最近看了一篇利用强化学习进行存储性能调优的论文,写一下读后感
什么是参数调优
针对某一设备上正在运行的某一工作负载,不断调整某些参数的值,使得设备可以达到最优的性能,参数调优不会改变硬件、源代码和应用程序。典型的参数一般有:I/O队列深度、RPC速率限制、线程数量和缓冲区大小等。
传统的参数调优存在的问题
传统的参数调优是一份十分具有挑战性的工作,而且成本较高:
- 每个系统、每个工作负载之间是不同的
- 硬件/软件缺陷
- 设备年限
- 需要雇佣领域专家来做这些工作
- 找到最优的设置是一个漫长的反复试验的过程
- 没人能做到7*24小事不间断的参数调优
同时,基于模型的方法通常不具备实操性:
- 不同的硬件/软件需要不同的模型来解决
- 没有足够的资源来维护这些模型
因此,必须找到一种新的解决方案
理想的自动化参数调优系统
- 面临的挑战
- 很难将参数变化与性能变化关联起来
- 参数空间巨大
- 目标
- 最优解是可定制的
- 可以在线训练
- 特点
- 可以对大范围的参数进行调优
- 模型数量很少
- 不需要提前了解系统或工作负载如何运行的
- 可以在多种系统上工作
- 极短的训练时间
- 稳定
- 不间断工作
用深度强化学习进行参数调优
CAPES
CAPES:Computer Automated Performance Enhancement System
上层架构
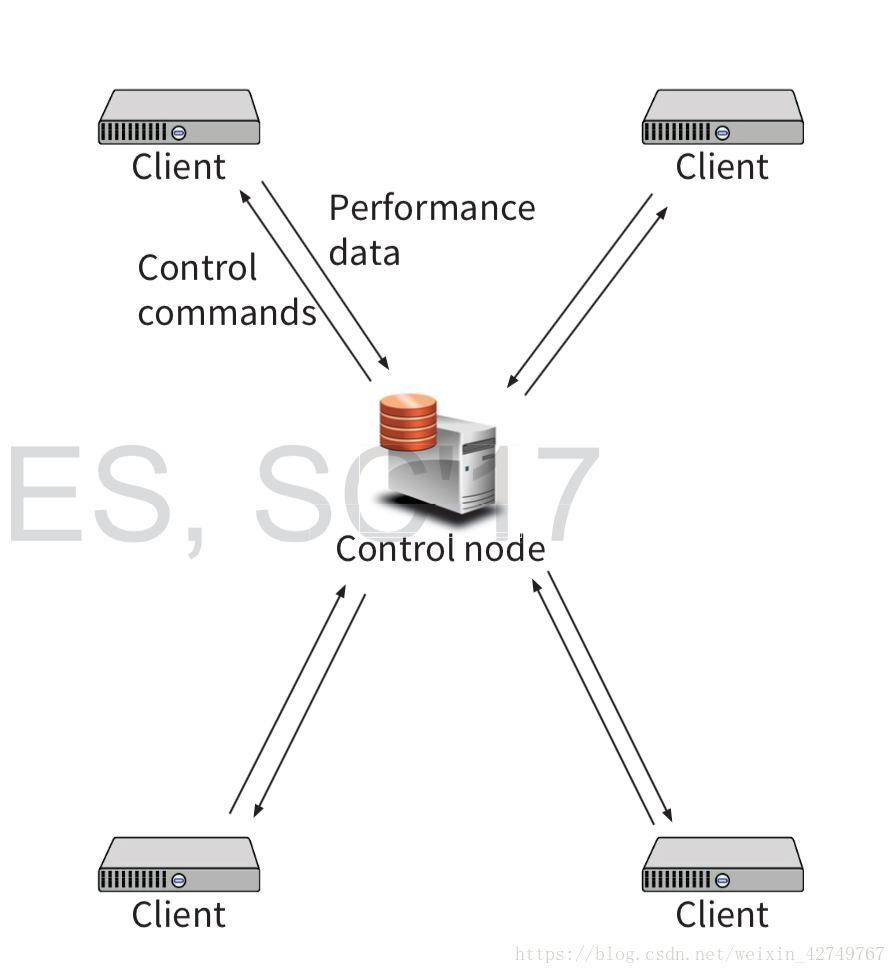
