Deep Multimodal Subspace Clustering Networks 翻译
摘要
我们提出了基于卷积神经网络(CNN)的无监督多模态子空间聚类方法。所提出的框架包括三个主要阶段 - 多模态编码器,自我表示层和多模态解码器。编码器将多模态数据作为输入并将它们融合到潜在空间表示中。自我表达层负责实施自我表示属性并获取对应于数据点的亲和度矩阵。解码器重建原始输入数据。网络在训练中使用解码器重建与原始输入之间的距离。我们研究了早期,晚期和中间融合技术,并提出了三种不同的编码器,用于空间融合。对于不同的基于空间融合的方法,自我表示层和多模态解码器基本相同。除了各种基于空间融合的方法之外,还提出了基于亲和融合的网络,其中对应于不同模态的自表示层被强制为相同。对三个数据集的广泛实验表明,所提出的方法明显优于最先进的多模态子空间聚类方法。
引言
图像处理,计算机视觉和语音处理中的许多实际应用需要处理非常高维的数据。 但是,这些数据通常位于低维子空间中。例如,具有照明[1]变化的面部图像,手写数字[2]和视频[3]中刚性运动物体的轨迹是高维数据可以由低维子空间表示的示例。 子空间聚类算法基本上使用这个事实来在数据集中的不同子空间中找到聚类[4]。 换句话说,在子空间聚类任务中,给定来自子空间并集的数据,目标是找到子空间的数量,它们的维数,数据的分段以及每个子空间的基[4]。这个问题在包括运动分割[5],无监督图像分割[6],图像表示和压缩[7]以及面部聚类[8]等方面有很多应用。
文献[9],[10],[11],[12],[13],[14],[15],[16],[17],[18]中提出了各种子空间聚类方法。 特别是,基于稀疏和低秩表示的方法近年来获得了很大的吸引力[19],[20],[14],[15],[21],[22],[23],[24]。 这些方法利用了子空间并集中的无噪声数据是自我表达的事实,即每个数据点可以表示为其他数据点的稀疏线性组合。 最近在[16]中研究了自我表示特性,以开发用于子空间聚类的深度卷积神经网络(CNN)。 这种基于深度学习的方法显示出明显优于最先进的子空间聚类方法。
在数据由多个模态或视图组成的情况下,可以采用多模态子空间聚类方法根据其子空间同时聚类各个模态中的数据[25],[26],[27],[28], 29],[30],[31],[32],[33],[34]。 一些多模态子空间聚类方法利用内核技巧将数据映射到高维特征空间,以实现更好的聚类[34]。
深度子空间聚类的最新进展[16]以及使用CNN的多模态数据处理[35],[36],[37],[38],[39],[40],[41],[42 ],[43],在本文中,我们提出了一种解决多模态子空间聚类问题的不同方法。 我们提出了一种新颖的基于CNN的自动编码器方法,其中在编码器和解码器之间引入了完全连接的层,其模仿了在各种子空间聚类算法中广泛使用的自表达性。
