文章目录
写在前面
这篇文章是讲如何用VAE来进行无监督的聚类的,属于VAE的变种,同时这篇文章也多多少少存在一些问题,会在文章末尾指出,现在一起来看看这篇文章到底在讲什么。
摘要


读完摘要,我们肯定会有很多问题:
1.什么是over-regularisation,为什么它会导致cluster degeneracy?
2.什么是minimum information constraint,它为什么可以解决over-regularisation?
我们带着问题,继续深入解读这篇文章。
1. Introduction部分
这一部分,主要分成4个自然段:
第一段,介绍无监督聚类学习仍然是机器学习领域的一块重要研究内容;
第二段,主要介绍深度生成模型的内部机制和作用;
第三段,作者提出自己的模型,GMVAE.
“它作为VAE的一个变种,可以做深度无监督聚类问题。他们假设观测数据是由多模态的先验分布中产生的,并且相应的构建推理网络使我们直接可以使用重参数化技巧来优化模型”。作者也认识到了在他的模型里,存在over-regularisation的问题,它会影响我们的聚类效果,我们可以通过minimum information constraint的方法来解决它( Kingma et al. (2016),**到此我们解决了一个问题,minimum information constraint是用来解决over-regularisation问题的,同时作者还给出了over-regularisation问题的出处,这可以帮助我们解决什么是over-regularisation的问题。**接着往后看,请一定带着问题来读文章。
第四段,相关工作,就不再介绍了。

2. VAE的回顾
- 这里不再多啰嗦了,就是回顾一下标准的VAE

3. GMVAE
- 作者在这一部分提出了自己的模型。首先作者分析在标准VAE中,先验被限制了,因为学习到的隐空间的表示只能是单态的(unimodal),并不能表示更加复杂,例如多态(muti-modal)。单态的原因就是因为在标准VAE中先验是服从N(0,I)的高斯分布,只有一个峰。
- 所以在本文章中,作者使用GMM作为先验分布,来表示更加复杂的先验表示,获取到更多的信息。
- 完了用GMM先验做聚类,作者假设数据是从一个GMM分布中产生的,推理数据是哪一个类别就等价于推理数据是由隐空间分布的哪个“态”产生的。可以想象,GMM混合分布的components=10.

