目录
Feature Evolution during Training
论文名称:Visualizing and Understanding Convolutional Networks
论文作者:Matthew D. Zeiler,Rob Fergus
论文链接:https://arxiv.org/pdf/1311.2901.pdf
时间:2013 年
写在前面
看了几篇基础网络框架的论文,到现在基本上是一种查漏补缺的状态吧:不会太过于关注网络的结构,相反会去关注一些之前自己没有关注到的点。所以这个 blog 对网络结构不会讲得太细,因为这篇论文的网络结构是在 AlexNet 的基础上做了一些改变,可参考 AlexNet 的那篇 blog:https://blog.csdn.net/qq_36627158/article/details/109714655。所以这里只会简单讲讲这篇论文的网络结构与 AlenNet 的区别,重点会放在我之前没有接触过的 Deconvolution。
摘要(主要贡献)
- 可视化了网络的各个层
- 做了大量消融实验(ablation study)来验证网络中每一层对网络模型性能的贡献大小
- 最后做实验证明了一下他们提出的 ZFNet(pretrained on the ImageNet)泛化性能很好
简介
先讲了 LeNet、AlexNet 的 good performance,再提到了 dramatic improvement in performance 的几大因素:1、标注数据多了 2、GPU 更牛了 3、有了更好的正则化策略(Dropout 等)。
然后指出这些 dramatic improvement 都是人们对网络结构一个个试出来,并不知道网络内部发生了什么,为什么这样设计会更好,这是非常不科学的。于是,作者引入了 visualization technique,用来可视化每一层的 feature map。
这里的 visualization technique 用的是 Zeiler et al. [29] 的 multi-layered Deconvolutional Network (deconvnet),将激活的图片特征从 feature map 空间转化到 pixel 空间,以发现是哪些 pixel 激活了特定的 feature map(这里是第一次接触,后面可以再多了解一些 CAM、【29】等文章)
同时,作者通过遮挡输入图像的不同部分,分析其分类结果,来探究“场景中哪一个部分对网络的分类结果而言是重要的”
通过这个 visualization technique,研究了 AlexNet 模型的各个层,最终提出了一个性能更好的网络结构:ZFNet,最后做实验验证泛化性能不错。
反卷积(又叫转置卷积,重点!!!)
参考链接:
答应我,先阅读第一个链接里的反卷积操作好吗?
通常,正向的卷积操作包括以下几个步骤:(1)filter (2)relu (3)max pooling (4)【optionally】local contrast operation
所以反卷积就是步骤反过来:(1)unpool (2)relu (4)filter
论文中提到的反卷积过程:
To examine a convnet, a deconvnet is attached to each of its layers, as illustrated in Fig. 1(top), providing a continuous path back to image pixels.
To start, an input image is presented to the convnet and features computed throughout the layers.
To examine a given convnet activation, we set all other activations in the layer to zero and pass the feature maps as input to the attached deconvnet layer.
Then we successively (i) unpool, (ii) rectify and (iii) filter to reconstruct the activity in the layer beneath that gave rise to the chosen activation. This is then repeated until input pixel space is reached.
意思是:先给定一张输入图像,得到它在各卷积层的特征。当要得到某一层的某个 activation map(feature map)对应的反卷积图是,将该层的其他 activation map 置 0,然后将这些 activation maps 送入对应的 deconvnet 层里进行:1、unpool 2、relu 3、转置卷积 三个操作。(下图中,右边是卷积,左边是对应的反卷积)

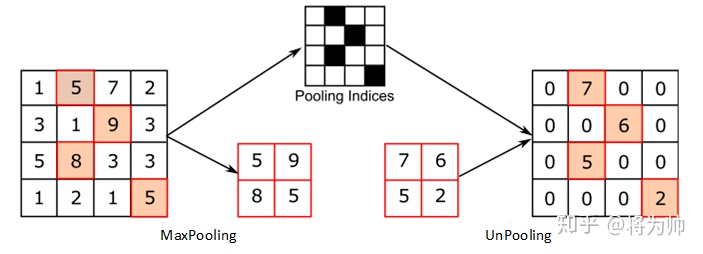
1、unpool
在正向卷积的池化过程中,会记录下每个 kernel 最大值的 index,形成一张 indices map(论文中又叫 Switch)。unpool 时,把前一层 reconstruct 好的值填入 index map 中对应的位置。
下图是论文里 unpooling 的图

可以参考这张图辅助理解(图自:https://zhuanlan.zhihu.com/p/140896660)
2、relu
To obtain valid feature reconstructions at each layer (which also should be positive), we pass the reconstructed signal through a relu non-linearity
就是将 unpool 好的结果进行和正向卷积里一样的 relu 操作。
注意,unpool 操作里只负责将前一层 reconstruct 好的值填入 index map 中对应的位置(也就是原来最大值对应的位置),并不执行其他操作。而前一层 reconstruct 好的值是有负值存在的,所以 unpooled map 也是有负值存在的。因此,是需要这一步的 relu 操作的
3、filtering
对正向卷积在该层的 filter 进行转置,得到 ,在 rectified(经过 relu) 好的 map 上使用
进行卷积
相关阅读参考文献:
【2】 Berkes, P., Wiskott, L.: On the analysis and interpretation of inhomogeneous quadratic forms as receptive fields. Neural Computation (2006)
【8】 Erhan, D., Bengio, Y., Courville, A., Vincent, P.: Visualizing higher-layer features of a deep network. Technical report, University of Montreal (2009)
【19】 Le, Q.V., Ngiam, J., Chen, Z., Chia, D., Koh, P., Ng, A.Y.: Tiled convolutional neural networks. In: NIPS (2010)
【23】 Simonyan, K., Vedaldi, A., Zisserman, A.: Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 1312.6034v1 (2013)
【29】 Zeiler, M., Taylor, G., Fergus, R.: Adaptive deconvolutional networks for mid and high level feature learning. In: ICCV (2011)
卷积网络的可视化
下图中,Layer 2 ~ 5:作者将验证数据分成一个个 random subsets,挑出了 subsets 里每一层所有 feature maps 中 top 9 的 activations,并使用前面提到的反卷积技术,把它映射回 pixel space。注意图中每一层左边的图都是验证集中给定一张 feature map,能导致 high activation 的 reconstructed patterns,右边是对应的原图 image patches。


