Searching for MobileNet V3


琦玉老师 和 龙卷(阿姨)小姐姐 告诉我一个道理——画风越简单,实力越强悍;
这篇论文只有四个词,我只能说:不!简!单!
(一)论文地址:
(二)核心思想:
- 使用了两个黑科技:NAS 和 NetAdapt 互补搜索技术,其中 NAS 负责搜索网络的模块化结构,NetAdapt 负责微调每一层的 channel 数,从而在延迟和准确性中达到一个平衡;
- 提出了一个对于移动设备更适用的非线性函数 ;
- 提出了 和 两个新的高效率网络;
- 提出了一个新的高效分割(指像素级操作,如语义分割)的解码器( );
(三)Platform-Aware NAS for Block-wise Search:
3.1 MobileNetV3-Large:
对于有较大计算能力的平台,作者提出了 MobileNetV3-Large,并使用了跟 MnanNet-A1 相似的基于 RNN 控制器和分解分层搜索空间的 NAS 搜索方法;
3.1 MobileNetV3-Small:
对于有计算能力受限制的平台,作者提出了 MobileNetV3-Small;
这里作者发现,原先的优化方法并不适用于小的网络,因此作者提出了改进方法;
用于近似帕累托最优解的多目标奖励函数定义如下:
其中 是第 个模型的索引, 是模型的准确率, 是模型的延迟, 是目标延迟;
作者在这里将权重因数 改成了 ,最后得到了一个期望的种子模型(initial seed model);
(四)NetAdapt for Layer-wise Search:
第二个黑科技就是 NetAdapt 搜索方法,用于微调上一步生成的种子模型;
NetAdapt 的基本方法是循环迭代以下步骤:
- 生成一系列建议模型(proposals),每个建议模型代表了一种结构改进,满足延迟至少比上一步的模型减小了 ,其中 , 是种子模型的延迟;
- 对于每一个建议模型,使用上一步的预训练模型,删除并随机初始化改进后丢失的权重,继续训练 步来粗略估计建议模型的准确率,其中 ;
