显着改善。 虽然最近的许多努力已经用于开发建模和训练生成网络的更好的架构和训练过程,但在这项工作中,我们系统地研究了由生成器的对抗(即判别模型)而学习到的表示的力量。
在本文中,我们使用生成对抗训练学习深层网络。 我们使用从判别元件中提取的特征,并将其与传统的非监督学习算法(如k-Means)融合,以提高其性能。 我们在许多不同的数据集(CIFAR-10,CIFAR-100和STL-10)上进行各种实验,并表明可以纯粹通过无监督学习从对抗性信号中学习的表示有助于学习有意义的输入数据表示。 我们的实验表明,在具有最少量监督训练样本(以及大量无监督数据)的情况下,与对等体系结构的监督训练相比,通过对抗训练学习的表示具有竞争性。 我们现在简要概述GAN和InfoGAN采用的对抗性培训。
2 对抗训练的背景
生成对抗网络由两部分组成; 生成器和鉴别器
。 生成器将潜在编码映射到数据空间,而鉴别器区分由生成器生成的样本和实际数据。 训练发生器去愚弄鉴别器,同时训练鉴别器以免被发生器愚弄。
更正式地,给定训练数据样本,其中
是真实的数据分布,GAN的训练通过在两步之间迭代来进行。 在第一步中,我们固定生成模型的参数,采样一个潜在编码,
,并生成数据样本G(z),然后用于训练鉴别器
, 通过更新其参数来区分G(z)和x。 可以通过最大化预期的对数似然来更新鉴别器的参数,
在第二步中,我们固定鉴别器的参数并更新生成器的参数以生成由鉴别器分类为真实的样本。 的参数可以通过最小化下式来更新,
这个极小极大游戏的目标可以写成
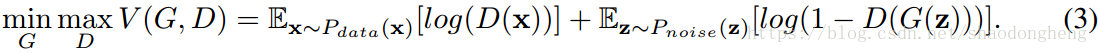
2.1 InfoGAN
上述公式使用噪声矢量z,其由生成器用于合成数据。该噪声向量不会对生成的数据具有什么限制。陈等人引入了一个简洁的想法,将GAN扩展为一个名为InfoGAN的特征识别系统。 InfoGAN使用结构化潜在编码c,除了噪声向量z之外,还输入到生成器
。编码可以是离散编码或连续编码。为了鼓励编码捕获训练数据中固有的语义结构,在目标函数中引入了一个新术语,它充当了一个正则化器,强制潜在编码c和生成的样本
之间的高互信息。由于很难最大化互信息,
,直接(因为人们需要知道真实的分布
),陈等人提供变分下界,其可以在使用参数辅助,
,近似
时获得。获得的变分下界是,
InfoGAN目标是原始GAN目标(方程3)的正则化版本,其中正则化器是互信息的变分下界,
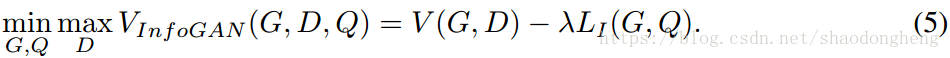
陈等人共享和
之间的参数,这有助于降低计算成本。 我们在所有实验中都这样做。
从方程式4的第一项可以看出,互信息正则化器的下界方便地证明是识别模型。 如果优化过程成功收敛,则可以希望学习潜在的编码,该编码最终代表数据中存在的最显著和结构化的语义特征。 噪声参数z最终提供输入的随机性,导致产生具有多样性的样本。
3 UNSUPERVISED LEARNING WITH ADVERSARIAL TRAINING AND K-MEANS++ CLUSTERING
如第1部分所述,我们感兴趣的是以纯粹无监督的方式学习图像的表示。 GAN和InfoGAN都提供了一种使用生成的图像作为对手训练判别网络的方法。 InfoGAN特别有趣,因为它能够直接预测训练数据库中可能存在的不同类别。虽然Chen等人提出了定性结果显示可以在MNIST数据集上自动识别类别,遗憾的是,相同的结果似乎没有扩展到更复杂和更真实的数据集(CIFAR-10,CIFAR-100和STL-10)。我们修改了作者发布的InfoGAN代码,以支持更逼真的RGB数据。然后,我们在上述数据集上训练模型以进行实验,以确定它是否可以自动识别各个数据集中存在的分类聚类。我们发现虽然我们在上述数据集上训练的InfoGAN成功生成了对于不同分类编码看起来不同的图像,但它无法识别这些数据集中存在的类级别分组。