从图中看出,神经网络学习到的特征存在层级结构:
- 第二层是学习到边缘和角点检测器
- 第三层学习到了一些纹理特征
- 第四层学习到了一些特定于类别的信息,例如狗脸、鸟腿
- 第五层学习到了整个物体,即使有很大的 pose variation
Feature Evolution during Training
下图中每一个 Layer 的图都从左往右展示了第 1、2、5、10、20、30、40、64 个 epoch 时学习到的特征。越低层的特征越容易在前面几个 epoch 就 converge 了,越高层的特征只有在训练了一定数量的 epoch 后才渐渐形成。如 Layer 5 的图片中,左边几个 epoch(1、2、5、10)都看不太出来特征,等到多训几个 epoch 后(30、40、64)后,才慢慢有了一些特征。

Architecture Selection
下图中(a)、(c)是 AlexNet 的第 1、2 层的可视化结果:
- AlexNet 第 1 层的 filter 只包含了非常高频和非常低频的信息,几乎没有中间频率的信息。
- 此外,AlexNet 第 2 层的可视化结果显示了由于大滑动步长引起的许多混叠效果
所以,作者根据这两个缺点,提出将 AlexNet 的第 1 层 filter 的大小由 11*11 缩小到 7*7,将第 2 层的滑动步长从 4 减小到 2,形成了 ZFNet。
下图中(b)、(d)是 ZFNet 的第 1、2 层的可视化结果。可以看出,ZFNet 的第 1、2 层包含了更多的信息。

Occlusion Sensitivity
作者在这里提出了疑问:网络模型是真的确认图片中物体所在的位置来对图片进行分类,还是只使用周围的背景来进行判断?
于是作者对图片做了遮挡处理(如下图第 1 列),再去对图片进行分类。结果如下(第 4、5 列),可以看出,当遮住图片的背景时,图片被分类器正确分类的概率还是很高的;当图片中的前景物体被遮住时,图片被分类器正确分类的概率大大降低。由此可以说明,网络模型确实是找到了物体所在的位置,并对其进行分类。
第 2 列、第 3 列。。。原谅我没看懂作者的英文表达。。。【写得如此晦涩难懂,为难我这个小白。。。】

实验
在 ImageNet 上 train 的结果

网络的结构对性能的影响
接着作者研究了不同的网络结构在 ImageNet 上 train 的结果:在 AlexNet 上调整某一层的神经元个数或者直接移除某一层。
实验结论:
- 网络模型的深度(网络的层数)对模型的性能影响很大。
- 增加全连接层的神经元个数会导致过拟合

特征泛化性研究
作者研究了模型在 ImageNet 上 pretrained 好后,分别在 Caltech-101,Caltech-256 和 PASCAL VOC 2012 上 fine-tune 的结果,看看在 ImageNet 上预训练好的模型提取特征的泛化能力:


在 Caltech-256 上 fine-tune 的实验里,作者除了做了一个准确率的对比,还做了如下图的实验。
结果:ZFNet 在 ImageNet 上 pretrained 好后,在 Caltech-256 上每个类只使用 6 张图进行 fine-tune,其效果就可以和 Bo 等人每个类使用 60 张图进行训练的效果媲美。再一次证明了在 ImageNet 上 pretrained 好后模型优秀的特征提取能力。

下表是在 PASCAL 2012 某些类别上的分类准确率。作者有指出在某些类别上准确率不如别人的原因:PASCAL 和 ImageNet 图片的本质不太一样,前者更倾向于全景图。

特征分析
作者分析 ImageNet pretrained model 每一层的特征有多 discriminative?通过改变 ImageNet pretrained model 保留的层数,并在最后接一个线性 SVM 或者 softmax 层来探究模型的性能。
实验结论:随着模型层数的增加,性能稳定提升。

总结
-
作者引入了一种新的可视化卷积结果的方法
-
通过可视化卷积结果的手段来帮助确定现有模型(AlexNet)的问题,并改进得到新的模型(ZFNet)
-
通过遮挡实验证实了:模型在进行分类任务时,是对图片局部结构高度敏感的,而不是使用广泛的场景上下文信息。
-
展示了 ImageNet trained model 的泛化能力有多强
Things To Learn
- CAM
-
【2】 Berkes, P., Wiskott, L.: On the analysis and interpretation of inhomogeneous quadratic forms as receptive fields. Neural Computation (2006)
【8】 Erhan, D., Bengio, Y., Courville, A., Vincent, P.: Visualizing higher-layer features of a deep network. Technical report, University of Montreal (2009)
【19】 Le, Q.V., Ngiam, J., Chen, Z., Chia, D., Koh, P., Ng, A.Y.: Tiled convolutional neural networks. In: NIPS (2010)
【23】 Simonyan, K., Vedaldi, A., Zisserman, A.: Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 1312.6034v1 (2013)
【29】 Zeiler, M., Taylor, G., Fergus, R.: Adaptive deconvolutional networks for mid and high level feature learning. In: ICCV (2011)