文章目录
写在前面
这个论文讲聚类的准确率拉到一个非常高的值,所以,我们重点看一下方法,该论文的实验部分非常难,不重点讲
摘要
- 为了解决聚类,将GMM应用再VAE的先验上;为了解决复杂扩散的数据问题,应用了图嵌入。论文的想法是,捕获局部数据结构的图信息是对深度GMM的极好补充,将deep GMM和Graph Embedding结合起来有助于网络学习遵循全局模型和局部结构约束的强大表示。
- 因此,论文方法整合了基于模型和基于相似度的聚类方法,为了将概率deep GMM和graph embedding结合起来,文中提出了图嵌入的一种新的随机扩展:我们将样本作为图的结点,并最小化其后验分布之间的加权距离,我们用JS散度作为距离度量。
- LOSS:将JS散度最小化和deep GMM的log-likelihood最大化结合起来作为模型的损失函数
- 实验效果很好,比之前说过例如GMVAE,VaDE等效果都好
- 我们的结果突出了本文提出的基于模型的聚类和基于相似性的聚类相结合的优势
- 代码:https://github.com/dodoyang0929/DGG.git

1. 介绍
- 根据空间结构建模方法的不同,大多数聚类方法可以分为两类:分别是基于模型的方法和基于相似度的方法。
- 基于模型的方法(例如GMM),它们关注于数据空间的全局结构;它们对整个数据空间进行假设,并且使用一些特定的模型对数据进行拟合;它的一个显著优点就是良好的泛化能力;然而,这种方法有个很大的挑战就是:如何去处理具有复杂分布的数据
- 基于相似度的方法,它强调数据的局部结构。这些方法利用样本之间的某些相似性或距离来形成局部结构。然而,这种方法在高计算复杂度的时候,表现很差
2. 相关工作
- 与我们的工作最相关的工作是VADE。VADE和我们的工作都学习了潜在特征的高斯混合模型。然而,区别是明显和显著的:我们的方法应用图嵌入来保存数据的局部结构。具体地说,在VADE中,潜在特征的分布是独立学习的。另一方面,在我们提出的方法中,如果训练样本在样本相似图上是相连的,则我们将训练样本的潜在分布推近到彼此之间。在图的帮助下,我们提出的方法能够学习强大的表示和处理复杂扩散的数据。实验结果表明,我们提出的方法优于VADE。

3. DGG
3.1 深度高斯混合模型(Deep GMM)
这里比较简单,其实就是前面我们将聚类博客的一个抽象,这里不讲了



3.2 图嵌入的VAE
-
图嵌入目的在于找到数据的低维特征,这些特征保存了样本相似图中结点对之间的相似关系。一般,在图嵌入中,训练样本会被看作为相似图中的结点,其中相似图被看作为邻接矩阵。最优的特征可以从求解下面公式得到:
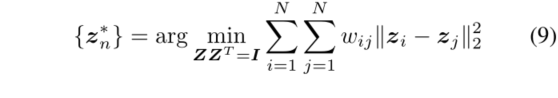
我们可以看到,如果样本在图中是连接的,它们的特征将会很近。这启发我们:假如两个数据样本在图中相连接,那么它们也应该有相似的隐空间特征和聚类分配值。我们建议用后验分布的距离来衡量样本之间的相似性,所以我们就有了损失函数:
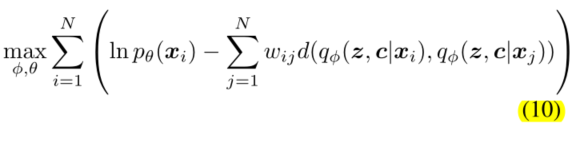
为了平衡样本的权重信息,我们有: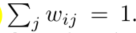
-
后验分布之间的距离度量的选择很重要,这篇文章选择了JS散度作为相似度的度量,则损失函数变为:

3.2.1 学习算法
这一小节,讲如何去求解公式11? 我们没有选择直接去优化JS散度,而是优化了JS散度的变分上界
本小节涉及大量公式推导,本人已经推到过,不难,所以在这里不在详细阐述,在这里贴出来供大家参考






3.3 构建邻接矩阵
- 和其他图嵌入方法相似,正确构建一个邻接矩阵是非常重要的。一般构建邻接矩阵地方法是:对于一个给定的样本数据点,找到它邻居的集合,然后用提前定义好的核函数去计算它们之间的相似性。例如,对于高斯核函数,元素的邻接矩阵被定义为:

- DGG

4. 实验
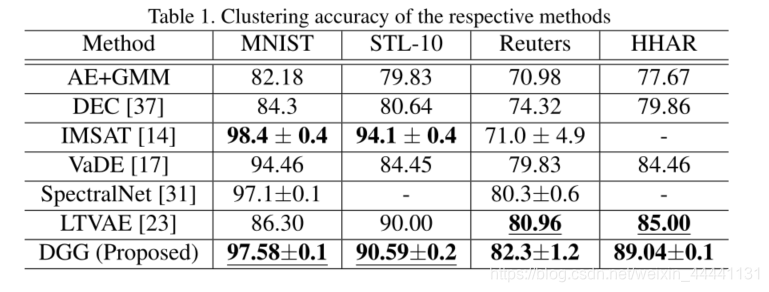

5. 结论
1.提出DGG模型,它结合了deep GMM和graph embedding各自的优点和特性
2.提出了随机图嵌入的方法,对图上相连的样本对进行正则化处理,使它们具有相似的后验分布
3.相似度通过JensonShannon(JS)散度来衡量,并导出了一个上界来实现有效的学习
4.该方法优于基于深度模型的聚类和深谱聚类
5.未来的工作是研究GAN鉴别器的扩展