3.1 生成模型
- 生成模型的生成过程是这样的:
1.首先从w~N(0,I)中采样一个w,经过β网络生成GMM分布的10个components,不包括系数pi。
2.然后从z~Muti(pi)中采样一个z,z是一个one_hot向量,例如当选中第一个高斯分布时,z=[1,0,0,…,0],zk表示该one_hot向量中的第k个值。我们设置Πk=K^-1,来让z服从一个均匀分布,意思就是平均每个components的占比
3.这样就决定了隐变量x将从GMM分布的哪一个components中产生。由w,z决定产生了一个隐变量x
4.x经过θ神经网络生成图片y - 对图的解释
左边时生成过程,右边是推理过程,推理过程在下节介绍。
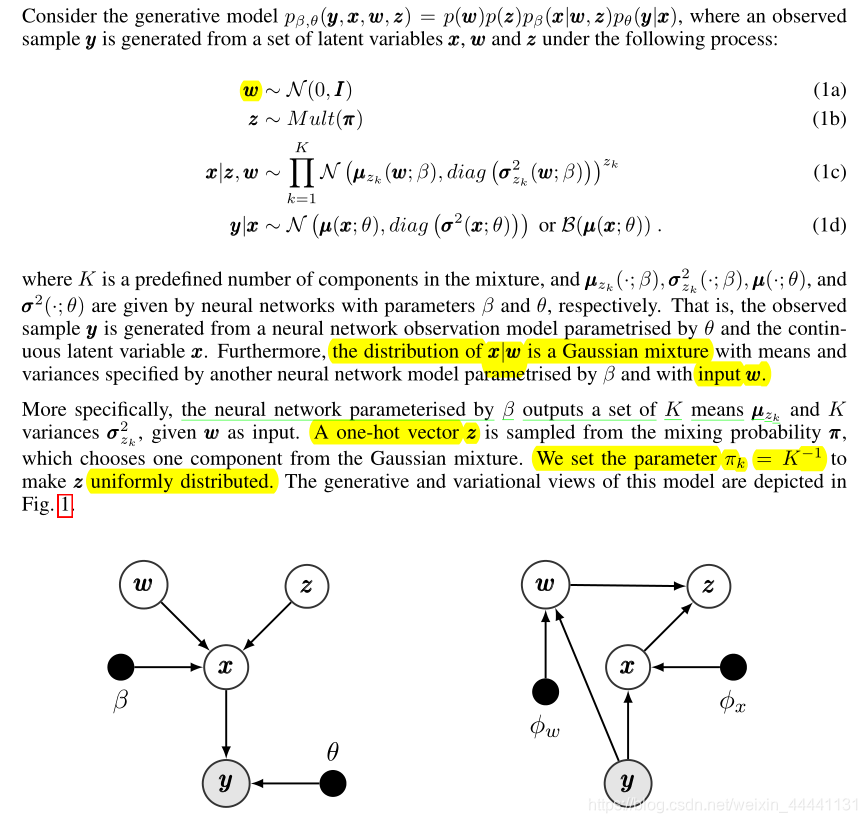
3.2 推理网络
- 推理模型有3部分:
- 由推理网络产生,输入y,输出q(x|y)
- 由推理网络产生,输入y,输出q(w|y),需要说明一点,作者在实际编程时,让“1&2”的参数共享了
- 不是推理过程,有精确的解,是根据GMM解出来的,表示给定隐变量时,隐变量对各个高斯分布的响应度,响应度越高表示z越有可能从该高斯分布中产生,这也就是利用GMM聚类的思想。这里要注意一点:p(zj=1)=1/K,全部是一样的,因为z服从的是一个均匀分布,相当于GMM中对应第j个component的系数Πj.
- 于是我们结合生成模型和推理模型就可以修改变分下界了:
- 重构项(通过蒙特卡洛采样法,从q(x|y)分布中采样送入decoder部分进行重构)
- 条件先验项
- w先验项(有解析解)
- z先验项
上面的2、4作者又做了详细的解释。

3.2.1 条件先验项
- 条件先验项不直接从p(z|x,w)中采样,而是实打实的求期望(对所有z的可能取值)。我们想想一下当我们最小化这一项时(就是最大化负的这一项),我们的q(x|y)会去逼近GMM混合的每一个components分布,也就是说后验单高斯逼近先验GMM分布

3.3 z先验项
- z后验直接根据x和w的值计算聚类分配概率。换句话说,给定隐变量x,和变量w,z后验计算该隐变量分别从每一个components中产生的概率,可以想象,对于某一类样本,它们更倾向于从某一个component中产生,不同的类别倾向于从不同的component中产生,和就是聚类的原理。z后验回答了隐变量x到w产生的每一个component的距离。
- 先验项减少了z后验和均匀分布的先验之间的距离,直观上,它将通过最大化类别重叠的部分来合并这些类,也就是说z先验项具有“反聚类“的效果
- 作者解释这种现象和标准VAE中存在的过度正则化(over-regularisation)很像。

3.4 过度正则化问题(over-regularisation)
- 作者在本文章中使用了有kingma提出的minimum information constraint方法,具体的对先验项设置一个最小值,让其在训练初期不会太低,也就是不让类别重合在一起。
- 关于过度正则化的问题仍然是一个开放的问题