图1概述了所提出的深度多模态子空间聚类框架。 自我表达层负责实施自我示属性并获取对应于数据点的亲和度矩阵。 解码器从潜在特征重建原始输入数据。 网络在训练中使用解码器重建与原始输入之间的距离。
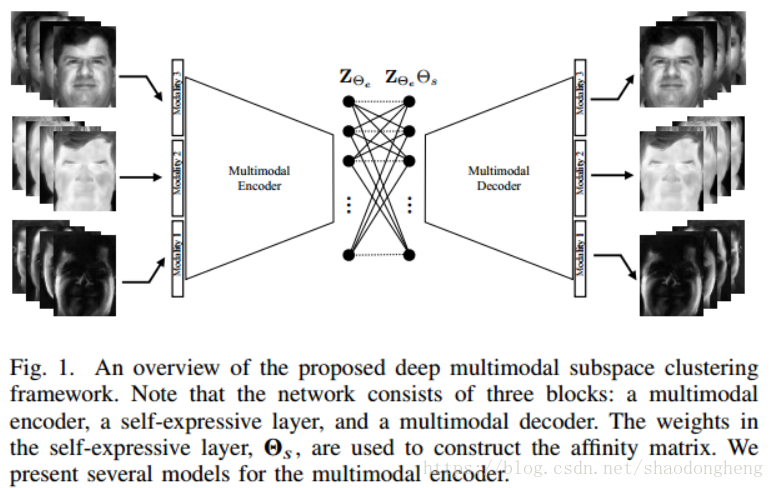
图1. 所提出的深度多模子空间聚类框架的概述。 注意,网络由三个块组成:多模态编码器,自表达层和多模态解码器。 自表达层中的权重Θs用于构建亲和度矩阵。 我们提出了多模态编码器的几种模型。
为了将多模态数据编码成潜在空间,我们研究了基于晚期,早期和中间融合的三种不同的空间融合技术。 这些融合技术的动机是监督学习任务中的深度多模态学习方法[44],[45],它们提供跨空间位置的模态表示。 除了空间融合方法之外,我们还提出了一种基于亲和力融合的网络,其中对应于不同模态的自我表达层被强制为相同。 对于基于空间和基于亲和力融合的方法,我们制定端到端训练目标损失。
我们工作的关键贡献如下:
提出了基于深度学习的多模态子空间聚类框架,其中通过使用全连接层在潜在空间中编码自我表示属性。
针对融合多模态数据,提出了对应于晚期,早期和中间融合的新型编码器网络架构。
提出了一种基于亲和融合的网络体系结构,其中强制执行自表达层以在所有模态的潜在表示上具有相同的权重。
据我们所知,这是第一次尝试将深度学习用于多模态子空间聚类。 此外,所提出的方法获得了各种多模态子空间聚类数据集的最新结果。
代码:https://github.com/mahdiabavisani/Deep-multimodal-subspace-clustering-networks
本文的结构如下。 有关子空间聚类和多模态学习的相关工作见第二节。 基于空间融合和亲和融合的多模态子空间聚类方法分别在第III和IV节中给出。 实验结果见第五节,最后,第六节总结了本文的简要总结。
相关工作
本节我们回顾一些子空间聚类和多模态学习的相关工作。
A. Sparse and Low-rank Representation-based Subspace Clustering
令是从
中的维度为
的n个线性子空间
的并集绘制的N个信号
的集合。 给定X,子空间聚类的任务是找到位于
的子矩阵
,其中
。稀疏子空间聚类(SSC)[19]和基于低秩表示的子空间聚类(LRR)[20]算法利用了子空间并集中的无噪声数据是自我表示的这一事实。 换句话说,假设每个数据点可以表示为其他数据点的线性组合。 因此,这些算法旨在通过解决以下优化问题来找到稀疏或低秩矩阵C.
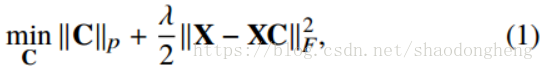
其中是SSC [19]的1范数和LRR [20]的核范数。 这里,λ是正则化参数。 另外,为了防止平凡解
,在SSC的情况下,将上述
的附加约束添加到上述优化问题中。 一旦找到C,就将谱聚类方法[46]应用于亲和度矩阵
,以获得数据X的分割。
非线性版的SSC和LRR算法也在文献[21],[22]中提出。
B. Deep Subspace Clustering
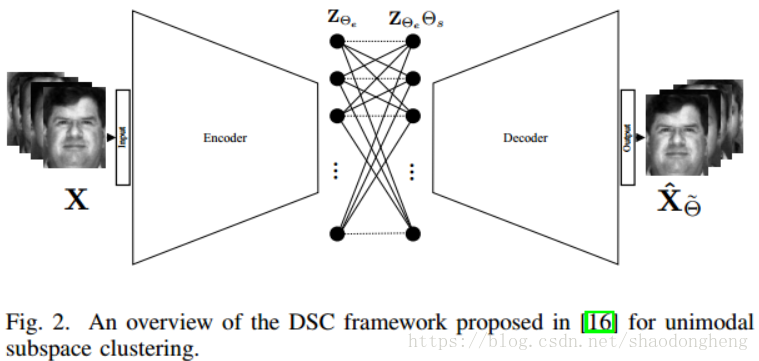
深子空间聚类网络(DSC)[16]通过使用编码器 - 解码器类型网络将数据嵌入潜在空间来探索自我表示性。 图2给出了单模态子空间聚类的DSC方法的概述。 该方法优化了类似于(1)的目标,但是使用嵌入在网络内的可训练密集层来近似矩阵C. 让我们将自表达层的参数表示为。 请注意,这些参数基本上是(1)中C的元素。 以下损失函数用于训练网络
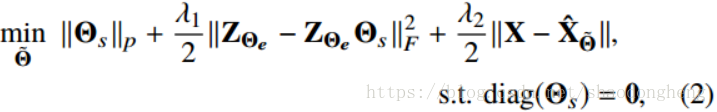
其中表示编码器的输出,
是解码器输出端的重构信号。 这里,网络参数Θ由编码器参数
,解码器参数
和自表达层参数
组成。 这里,λ1和λ2是两个正则化参数。
C. Multimodal Subspace Clustering
近年来已经开发了许多多模态和多视图子空间聚类方法。 Bickel等在[31]中介绍了期望最大化(EM)和凝聚多视图聚类方法。怀特等人 [30]提供了多视图子空间学习的凸重构,与局部形式相反,可以实现全局学习。一些算法使用降维方法(如典型相关分(CCA))将多视图数据投影到低维子空间进行聚类[26],[32]。其他一些多模态方法是专门为两个视图设计的,不能轻易推广到多个视图[47] [33]。库马尔等人 [27]提出了一种协同正则化方法,可以强制聚类在不同的视图中对齐。赵等人 [28]在一个视图中使用聚类输出来学习另一个视图中的判别子空间。最近在[24]中提出了一种多视图子空间聚类方法,称为低秩张量约束多视图子空间聚类(LT-MSC)。在LT-MSC方法中,所有子空间表示被集成到低秩张量中,其捕获多视图数据下的高阶相关性。在[48]中,提出了一种多样性诱导的多视图子空间聚类,其中利用Hilbert Schmidt独立性准则来探索多视图表示的互补性。最近,[49]提出了一种约束多视角视频人脸聚(CMVFC)框架,其中成对约束用于稀疏子空间表示和用于多模态人脸聚类的谱聚类过程。在[25]中提出了一种名为Multitask Low-rank Affinity Pursuit(MLAP)的协作图像分割框架。在该方法中,利用从多个特征矩阵的联合分解到稀疏和低秩矩阵对的稀疏约束的低秩亲和度来进行分割。
D. Deep Multimodal Learning
在多模态学习问题中,我们的想法是利用不同形式提供的补充信息来提高识别性能。监督深度多模态学习最早在[35],[36]中引入,近年来引起了很多关注[50],[51],[38]。
凯拉等人[44]研究了大规模数据集的深度多模态分类。 他们在准确性和计算效率方面比较了许多多模态融合方法,并提供了关于多模态分类模型可解释性的分析。 Feichtenhofer等[45]提出了一种用于两个流3D网络的卷积融合方法。 他们探索了深层架构中的多个融合功能,并研究了学习空间和时间特征图之间的对应关系的重要性。 文献中还提出了各种深度监督多模态融合方法,用于不同的应用,包括医学图像分析应用[52],[53]视觉识别[39],[38]和视觉问题回答[50],[41]。 我们引用读者[37]来更详细地研究各种深度监督多模态融合方法。
