写在前面
这是一篇准备发表在IEEE上的文章(应该现在还没发表),2020.05已经发表在了ArXiv上了,是一篇关于深度聚类的文章,文章的思想很简单。
摘要
- 在这项研究中,我们提出了一种深度聚类算法,它是k-means算法的一种扩展。
- 每个聚类由自动编码器表示,而不是由单个质心向量表示(传统K-means使用的方法)。
- 每个数据点与产生最小重建误差的自动编码器相关联。通过学习一组最小化全局重构均方误差损失的自动编码器来找到最优聚类。
- 网络结构异常简单明了。
- 该方法在标准图像语料库上进行了评估,其性能与基于复杂得多的网络体系结构的最新方法不相上下(并没有说优于,也确实如此)。

1. 介绍
k-Means的深度版本是基于学习一种非线性的数据表示,并在嵌入空间(Embedding Space)中应用k-Means
然后,如果我们直观的直接去实现这种深度的K-Means,我们会陷入鞍点局部解:所有的数据点都会在嵌入空间中崩塌成一个点(有点模式崩塌的意思)
所以,为了避免数据崩塌,很多深度聚类算法都会在嵌入空间中加入一些正则项(对重构项进行正则化)
Deep Embedded Clustering(DEC)[12]首先使用自动编码器重构损失进行预训练,然后通过Kullback-Leibler散度损失来优化嵌入空间中的聚类质心。
(Our method)与DEC类似,在第一阶段,会用一个AE来进行预训练,来重构所有数据;与DEC不同的是,在第二阶段,使用自动编码器重构损失和k均值聚类损失函数的数学组合来联合训练网络(DEC在第二阶段的损失函数只有KL散度)。
这里我们提出了一种深度聚类算法,算法中,每个聚类被一个AE表示,并且通过将数据点分配给最佳重构输入的自动编码器来执行聚类本身。
这种算法属于深度K-means聚类的一个变种吧(而不是K-means的变种)


2. K-DAE
在我们的方法中,我们不是用质心来表示集群,而是用专门重构属于该集群的对象的自动编码器来表示每个集群。如果数据集被正确的聚类了,我们希望分配给同一簇的所有点都是相似的。因此,使用多个AE肯定要比对整个数据集使用单个AE要好。
聚类的准则:聚类本身是通过将每个点分配给最佳重建它的自动编码器来执行的(请仔细品这句话,很重要,后面实验部分也是这样展示了,可以直接跳到实验部分(看图)看看理解这句话)
接下来,来看看损失函数,直接看文章,很简单,读一下就懂了。需要理解一点的是:我们可以把K-Means中的聚类中心等价理解为我们模型里的AE。K-Means是让所有数据到各自的类中心的距离和最小,而K-DAE是让所有数据经过各自的AE后得到的重构误差最小,这是K-Means和深度学习之间的联系


K值如何选择:K值得选择是个很难得问题,一般我们都需要手动选择。常用得方法有Elbow“手肘法”(吴恩达K-means里讲过),还有silhouette method(这个不太懂)。作者也把这些方法运用在了K-DAE上,以此来选择K值

作者指出,参数得初始化是至关重要的:
第一步:对整个数据集使用单个的AE,通过重构误差来训练这个AE的参数
第二步:经过第一步后,我们在训练好的数据的嵌入空间中运用K-means算法去获取初始的聚类值(相当于标签值)
第三步:由k-Means算法分配给第i个群集的点接下来被用来预训练第i个自动编码器fi(x;θi)
一旦参数初始化结束,我们就可以通过公式(1)来优化整个网络,网络的结构图如下:
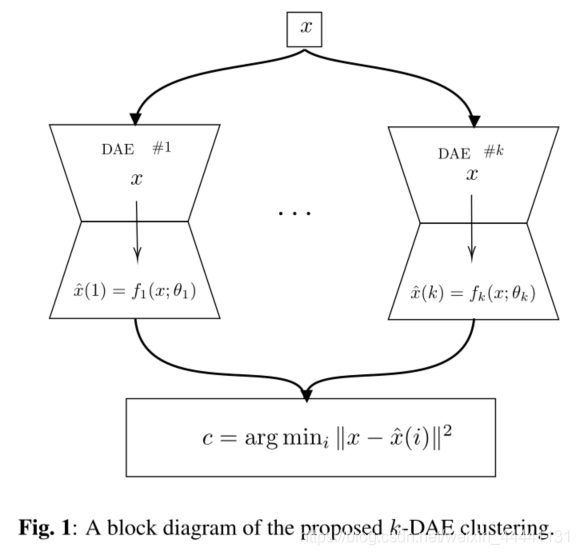
算法总结:(清晰明了)

3. 实验
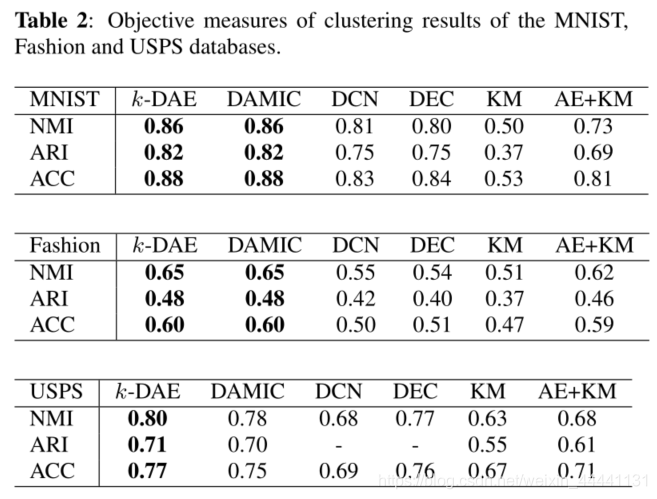
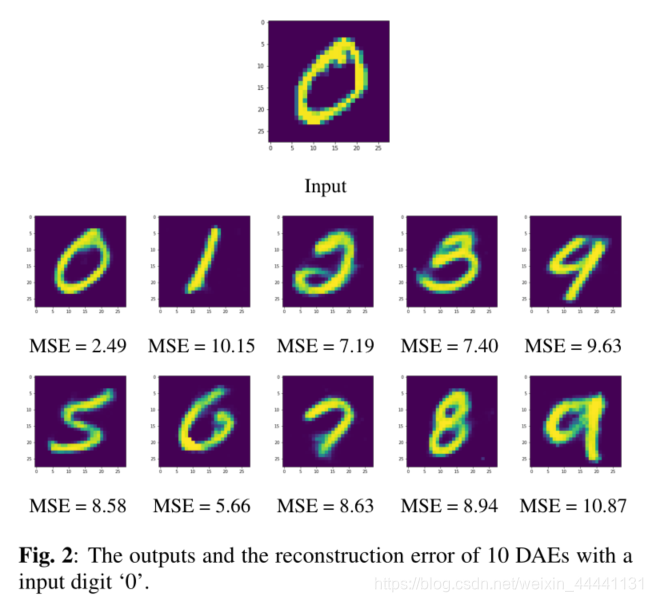
看到上面这个图,赶紧回到第二节讲的聚类准则,你会理解更深
4. 结论
文中的总结部分没啥说的,大白话