4. 实验
实验被分为三部分:
- 研究synthetic dataset上的推理过程,专注于观察over-regularisation问题是如何影响我们的模型GMVAE的,以及如何减轻这种问题(使用minimum information constraint)
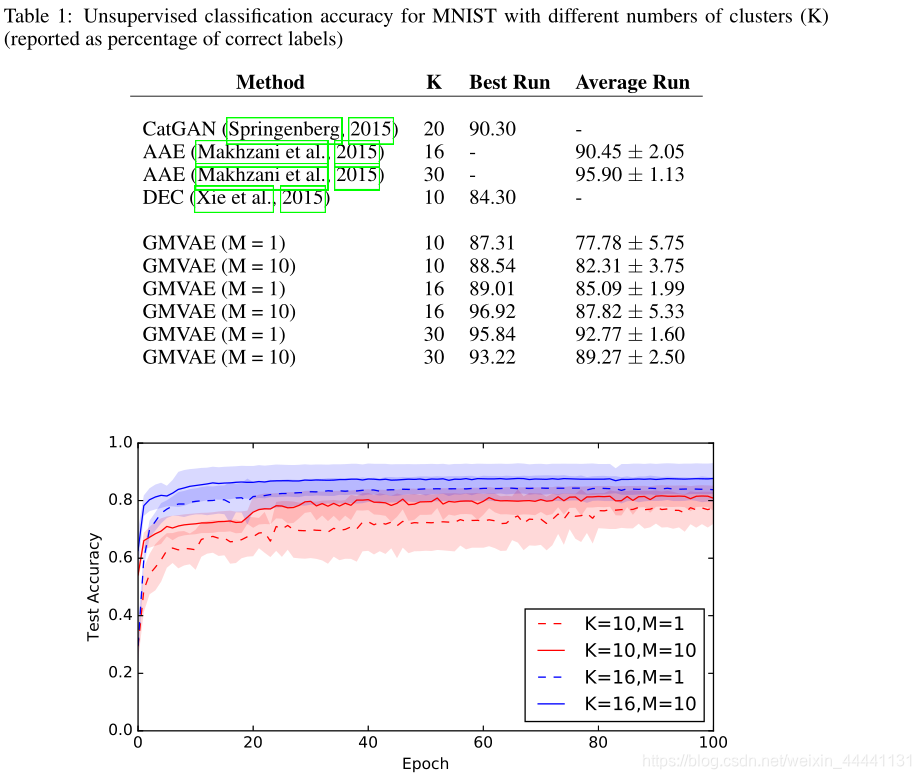
- 评估MNIST数据集上的无监督聚类任务
- 展示实验效果