虽然大多数深层多模态方法都报告了监督任务的改进,但就我们所知,没有专门为无监督子空间聚类设计的深层多模态学习方法。
基于空间融合的深度多模态子空间聚类
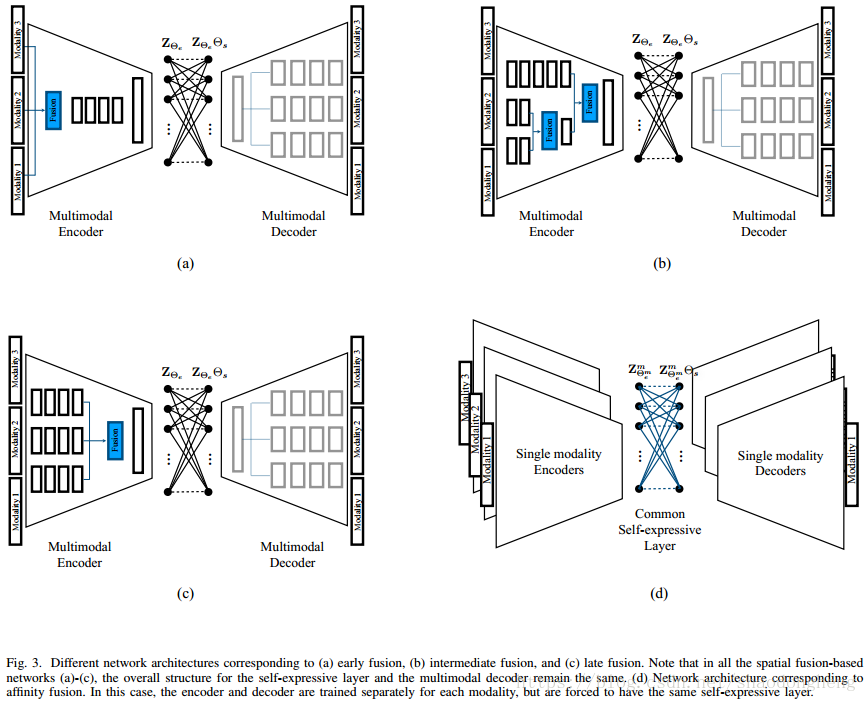
在本节中,我们提出了基于空间融合的无监督子空间聚类网络的细节。 空间融合方法找到包含来自不同模态的补充信息的联合表示。 联合表示与每种模态具有空间对应关系。 图4显示了空间融合的视觉示例,其中五种不同的模态(DP,S0,S1,S2,可见)被组合以产生融合结果Y.空间融合方法在受监督的多模态学习应用中特别流行[44],[45]。 我们研究将这些融合技术应用于我们的深子空间聚类问题。

这种方法的一个重要组成部分是融合函数,它融合来自多个输入表示的信息并返回融合输出。 在深度网络的情况下,融合网络选择的灵活性导致不同的模型。 接下来,我们研究了多模子空间聚类的几种网络设计和空间融合函数。 然后,我们为提出的网络制定端到端的训练目标。
A. Fusion Structures
我们基于[16]中提出的用于单模态子空间聚类的架构来构建深度多模态子空间聚类网络。 我们的框架由三个主要组件组成:编码器,完全连接的自我表达层和解码器。 我们建议使用编码器实现空间融合,然后将融合的表示送到自我表达层,该自我表达层基本上利用联合表示的自我表达性质。 然后将由我自表达层的输出产生的联合表示馈送到多模态解码器,自我表示层输出的的联合表示结果输入到多模态解码器,从联合潜在表示中重建不同的模态。
对于M个输入模态的情况,解码器由M个分支组成,每个分支重建一个模态。另一方面,编码器可以设计成使得它们实现早期,晚期或中间融合。早期融合是指在将多模态数据馈送到网络之前将其集成在特征级别的阶段。另一方面,后期融合涉及在网络的最后阶段中集成多模态数据。深度网络的灵活性还提供称为中间融合的第三类融合,其中来自网络的中间层的特征映射被组合以实现更好的联合表示。图3(a),(b)和(c)给出了具有不同空间融合结构的深多模子空间聚类网络的概述。注意,在所有三种情况下,多模式解码器的结构保持不变。值得一提的是,在中间融合的情况下,通常的做法是在早期阶段聚合弱或相关的模态,并在深度阶段结合剩余的强模态[37]。
B. Fusion Functions
假设对于特定数据点xi,存在对应于不同模态的表示的M个特征图。 融合函数融合M个特征映射并产生输出z。 为简单起见,我们假设所有输入特征图具有相同的尺寸
,并且输出具有
的尺寸。 事实上,深层网络结构提供了具有相同尺寸的特征图的设计选项。 我们用
表示分别在输出和第m个输入特征图中的空间位置
。 可以使用各种融合函数来组合输入特征映射。 下面,我们调查一下。
1)sum融合:计算相同特殊位置的特征映射之和,如下所示
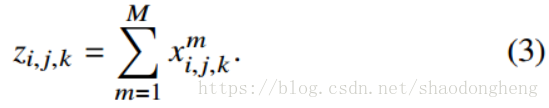
2)Maxpooling函数返回输入要素图中相应位置的最大值,如下所示
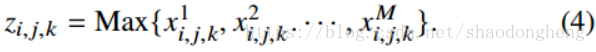
3)Concatenation函数通过连接输入要素图来构造输出,如下所示
其中每个输入的尺寸为,输出的尺寸为
。 注意,这些融合函数在图3(a) - (c)的蓝色框中表示为“Fusion”。
C. End-to-End Training Objective
给定来自M个不同模态的N个成对数据样本,将相应的数据矩阵定义为
。 无论网络结构和选择的融合函数如何,让
表示多模态编码器的参数。 类似地,令
为自表达层参数,并且
为多模态解码器参数。 然后,可以使用以下损失函数对所提出的空间融合模型进行端对端训练
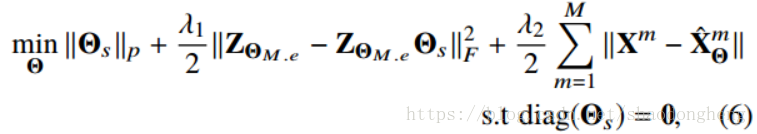
其中Θ表示所有训练网络参数,包括,
和
。 联合表示由
表示,并且
是
的重建。 这里,λ1和λ2是两个正则化参数,并且
可以是1或2范数。
基于亲和融合的深度多模态子空间聚类
在本节中,我们提出了一种新的方法,用于融合数据模型之间的亲和力,以实现更好的聚类。 空间融合方法需要对齐来自不同模态的样本(参见图4)以实现更好的聚类。 相反,所提出的亲和融合方法结合了来自自表达层的相似性以获得多模态数据的联合表示。 这是通过强制网络具有联合亲和度矩阵来完成的。 这避免了对齐数据或增加融合输出的维度(即连接)的问题。 强制执行共享亲和度矩阵的动机是,一种模态中的类似(不相似)数据在其他模态中也应相似(不相似)。 图5展示出了通过强制模态共享相同的亲和度矩阵而提出的亲和融合方法的示例。
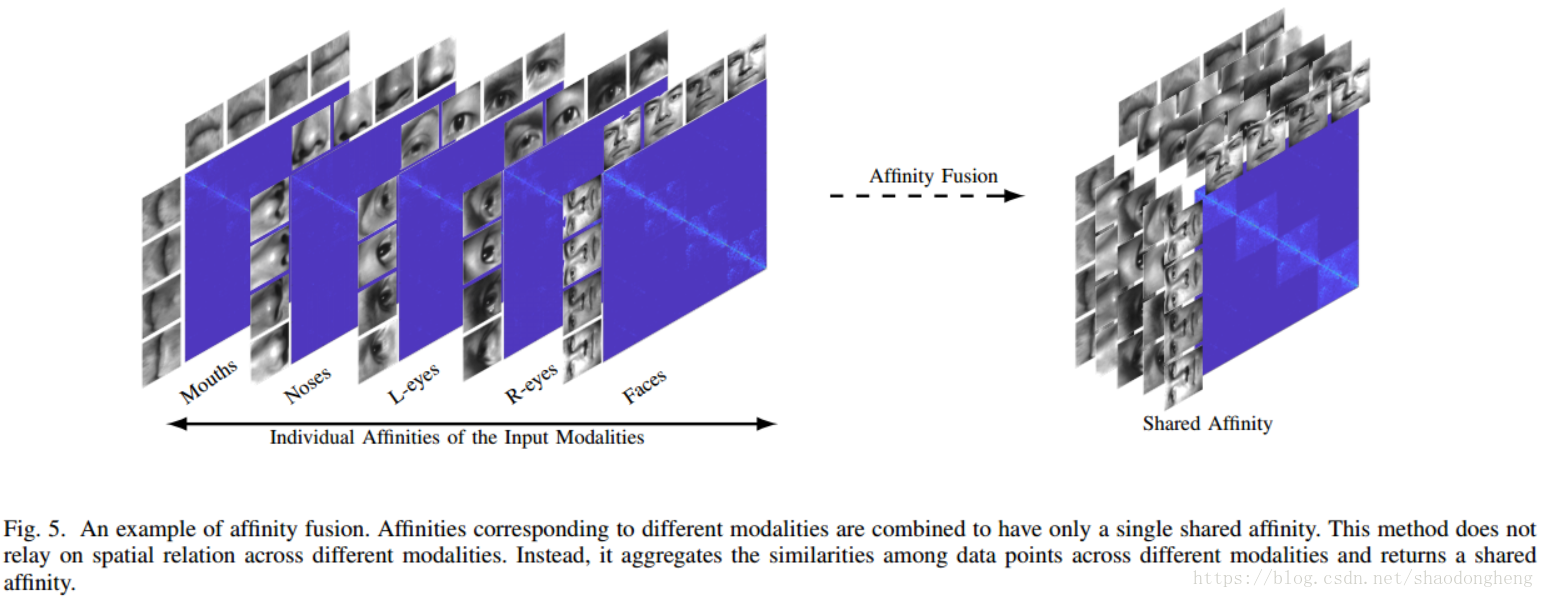
在DSC框架[16]中,如下从自表达层权重计算亲和度矩阵
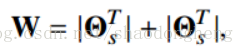
其中对应于端到端训练策略所学习的自我表现层权重[16]。 因此,共享的
在整个模态中产生共同的W. 我们强制执行共享
的模态,同时具有不同的编码器,解码器和潜在表示。
A. Network Structure
对于M模态问题,我们建议堆叠M个并行DSC网络,它们共享一个共同的自我表达层。 在该模型中,根据每种模态训练一个编码器 - 解码器网络。 与空间融合模型相反只有一个联合潜在表示,该模型导致M个不同的潜在表示对应于M个不同的模态。 通过共享自我表达层将潜在表示连接在一起。 最佳的自我表示层应该能够在所有M模态中共同利用自我表示属性。 图3(d)给出了所提出的基于亲和融合的网络架构的概述。
B. End-to-End Training
我们建议通过训练网络来找到共享的自我表达层权重,具有以下损失
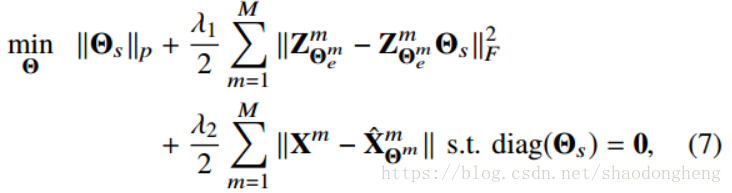
其中是公共的自我表达层的重量。 这里,λ1和λ2是正则化参数。
分别是潜在空间表示和对应于