如图所示,整个架构的核心是控制节点,其与多个客户端相连接,调整参数并用控制命令发给客户端,然后收集参数修改后的性能数据
将强化学习应用到参数调优中
问题的关键在于找出Value function,文中采用了Q-function,即Deep Q-Learning(DQL),类似于经济学中的贴现函数
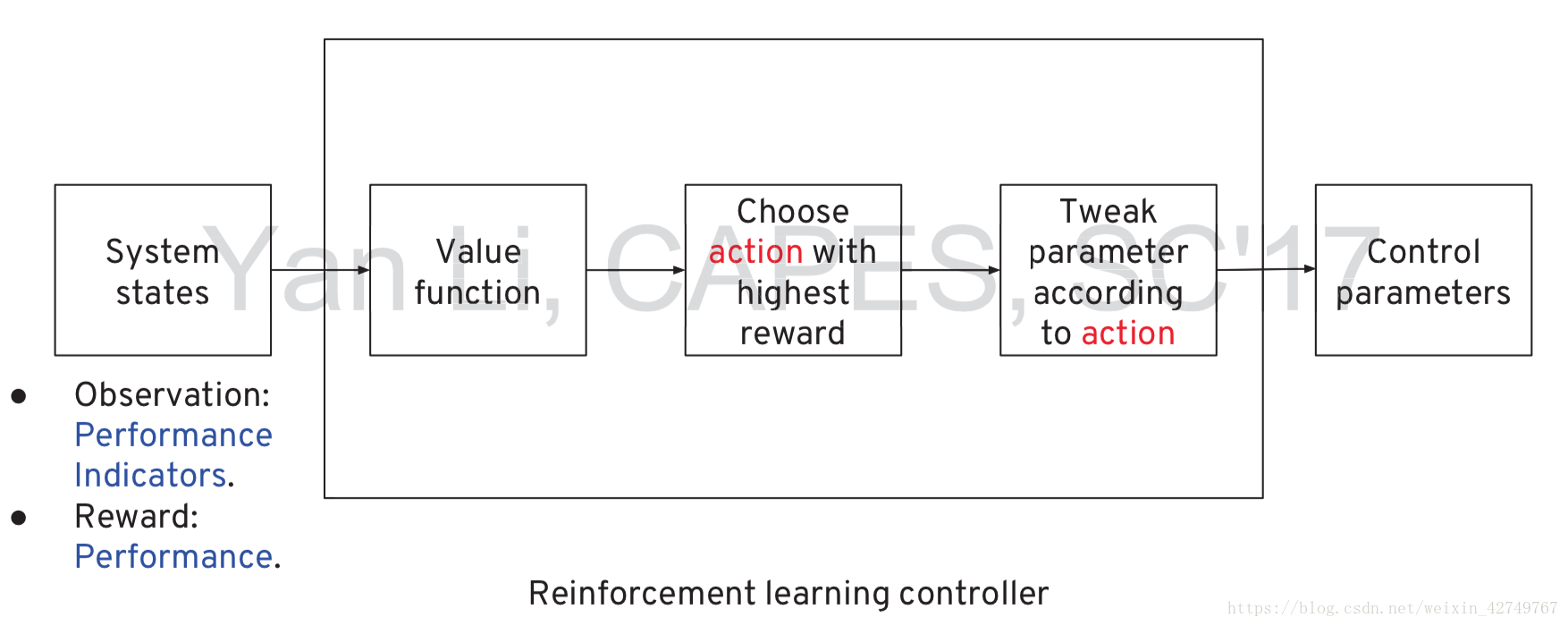

至于为什么采用Q函数,文中给出了解释:
首先,强化学习存在一些挑战:
- 在动作和奖励之间有着比较长且不确定的延迟时间
- 需要大量的数据进行训练
- 训练期间的性能表现是不可预测的
而DQL具有以下优势:
- 可以在多维非线性系统上工作
- 可以将有噪声的原始数据作为输入
- 可以解决动作和奖励之间的延迟问题
- 不需要模型
- 可以在线无监督训练
最后作者将CAPES用于Lustre文件系统,并定义了一些性能指标用于观察,做了一些实验得出了结论
感受
联想到老师最近提的调度框架,我认为整体的思路应该和文中相似。首先,我们应该对应用进行分析,可以提取一系列用于表征应用的特征作为输入,类似于CAPES中系统的状态,这个一方面需要高度抽象,一方面应该也是可定制的。我们的优化目标比较明确,就是让处理时间缩短,尽量让所有节点同时完成,除掉整个系统短板。最后就剩下中间的调度框架,还需要查阅更多的资料,做进一步调研。