目录
Mini-batch梯度下降
- Batch vs. mini-batch 梯度下降
之前我们都是遍历完训练集中的所有样本才进行一次梯度下降迭代,这就是Batch梯度下降。当训练集样本数m非常大时,每次梯度下降都遍历一遍所有样本的效率会很低。我们一般会使用Mini-batch梯度下降来提高训练效率。如图所示,Mini-batch梯度下降就是将训练集分为若干个子集,即若干个mini-batch,遍历完一次子集就进行一次梯度迭代,遍历完所有的mini-batch称为一个epoch.注:代表第t个mini-batch。

- mini-batch 梯度下降原理
使用batch梯度下降时,完整遍历一遍数据集计算一次代价函数,进行一次梯度下降迭代,多次迭代所绘制的代价函数会呈现单调递减的趋势;使用mini-batch梯度下降时,遍历一个mini-batch计算一次J,进行一次梯度下降迭代,由于在一次epoch中(有很多个不同的mini-batch),每次计算J使用的样本是不相同的,每个mini-batch都要计算一次J,可能第一个mini-batch 计算的比较小,第二个mini-batch 计算的比较大,因此多次迭代所绘制的代价函数会出现波动,但是整体还是呈现下降趋势。

- 选择合适的mini-batch大小
我们先考虑两种极端情况。当mini-batch大小等于训练集样本数m时,则退化成了batch 梯度下降,噪声会比较小,梯度下降过程比较平稳,可以比较直接的收敛到全局最小值;当mini-batch大小等于1时,则退化成了随机梯度下降,每次只考虑一个样本,丢弃了所有向量化所带来的加速效果,噪声会比较大,梯度下降过程波动比较大,虽然整体来说是朝最小值方向优化,但是随机梯度下降永远都不会收敛,而是在最小值附近波动。

所以在mini-batch梯度下降中,mini-batch大小不能过大也不能过小。它既可以利用向量化带来的加速效果,而且梯度下降过程波动比较小,并可以采用学习率衰减策略,使其收敛到全局最小值。它在实际使用中优化速度最快,使用最广泛,尤其是m比较大时。
当训练集样本数m比较小时,可直接使用batch 梯度下降;当m比较大时,一般选择2的幂次作为mini-batch大小,如64、128、256、512等。注意mini-batch size的选择一定要适应CPU/GPU的内存,mini-batch大小是深度模型中比较重要的一个超参数,需要在模型迭代过程中多次进行尝试,以找出使得优化效果最好的那一个。
指数加权平均
指数加权平均过程
如果我们想观察某种属性变化的大致趋势,一般的做法是做滑动平均,即取一个滑动窗口,如果窗口大小是10的话,第一天的气温就是在它之前的10天(包括第一天在内)气温的平均值,然后窗口进行滑动,第二天的气温就是在它之前的10天(包括第二天在内)气温的平均值(计算第1天到第9天的气温时可以进行填充)。
指数加权平均(指数加权移动平均)滑动平均的其中一种方法(这里以气温变化为例),公式如下:
,其中
是通过指数加权平均计算的第t天的气温,初始化
,
决定了计算某天的气温大约平均的天数,即滑动窗口大小大约为,
,
为第t天的真实温度。如取
,此时滑动窗口大小为10,计算过程以及此时得到的平滑后的曲线图(实际上是经过指数加权平均偏差修正后得到的)如下:

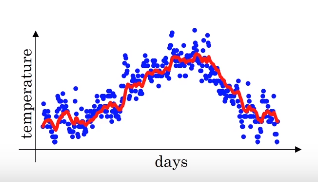
当取其它值时,如0.98,此时得到的曲线会非常平滑,因为它平均了大约50天的气温;当取0.5时,此时得到的曲线波动会比较大,但该曲线能很好的适应温度的变化,因为它只是大约平均了两天的气温。

指数加权平均原理
- 理解指数加权平均
为了便于分析,我们先将的公式展开:

实际上是前100天气温的加权求和,但是我们会发现上图中计算
时,使用的前100天的气温前的系数是呈现指数衰减的。
的系数是0.1,当这个系数变为初始系数0.1的1/e倍(0.35倍)时,在此之后系数会变得非常小,可以忽略不计,而
(重要极限:
),所以我们说当
时,大约平均了10天的气温。
- 指数加权平均实现
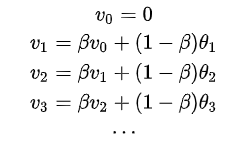
因为在计算当前时刻的平均值时,只需要前一天的平均值和当前时刻的值,所以在数据量非常大的情况下,指数加权平均在节约计算成本的方面是一种非常有效的方式,可以很大程度上减少计算机资源存储和内存的占用。
指数加权平均的偏差修正
如果利用得到的实际上不是图中绿色曲线,而是紫色曲线。这是因为指数加权平均刚开始计算时是不准确的,数值偏小,所以需要偏差修正。

