论文地址:Numerical Coordinate Regression with Convolutional Neural Networks
代码地址:https://github.com/anibali/dsntnn
论文总结
本文提供了一种从图像中直接学习到坐标的一种思路。现在主流的方法都是基于高斯核处理的heatmap作为监督,但这种方法学习到的heatmap,在后处理得到坐标的过程中,存在量化误差(比如4倍下采样的heatmap,量化误差的期望是2)。
本文提出一种新的处理方法,称为DSNT,通过DSNT处理(没添加额外参数),直接对坐标进行监督。DSNT是对heatmap进行处理的,思路如下图所示。最后的处理过程,就是将heatmap通过softmax,得到一个基于heatmap的概率分布,再通过这个概率分布,与预设好的X,Y(坐标轴)进行点乘,得到坐标的期望值。监督损失也是建立在这个期望值上的。

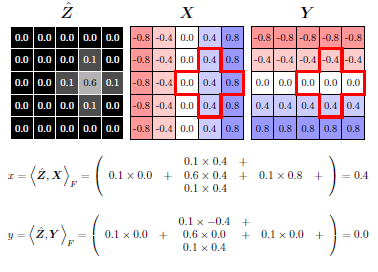
虽然文中的思想,主要说的是直接对坐标进行的回归,但实际上应用时,还是对heatmap做了约束的,而且权重还不算小。换个角度想,其实本文的实际操作,也可以认为,是对heatmap做了监督,然后添加了一个坐标的正则化因子。该正则化项的监督,可以有效减少heatmap转化成坐标的量化损失,与一些直接对heatmap做回归造成的损失误差与预期不符的问题。但是,这个heatmap项的损失也是精心挑选的,甚至不添加heatmap损失项,比不少heatmap损失计算方法的结果更好一些。
但是,对于那些在图像中不存在的关键点(比如半身),以及多人之类的问题,DSNT都不能直接进行解决。对于某些场景的应用,这是不可避免的问题。
论文介绍
在这之前,有两种方法通过图片得到坐标:(1)基于heatmap产生坐标;(2)基于全连接层得到坐标(Yolov1之类的);第一种方法,在heatmap产生坐标的过程中,处理有两处不是很完美:(1)使用的argmax之类的处理过程,是不可微分的,不能进行直接学习;(2)heatmap到坐标的过程中,存在着量化误差。heatmap与输入分辨率的下采样倍数越大,量化误差越大。更值得注意的是,监督是建立于heatmap 上的,这将导致损失函数与我们的度量(坐标上)之间相隔开来了。在推理时,我们只使用其中的某个(某几个)像素进行数值坐标计算,但在训练时,对所有像素都会造成损失。
第二种方法,无法解决空间泛化问题。空间泛化,指的是图像位置与类别识别的无关性。一般来说,卷积操作具有空间不变性,是因为他是权重共享的操作。而添加了全连接层,就意味着有部分区域是没有参与权重共享的。这就意味着使用全连接层的模型,对数据集的分布有更为严格的要求。
下表展示了heatmap,fully connection,DSNT三种得到坐标方法的优劣势。可以从表中看出,heatmap不是全微分,在低分辨率表现不好;fully connection,不具有空间泛化能力,而且容易过拟合;而DSNT具有所有优点。

个人见解:之所以DSNT能直接得到坐标,又能同时具有空间泛化能力,是在于两点:(1)其对heatmap进行了监督,监督对象为高斯分布,具有对称性;(2)其对坐标轴对象X,Y进行了精心设计,分别是 1 ∗ n 1*n 1∗n和 n ∗ 1 n*1 n∗1的单方向性,使其在两个坐标轴具有对称性。
下图是使用heatmap监督,和使用DSNT对坐标进行监督所学习的heatmap的区别(说是对heatmap没有监督,但实际上不是的,加了正则化项),DSNT的结果更集中一些。

heatmap在输入到DSNT之前,要经过归一化处理,变成概率分布图。normalized的意思就是非负的,加起来和为1。归一化的尝试有下表中的四种,最后选择softmax作为整流归一化的函数。

下图展示了,如果只对heatmap进行监督,不一定能得到想要的那个点位。MSE 损失较小的,不一定就是更准确的。所以,只对heatmap做损失监督,是不准确的。

文中的监督损失,直接对坐标进行,如下面的公式所表示的。

对于DSNT层,如同上面的Z和X,Y的点乘得到最后的坐标,可以知道有许多不同的heatmap会导致DSNT产生一样的坐标(比如heatmap因为卷积核大小导致的heatmap的扩散和收缩对坐标不产生任何影响)。虽然这种自由被认为是有益的,但潜在的缺点是,该模型在训练期间通过heatmap没有收到严格监督的像素梯度。实验中,发现通过正则化提供这样的监督可以比普通DSNT产生显著的性能改进。对损失函数加上了heatmap的正则化项,损失函数变成以下公式:

方差正则化如下面公式表示,控制的是目标的方差。
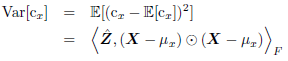

分布正则化如下面公式所示,其对heatmap的形状添加严格的正则化,以直接鼓励某种形状。其中 D ( ⋅ ∣ ∣ ⋅ ) D(\cdot | | \cdot) D(⋅∣∣⋅)是离散度量。
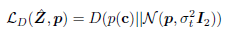
在ResNet-34模型,28像素上应用,在MPII数据集下,各种正则项的表现如下表所示:

可以看出,JS分布正则化的准确度最高。下图样本heatmap图像在不同正则化选项下如何剧烈地改变heatmap外观。KL散度和JS散度表示的分布正则化非常有效地促进了高斯形状的斑点的产生。

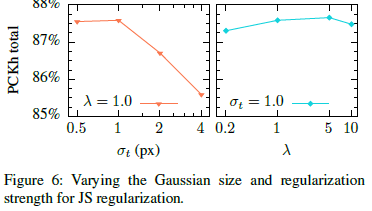
选定了正则化项为JS分布正则化后,通过实验得到其他超参数因子的值:最后选择 σ = 1 , λ = 1 \sigma=1,\lambda=1 σ=1,λ=1。
实验结果
不同分辨率的heatmap和不同策略产生坐标的pckh值如下表所示:可以看出,DSNT的表现都良好。
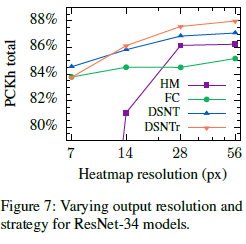
不同heatmap分辨率下,通过带正则化项的DSNT的实验结果如下:可以看出,16倍的下采样损失有点大。更高的heatmap分辨率在任何深度都是有益的,但代价是增加分辨率对内存消耗和计算成本都产生很大的影响。

不同输出策略在不同堆叠hourglass上的实验结果如下:

hourglass + heatmap 与 ResNet + DSNTr 进行对比。ResNet+28像素(8倍下采样)是trade-off的选择。
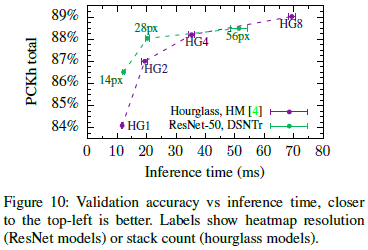
不同方法的精度、推理时间和内存占用对比:
