转:https://blog.csdn.net/u010579901/article/details/79184464
论文下载地址:Very Deep Convolutional Networks for Large-Scale Image Recognition
本文主要包含如下内容:
论文来源于牛津大学 visual geometry group(VGG),撰写于2014年,主要探讨了深度对网络的重要性,并且构造了一个19层的深度神经网络,在ILSVRC 2014中定位获得了第一名,分类获得了第二名。
主要思想
这篇论文的工作在ILSVRC 2014中的classification项目的比赛中取得了第2名的成绩,证明网络越深,网络学习能力越好,分类能力越强。
相对于 Alex-net,论文主要使用了较小尺寸的滤波器,并且使用 1*1 卷积核进行降为操作,在减少计算量的同时引入了非线性,增强了网络的表达能力。
网络结构
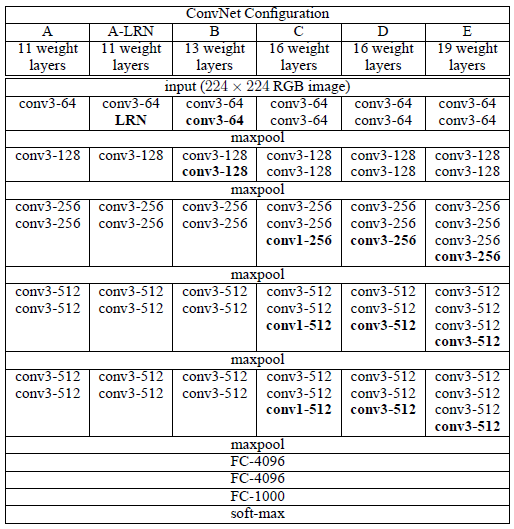
VGGNet 网络结构通过反复堆叠3´3的小型卷积核和2´2的最大池化层, 成功地构筑了16~19层深的卷积神经网络。
其中,网络中使用了3*3卷积核:未使用较大的感受野,如11*11和7*7的卷积核,因为两个连续的3*3大小的卷积核与一个5*5大小的卷积核具有相同的局部空间(感受野),而连续的3*3大小的卷积核则和一个7*7大小的卷积核具有相同的局部空间。但相比使用一个7*7大小的卷积核,3个连续的3*3的卷积核进行了3次非线性处理,提高了网络的学习能力。另外,3*3的卷积核也降低了参数的数目,假设3x3的卷积核处理C通道的feature maps时,一共有3(3x3xCxC)=27CxC个参数,而7x7的卷积核则有7x7xCxC共49CxC个参数;
同时,网络中使用1*1卷积核:用以降维和升维:维度指的是通道数(厚度),而不改变图片的宽和高。
网络中还加入非线性:卷积层之后经过激励层,1*1的卷积在前一层的学习表示上添加了非线性激励,提升网络的表达能力。

可以应用Netscope查看网络具体参数。
训练时,输入是大小为224*224的RGB图像,预处理只在训练集中的每个像素上减去RGB的均值。
图像经过一系列卷积层处理,在卷积层中使用了非常小的感受野(receptive field):3*3,甚至有的地方使用1*1的卷积,这种1*1的卷积可以被看做是对输入通道(input channel)的线性变换。
卷积步长(stride)设置为1个像素,3*3卷积层的填充(padding)设置为1个像素。池化层采用max-pooling,共有5层,在一部分卷积层后,max-pooling的窗口是2*2,步长是2。
一系列卷积层之后跟着全连接层(fully-connected layers)。前两个全连接层均有4096个通道。第三个全连接层有1000个通道,用来分类。所有网络的全连接层配置相同。
所有隐藏层都使用ReLu。VGGNet不使用局部响应标准化(LRN),这种标准化并不能在ILSVRC数据集上提升性能,却导致更多的内存消耗和计算时间。
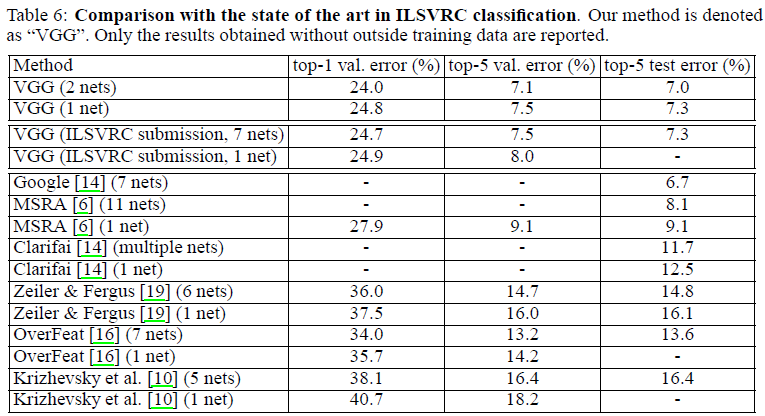
实验结果
论文中比较了 VGG 网络和其他网络在ILSVRC 2014中的classification挑战赛的测试结果。