1.mini-batch梯度下降
在前面学习向量化时,知道了可以将训练样本横向堆叠,形成一个输入矩阵和对应的输出矩阵:
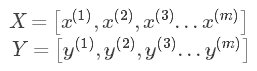
当数据量不是太大时,这样做当然会充分利用向量化的优点,一次训练中就可以将所有训练样本涵盖,速度也会较快。但当数据量急剧增大,达到百万甚至更大的数量级时,组成的矩阵将极其庞大,直接对这么大的的数据作梯度下降,可想而知速度是快不起来的。故这里将训练样本分割成较小的训练子集,子集就叫mini-batch。例如:训练样本数量m=500万,设置mini-batch=1000,则可以将训练样本划分为5000个mini-batch,每个mini-batch中含有1000个样本数据,当然,输出矩阵也要做同样的划分。这张图可以直观的理解:


在实际的训练中,会通过循环来遍历所有的mini-batch,对每一个mini-batch都会做和原来一样的步骤,即:前向传播、计算损失函数、反向传播、更新参数。



这张图可以大致反应两种梯度下降方法其损失函数的变化过程:在batch梯度下降中,由于每次训练迭代都是遍历的整个训练集,故损失函数的曲线应是一个较为平滑的下降过程,如出现明显的抖动,很大程度可能是学习率α过大。
但在mini-batch梯度下降中可以看到,并不是每次迭代其损失函数都是下降的,这是因为训练集不完整的原因。但总体趋势还是下降的,抖动程度取决于设置的mini-batch的大小。
综合来说,如果训练集较小,那么直接使用batch梯度下降法,可以快速的处理整个数据集,一般来说是少于2000个样本。
如果训练集再大一点,就可以考虑使用mini-batch梯度下降法,一般mini-batch的大小为64 - 512(考虑到电脑内存,设置为2的n次方,运算速度会快些)。
另外,当mini-batch设置为1时,又叫做随机梯度下降法
2.、指数加权平均
举个例子:下图是一年内某地气温的变化情况:
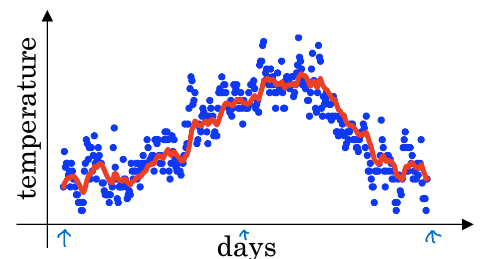
可以看到数据点比较的杂乱,但是大体趋势还是存在的。为了更好的表现气温变化情况,这里做一下这样的处理:



我们看到这个高值的β=0.98得到的曲线要平坦一些,是因为你多平均了几天的温度.所以波动更小,更加平坦.缺点是曲线向右移动,这时因为现在平均的温度值更多,
所以会出现一定的延迟.对于β=0.98这个值的理解在于有0.98的权重给了原先的值,只有0.02的权重给了当日的值.
我们现在将β=0.5作图运行后得到黄线,由于仅平均了两天的温度,平均的数据太少,所以得到的曲线有更多的噪声,更有可能出现异常值,但是这个曲线能更快的适应温度变化,
所以指数加权平均数经常被使用. 在统计学中,它常被称为指数加权移动平均值
3.动量梯度下降
4.RMSprop
5.Adam优化
6.学习率衰减
参考文献
[1]https://www.cnblogs.com/cloud-ken/p/7723755.html
[2]https://blog.csdn.net/yxnull/article/details/80832604