偏差修正:,也就是对计算出来的
除以
进行偏差修正。正如上图所示,通过偏差修正,可以从紫线变为绿线。刚开始时修正效果比较明显,二者差距比较大,但随着t增大,
,二者几乎重合。

加快梯度下降
Momentum梯度下降法
无论是使用batch还是mini-batch梯度下降,每一次迭代所更新的代价函数值如图中蓝色线所示在上下波动,而这种幅度比较大波动,减缓了梯度下降的速度,而且我们只能使用一个较小的学习率来进行迭代(如果用较大的学习率,结果可能会如紫色线一样偏离函数的范围)。我们所希望的是在纵向上学习的慢一点,不想要那些摆动;在横向上加快学习,快速达到最小值,而使用动量梯度下降法就可以实现,如下图中红色线所示。

Momentum梯度下降法基本思想就是计算梯度的指数加权平均数,并利用该梯度来更新权重,算法实现如下:

在动量梯度下降过程中,由于使用了指数加权平均,原来在纵轴方向上的上下波动,经过平均以后,接近于0,纵轴上的波动会变得非常小;而在横轴方向上,所有的微分都指向横轴方向,因此其平均值仍然很大。
动量梯度下降的本质理解:可以把优化的代价函数想象成一个碗状,一个球从碗沿滚到碗底(最小值),球的运动轨迹就相当于梯度下降的迭代过程,上式中的梯度项dW,db相当于球运动的加速度,Momentum项相当于速度,小球在向下滚动的过程中,因为加速度的存在使得速度会变快,但是由于
的存在,其值小于1,可以认为是摩擦力,所以球不会无限加速下去。
RMSprop

RMSprop与Momentum一样都使用了指数加权平均,但RMSprop是将微分项进行平方,然后使用dW除以Sdw的平方根进行梯度更新(为了避免分母为0,平方根分母中会加入一个很小的值如)。设纵向代表的是参数W,dW有正有负且比较大,对其求平方,那么得到的Sdw也比较大,所以在对参数进行更新时,我们让dW除以Sdw的平方根,那么dW就变成了更小的值,再用它对参数W进行更新,那么就可以减小在纵向的波动。对于较小的参数db也是如此,可以增大在横向上的优化(如上图中的绿线所示)。此时可以使用一个较大的学习率,而无需在纵轴垂直方向上偏离。
Adam优化算法
Adam (Adaptive Moment Estimation)优化算法是Momentum下降算法和 RMSprop 的结合,它几乎适应于各种深度模型,在任何结构中都能起到很好的优化效果。算法实现如下:

在Adam的超参数中,学习率是非常重要的超参数,需要尝试多次进行调试;
一般使用0.9,
一般使用0.999,
一般使用
。
学习率衰减
在利用 mini-batch 梯度下降法来寻找Cost function的最小值的时候,如果我们设置一个固定的学习速率,在最小值附近的波动幅度和刚开始的幅度是一样的,波动范围会比较大,不会精确收敛,而是一直在一个最小值点较大的范围内波动,如下图中蓝色曲线所示。而如果使用学习率衰减策略,随着迭代次数的增加,慢慢减小学习率,在算法开始的时候,学习速率还是相对较快,能够更地向最小值点的方向下降,而随着学习率的减小,下降的步伐也会逐渐变小,最终会在最小值附近的一块更小的区域里波动而更容易收敛到最小值,如下图中绿色线所示。

学习率衰减方法:
- 最常用:

- 指数衰减:

- 其它:

- 离散下降:不同阶段使用不同的学习速率
局部最优问题
在低维度的情形下,我们可能会想象到一个Cost function存在一些极小值点,在初始化参数的时候,如果初始值选取的不得当,会存在陷入局部最优点的可能性。但是,如果我们建立一个高维度的神经网络(如下图所示),通常梯度为零的点,出现局部最优点的概率极低,它更容易出现鞍点(有的参数方向上是凸函数,有的是凹函数)。所以说局部最优并不是问题,而真正的问题在于平稳段。平稳段是一个梯度长期接近于0的区域,参数更新会非常慢,需要花费很长时间才能走出平稳段,通过使用momentum、RMSprop或Adam优化方法可以可以调整平稳段的梯度,使其从一个很小的接近于0的值,变成一个较大的数,加快学习速度,尽快走出平稳段。