的重构解码器输出。
表示对应于第m模态的网络参数,Θ表示所有可训练参数。 最小化(7)鼓励网络学习共享相同亲和度矩阵的潜在表示。
算法1总结了所提出的基于空间融合和亲和融合的子空间聚类方法。 本文中使用的不同网络架构的详细信息在附录VI中给出。

实验结构
我们在几个真实世界的多模态数据集上评估了所提出的深度多模子空间聚类方法。 我们的实验中使用了以下数据集。
。。。。
Structures:我们使用相同的协议和网络架构在不同的数据集上执行所有实验,以确保公平和有意义的比较(包括单一模态实验的网络)。所有编码器都有四个卷积层,解码器堆叠三个解卷积层,模仿编码器的逆任务。网络详细信息在附录中给出。对于空间融合实验,在早期融合的情况下,我们将融合函数应用于像素强度,并且网络的其余部分类似于单模态深度子空间聚类网络。进行中间融合的实验使用关于模态重要性的先验知识。它们将弱模态集成在第二个隐藏层中,然后将它们组合在第三层中。最后,所有弱模态的融合与第四层中的强模态(例如ARL数据集中的可见域)相结合。在后期融合的情况下,所有模态都融合在编码器的第四层中。如前所述,在亲和融合方法中,存在编码器 - 解码器和每个可用模态的潜在空间。例如,在具有5种模态的ARL数据集的情况下,我们有5个不同的编码器和解码器与共享的自表达层连接。对于具有共享亲和力的实验中的每种模态,我们使用与DSC网络[16]的情况类似的编码器 - 解码器和单模态实验。
Training details: 我们用Tensorflow-1.4 [58]在Python-2中实现了我们的方法。 我们使用自适应动量梯度下降法(ADAM)[59]来最小化我们的损失函数,并应用的学习率。所有模态的输入图像被调整为32×32,并重新调整像素值为0到255.在我们的实验中,Frobenius范数(即p = 2)用于训练网络时的损失函数(2),(6)和(7)。 与[16]类似,对于具有自我表达层的所有方法,我们在没有自我表达层的数据集上的预训练阶段之后开始对每个模型中的特定的目标函数进行训练。 特别是,对于所有提出的深度多模态子空间聚类方法,以及单个模态实验中的单模态DSC网络,我们预先训练编码器解码器以20kepochs训练以下目标
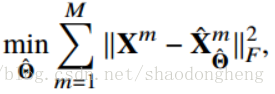
其中Θ表示编码器和解码器网络中参数的并集。 注意,对于单模态实验,M = 1。
我们在所有实验的预训练阶段使用100的batch size。 但是,一旦我们开始训练自我表示层,该方法就需要将所有数据点作为批处理方式提供。 因此,在使用数字,ARL脸和耶鲁B面部组件的实验中,批量大小分别为2000,2160和2432。 我们将正则化参数设置为λ1= 1和,,其中K是数据集中的目标数。 已经发现该实验规则在[16]中也是有效的。 对范围的敏感性分析
在第V-E节中,表示如果λ1和λ2与我们的选择保持大致相同的比例,则对于一组宽范围,所提出的方法的性能对这些参数不是很敏感。