相反,我们采用混合策略进行无监督学习。 我们首先使用生成网络作为对手来训练判别网络直到收敛。 收敛后,我们从网络的倒数第二层提取特征,并运行更传统的聚类算法,即k-means ++。 令人惊讶的是,与直接预测分类组的方法相比,这种简单的策略在分类来自类似类别的数据方面变得更加有效。 请注意,可以插入更复杂的无监督学习算法而不是k-means ++。 我们使用k-means ++来表明即使是简单的方法也可以产生合理的结果。
使用倒数第二层特征的另一个动机是它有助于特征转移到新的类和任务。 在监督学习方法中,首先使用类级监督在ImageNet图像上训练深度网络,然后执行网络手术以切断顶层权重,并使用此截断网络作为特征提取器在不同的数据集和任务进行进一步微调,这是常见的。 这样做并不会阻止模型仅针对可能用于的最终任务进行培训。 可以在“借口”任务上训练网络并将学习的权重转移到其他新颖的任务。 这对于无监督学习尤其重要,因为用于训练模型的借口任务几乎总是与模型最终将用于的特定任务大不相同。
3.1 网络结构
我们使用Radford等人的DCGAN架构,因为它被广泛用于生成图像。 图1显示了体系结构的可视化。

图1:该图显示了我们所有实验中使用的InfoGAN架构。 请注意,的输入是z和c的组合。 还要注意,大多数参数在
网络和
网络之间共享,从而提高了计算效率。
生成器:注意,除了随机噪声z之外,发生器已被略微修改以接受结构化潜在编码c。 第一层是完全连接的(fc)层,然后将其重新整形为空间分辨率为的二维网格,其中s是要生成的输出图像的大小。 在这次重塑之后,该架构具有四层转置卷积(有时称为反卷积),步长为2,每个层将输入特征上采样到空间分辨率的两倍。 这些层由batch norm
和ReLU层夹在中间。 最后,我们使用tanh非线性将特征映射到[-1,1]。
鉴别器:鉴别器是标准CNN,具有一系列卷积层,后面是非线性。 该体系结构使用由batch norm和leakyReLU层夹在中间的四个卷积层。 我们不使用max pooling来降低输入的空间分辨率。 相反,我们以2的步幅对特征映射进行卷积,这导致每个卷积层的输出为输入特征映射的空间分辨率的一半。 该基础架构在和
之间共享。 在此共享网络之上,我们使用fc层提取特征,然后使用这些特征来预测分类分布。 注意,大多数计算成本在
和
网络之间共享,从而使整个训练过程在计算上有效率。
3.2 UNSUPERVISED LEARNING WITH K-MEANS++
如前所述,虽然InfoGAN能够自动将数据分组到多个组中,但没有限制强制组需要与数据集中存在的各种对象级类别相对应。虽然这对于MNIST数据集来说是真的,但我们认为这是可能的,因为产生不同数字的笔画变化对应于数据集中最大变化的来源,这很方便对应于各种数字类别,从而使InfoGAN能够充当类别识别模型。在更现实的数据集中,最大变化的来源不需要(通常也不会)与对象级别类别的变化相对应。我们的实验表明这是真的。当我们训练InfoGAN自动将CIFAR-10图像分为10个类别时,我们发现虽然InfoGAN能够将图像分组到不同的组中,但这些组并不对应于对象类别级别的分组。图2显示了模型生成的一些示例示例。每行对应于不同的类别,并且该行中的每列对应于来自该类别的不同样本(通过保持c固定并通过改变z获得)。我们可以看到,虽然每行看起来彼此不同,但它与CIFAR-10类别不对应。

图2:图中显示了当鼓励系统识别10个类别时,在CIFAR-10数据集上训练的InfoGAN生成的样本。 每行对应于InfoGAN标识的不同群集。 每列对应于来自该群集的不同样本。 我们可以看到,虽然InfoGAN可以识别彼此不同的集群,但它们与CIFAR-10类别不对应。 见第4.1节,用于定量结果。
因此,我们采用混合方法进行无监督聚类。 我们首先使用vanilla GAN目标或InfoGAN目标训练判别网络,直到收敛。 收敛后,我们从共享网络的顶部提取训练集中每个图像的特征,标记为图1中的,并针对每个特征通道对空间分辨率进行
average_pooling。 然后,我们使用k-means ++将这些特征聚类到一组离散的k-类别中。 我们将k设置为相应数据集中存在的对象类的数量。 通过k-means ++聚类学习的聚类中心充当数据集中存在的k类别的模板。
在测试期间,我们通过将测试图像的特征表示传递到使用生成器作为对手训练的判别网络来提取测试图像的特征表示,在上进行average_pooling,并计算测试特征向量到每个中心( 在训练阶段通过kmeans ++聚类学习得到)的距离。 为测试图像分配对应于最近中心的索引的索引。 我们的实验表明,对
进行聚类比直接使用InfoGAN的识别模型产生更好的结果。 请注意,虽然我们使用简单的kmeans ++算法进行聚类,但它可以被更复杂的无监督学习算法所取代。 我们不会在这条路线上进一步探索,因为这项工作的范围是研究对抗性训练所学到的特征的强度。
混合方法的一个优点是它现在允许我们使用各种不同的“借口”目标。 换句话说,可以将训练目标与测试要求分离。 实际上,我们通过鼓励InfoGAN在训练数据中识别出比数据集中的对象类别数量更多的组来进行实验。 例如,我们通过鼓励系统识别[10, 20, 30, 35, 40, 50 and 75]组来在CIFAR-10数据集训练InfoGAN。 当然,这些组不符合类别级别的分组。 然而,令我们惊讶的是,我们发现当从使用大量类别(大量的分组[10, 20, 30, 35, 40, 50 and 75])训练的InfoGAN获得的特征用于聚类时,它们在数据集上的对象分类方面表现优于从在相同数量的对象类别上(分组数与数据集类别数相同)训练的InfoGAN获得的特征。 第4节提供了这些实验的定量结果。
4. 实验
我们在多个数据集上进行实验; CIFAR-10,CIFAR-100和STL-101。 我们仅将真实标签用于评估目的和训练监督学习的baseline。 训练过程完全没有监督。 我们使用两个标准指标报告结果,这些指标用于评估无监督学习算法; Adjusted RAND Index(ARI)和归一化互信息(NMI)得分。 我们提供三个baseline; (i)我们使用像素强度,HOG和GIST等简单特征报告结果,我们称之为低级视觉特征,(ii)我们报告使用标准GAN训练获得的特征的结果,(iii)作为上限, 我们使用监督学习来报告结果,其中我们使用由数据集提供的类别级别标签在具有相同架构的鉴别器网络中训练权重。
重要的是要记住,我们有兴趣比较可用于转移到新图像的学到的特征的质量,而不仅仅是预定义类别集上的分类分数。 分类准确度仅捕获测试图像被正确分类的程度。 如果分类不正确,则无法量化错误的严重程度。 另一方面,ARI是评估特征属性的更好度量标准,因为它不仅可以测量对象的准确组合的准确程度,还可以测量多少对数据点被错误地分组。 因此,当与使用监督学习训练的模型进行比较时,我们忽略该模型的顶层分类层,并在聚类之后使用ARI量化表示(即从倒数第二层提取的特征)的质量。
在我们进入定量结果之前,我们可视化判别网络第一层的过滤器,并在两个不同的训练过程中进行比较。图3显示了可视化。左侧是使用对抗训练训练的网络过滤器。右侧是具有相同架构的网络过滤器,但使用类级别监督进行训练。这两个网络都使用CIFAR-10数据集进行了训练。我们可以看到,虽然一些过滤器看起来彼此相似,但其中很多都是完全不同的。很明显,右侧的滤波器比左侧的滤波器更平滑。重新收集左侧的滤镜,使其适合实际图像和生成的图像。当生成的图像不像真实图像那样高质量时,学习的过滤器可能不像仅使用真实数据学习的过滤器那样正规化。我们假设提高生成图像的质量可以帮助规范
中的第一层滤波器。我们将这条探索路线留给未来的工作。

图3:该图显示了在CIFAR-10上训练的判别网络的第一层中的所有64个滤波器。 左侧的可视化对应于使用对抗性训练学习的过滤器。 右侧的可视化对应于使用监督学习为相同架构学习的过滤器。 有趣的是,左侧的滤波器具有更多的高频分量,右侧的滤波器更加平滑。