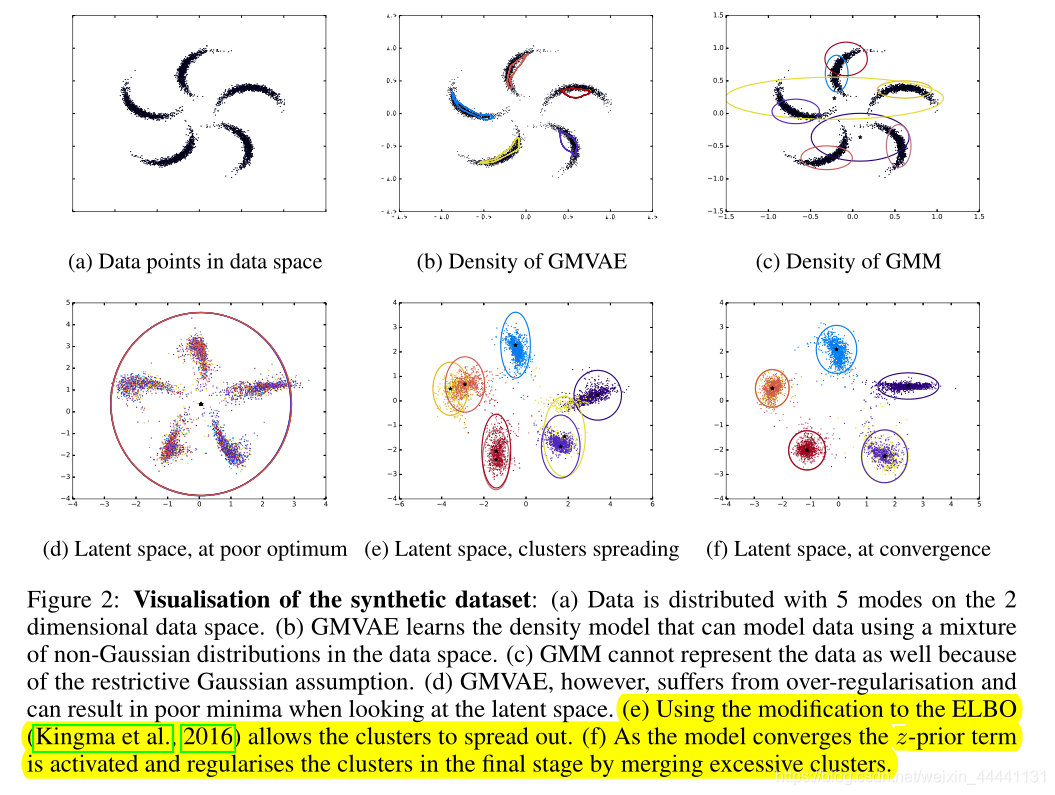
4.1 SYNTHETIC DATA



- 重点看d、e、f
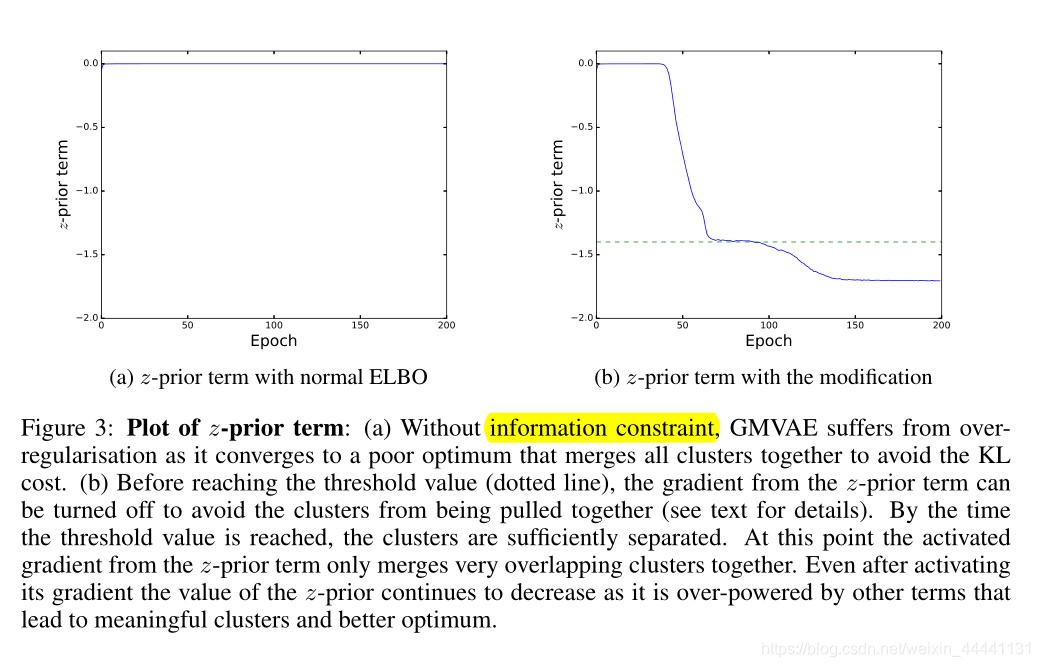
4.2 UNSUPERVISED IMAGE CLUSTERING
-
值得注意的是,作者在MNIST数据集上并没有发现over-regularisation的问题,所以没有使用minimum information constraint方法
-
准确率计算:我们找到测试集合中具有最高概率属于聚类i的元素,并将该标签分配给属于i的所有其他测试样本。然后,对所有群集i=1,.,K重复这一过程,并且将所分配的标签与真实标签进行比较,以获得非监督分类错误率。
-
举个例子在所有样本中,样本k属于聚类1的概率最高,查看样本k的标签,并将该标签赋给所有归属于聚类1的样本。在聚类1中,观察样本与真实标签的误差。以此类推,聚类2,聚类3…,聚类10

以下是我自己总结的数据流图,是本实验代码的数据流。

4.2.1 IMAGE GENERATION


5. 回顾之前提出的问题
5.1 什么是over-regularisation,如何解决?
- 在VAE中指的是正则化项过于强大,,使模型陷入了局部解,这个问题经常会发生在训练初期

- 使用minimum information constraint方法,为其加入一个最小阈值λ,使得在训练初期模型不要陷入局部解。

5.2GMVAE使怎么聚类的?
- 其实就是GMM模型的聚类思想,理解响应度,就理解了如何聚类。其实顺便一提,这里作者将K设置为10,制作者并没有从理论上证明10分类问题一定可以映射到对应的component上,只是实验效果还不错。