- 根据某种度量,选取最合适的建议模型,直到达到了目标延迟 ;
作者将度量方法改进为最小化(原文是最大化,感觉是笔误):
其中建议模型的提取方法为:
- 减小 Expansion Layer 的大小;
- 同时减小 BottleNeck 模块中的前后残差项的 channel 数;
(五)Efficient Mobile Building Blocks:
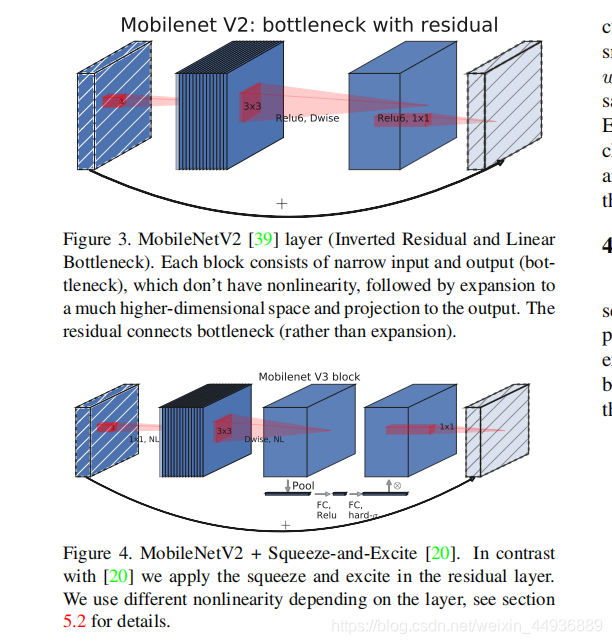
作者在 BottleNet 的结构中加入了SE结构,并且放在了depthwise filter之后;
由于SE结构会消耗一定的计算时间,所以作者在含有SE的结构中,将 Expansion Layer 的 channel 数变为原来的1/4;
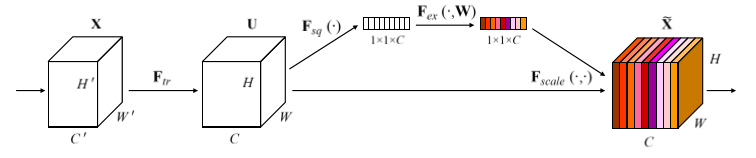
其中 SE 模块首先对卷积得到的特征图进行 Squeeze 操作,得到特征图每个 channel 上的全局特征,然后对全局特征进行 Excitation 操作,学习各个 channel 间的关系,从而得到不同channel的权重,最后乘以原来的特征图得到最终的带有权重的特征;
(六)Redesigning Expensive Layers:
作者在研究时发现,网络开头和结尾处的模块比较耗费计算能力,因此作者提出了改进这些模块的优化方法,从而在保证准确度不变的情况下减小延迟;
6.1 Last Stage:
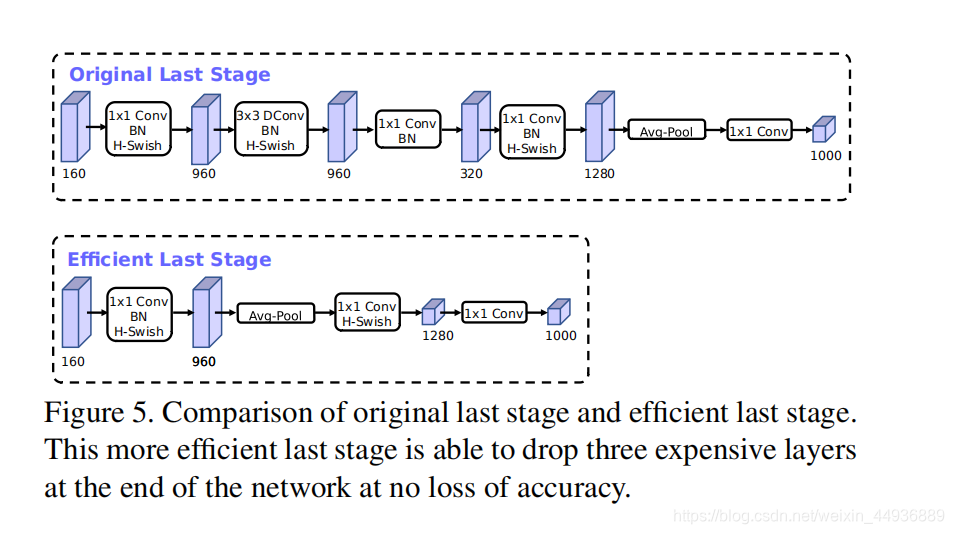
在这里作者删掉了 Average pooling 前的一个逆瓶颈模块(包含三个层,用于提取高维特征),并在 Average pooling 之后加上了一个 1×1 卷积提取高维特征;
这样使用 Average pooling 将大小为 7×7 的特征图降维到 1×1 大小,再用 1×1 卷积提取特征,就减小了 7×7=49 倍的计算量,并且整体上减小了 11% 的运算时间;
6.2 Initial Set of Filters:
之前的 MobileNet 模型开头使用的都是 32 组 3×3 大小的卷积核并使用 ReLU 或者 swish 函数作为激活函数;
作者在这里提出,可以使用 h-switch 函数作为激励函数,从而删掉多余的卷积核,使得初始的卷积核组数从 32 下降到了 16;
(7)hard switch 函数:
之前有论文提出,可以使用 函数替代 ReLU 函数,并且能够提升准确率;
其中 switch 函数定义为:
,其中 ;
由于 sigmaoid 函数比较复杂,在嵌入式设备和移动设备计算消耗较大,作者提出了两个解决办法:
7.1 h-swish 函数:
将 swish 中的 sigmoid 函数替换为一个线性函数,将其称为 h-swish:
-
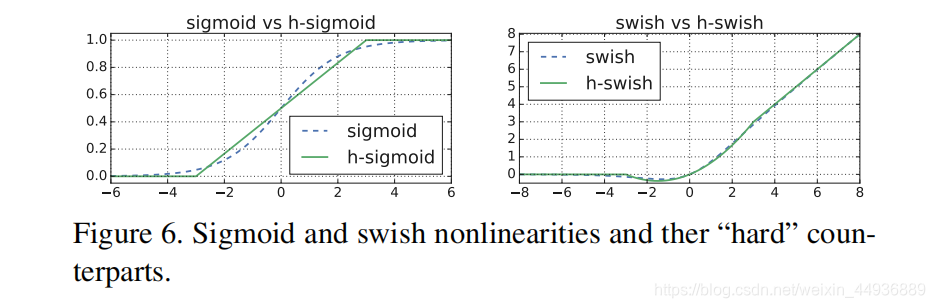
7.2 going deeper:
作者发现 swish 函数的作用主要是在网络的较深层实现的,因此只需要在网络的第一层和后半段使用 h-swish 函数;
(八)网络结构:
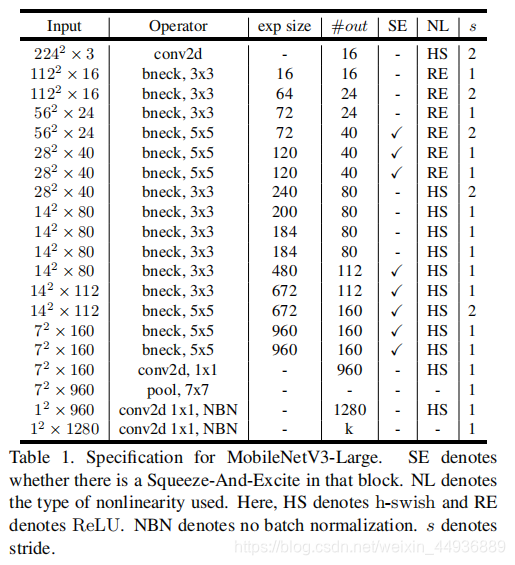
8.1 MobileNetV3-Large:
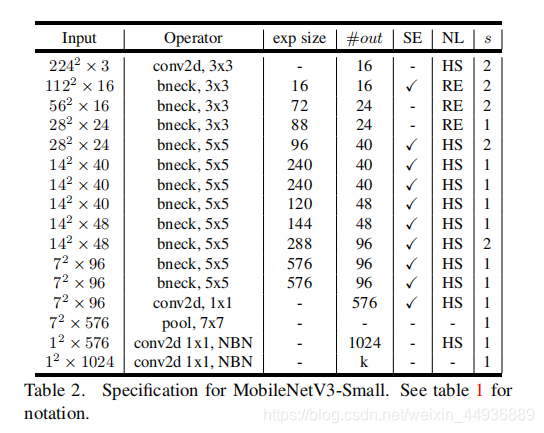
8.2 MobileNetV3-Small:
(九)训练细节:
使用了 Tensorflow 的 RMSPropOptimizer 优化器,并附加 0.9 的动量项;
初始化学习率为 0.1,batch 大小为 4096(每个 GPU 128);
每 3 个 epoch 学习率衰减 0.01;
使用了 0.8 的 dropout 和 1e-5 的 weight decay;
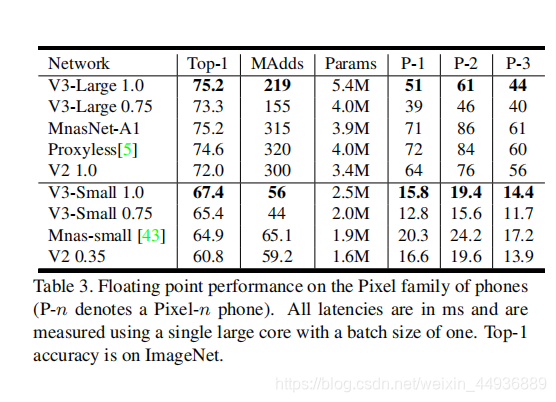
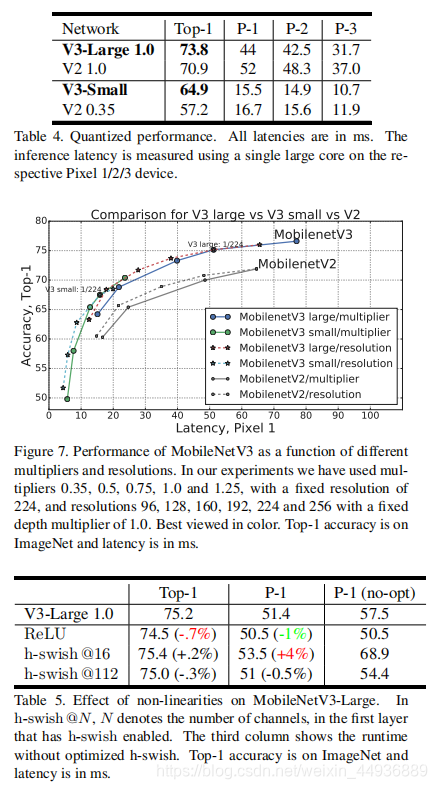
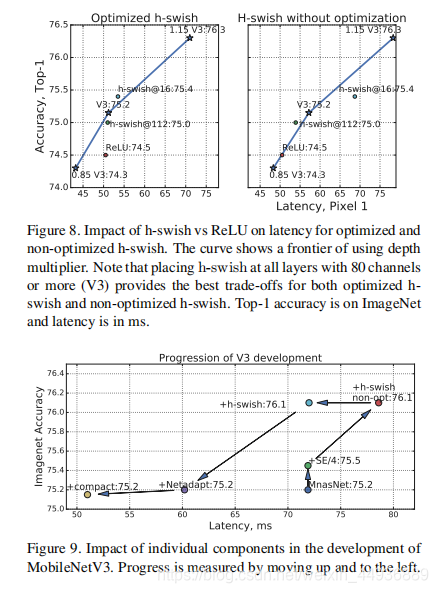
(十)实验结果:
(十一)语义分割——Lite R-ASSP:

