【轻量型卷积网络】MobileNet系列:MobileNet V3网络解析
文章目录
1. 介绍
论文地址:论文链接
1.1 关于v1和v2
- MobileNet-v1的主要思想就是深度可分离卷积,大大减少了参数量和计算量。可以参考 MobileNet V1网络解析。
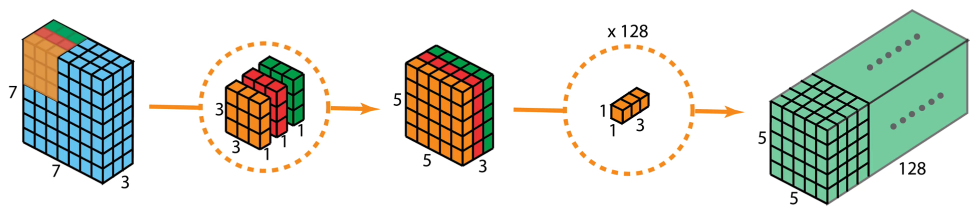
深度可分离卷积 可理解为 深度卷积 + 逐点卷积。- 深度卷积:深度卷积只处理长宽方向的空间信息;逐点卷积只处理跨通道方向的信息。能大大减少参数量,提高计算效率。 一个卷积核只处理一个通道,即每个卷积核只处理自己对应的通道。输入特征图有多少个通道就有多少个卷积核。将每个卷积核处理后的特征图堆叠在一起。输入和输出特征图的通道数相同。
- 逐点卷积: 是使用1x1卷积对跨通道维度处理,有多少个1x1卷积核就会生成多少个特征图。用于跨通道扩充维度。
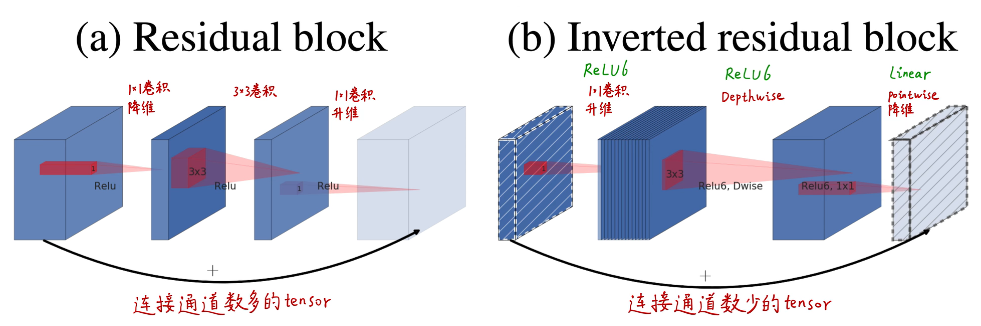
- MobileNet-v2 使用了逆转残差模块和最后一层采用线性层(而不是relu)。可以参考 MobileNet V2网络解析。
- 输入图像,先使用1x1卷积提升通道数;然后在高维空间下使用深度卷积;再使用1x1卷积下降通道数,降维时采用线性激活函数(y=x)。当步长等于1且输入和输出特征图的shape相同时,使用残差连接输入和输出;当步长=2(下采样阶段)直接输出降维后的特征图。
- 对比 ResNet 的残差结构。输入图像,先使用1x1卷积下降通道数;然后在低维空间下使用标准卷积,再使用1x1卷积上升通道数,激活函数都是ReLU函数。当步长等于1且输入和输出特征图的shape相同时,使用残差连接输入和输出;当步长=2(下采样阶段)直接输出降维后的特征图。
1.2 v3の介绍
相对于v2,主要有3个变化:
- block结构发生改变,在v2的bottleneck block里加入了Squeeze-and-Excitation block。
- 算法内部微结构变化,把部分relu6使用hard-swish替换,把全部sigmoid使用hard-sigmoid替换。
- 使用Platform-Aware Neural Architecture Search(NAS)来形成网络结构,并利用NetAdapt技术进一步筛选网络层结构。
2. 模型
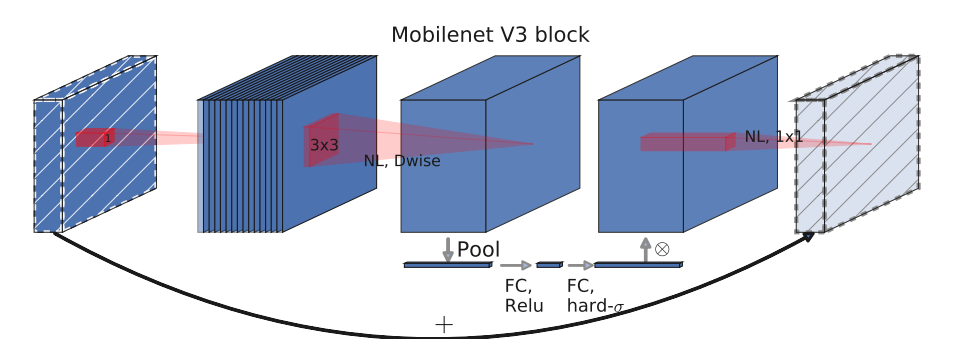
- 主要有以下改进:(1)添加SE注意力机制;(2)使用新的激活函数;(3)重新设计耗时层结构
2.1 添加SE注意力机制
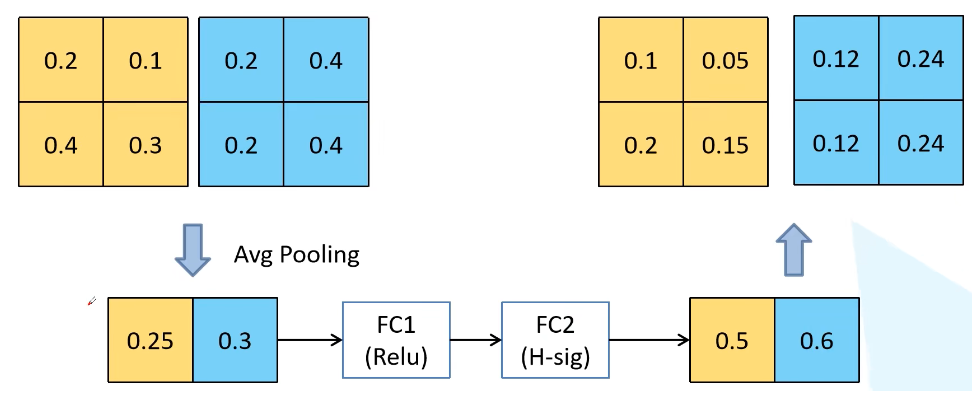
- 先将特征图进行全局平均池化,特征图有多少个通道,那么池化结果(一维向量)就有多少个元素,[h, w, c]==>[None, c]。
- 然后经过两个全连接层得到输出向量。第一个全连接层的输出通道数等于原输入特征图的通道数的1/4;第二个全连接层的输出通道数等于原输入特征图的通道数。即先降维后升维。
- 全连接层的输出向量可理解为,向量的每个元素是对每张特征图进行分析得出的权重关系。比较重要的特征图就会赋予更大的权重,即该特征图对应的向量元素的值较大。反之,不太重要的特征图对应的权重值较小。
- 第一个全连接层使用ReLU激活函数,第二个全连接层使用 hard_sigmoid 激活函数。
- 经过两个全连接层得到一个由channel个元素组成的向量,每个元素是针对每个通道的权重,将权重和原特征图的对应相乘,得到新的特征图数据。
以下图为例,特征图经过两个全连接层之后,比较重要的特征图对应的向量元素的值就较大。将得到的权重和对应特征图中的所有元素相乘,得到新的输出特征图。
2.2 使用不同的激活函数
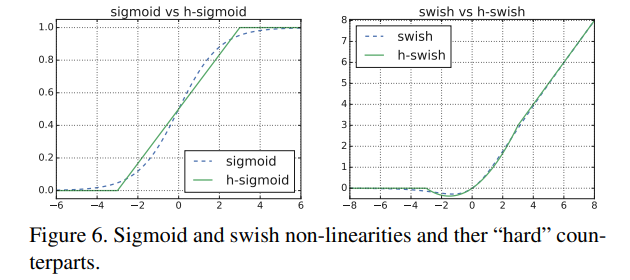
- swish激活函数公式为: x e − x \frac{x}{e^{-x}} e−xx,尽管提高了网络精度,但是它的计算、求导复杂,对量化过程不友好,尤其对移动端设备的计算。
- h_sigmoid激活函数公式为: R e L U 6 ( x + 3 ) 6 \frac{ReLU6(x+3)}{6} 6ReLU6(x+3),ReLU6激活函数公式为: m i n ( m a x ( x , 0 ) , 6 ) min(max(x,0),6) min(max(x,0),6)
- h_swish激活函数公式为: x ∗ R e L U 6 ( x + 3 ) 6 x*\frac{ReLU6(x+3)}{6} x∗6ReLU6(x+3),替换之后网络的推理速度加快,对量化过程比较友好。
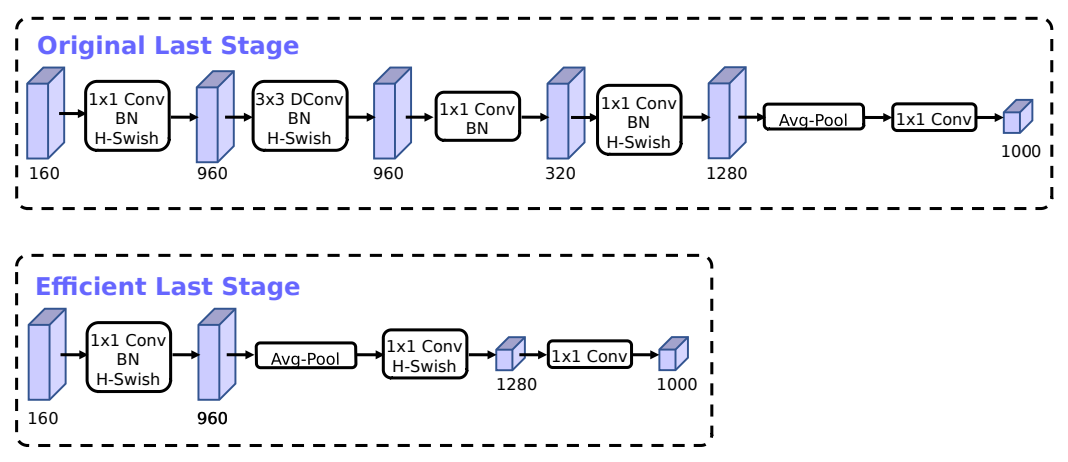
2.3 重新设计耗时层结构
- 减少第一个卷积层的卷积核个数。将卷积核个数从32个降低到16个之后,准确率和降低之前是一样的。减少卷积核个数可以减少计算量,节省2ms时间。
- 简化最后的输出层。删除多余的卷积层,在准确率上没有变化,节省了7ms执行时间,这7ms占据了整个推理过程的11%的执行时间。明显提升计算速度。
2.4 总体流程
图像输入,先通过1x1卷积上升通道数;然后在高维空间下使用深度卷积;再经过SE注意力机制优化特征图数据;最后经过1x1卷积下降通道数(使用线性激活函数)。当步长等于1且输入和输出特征图的shape相同时,使用残差连接输入和输出;当步长=2(下采样阶段)直接输出降维后的特征图。
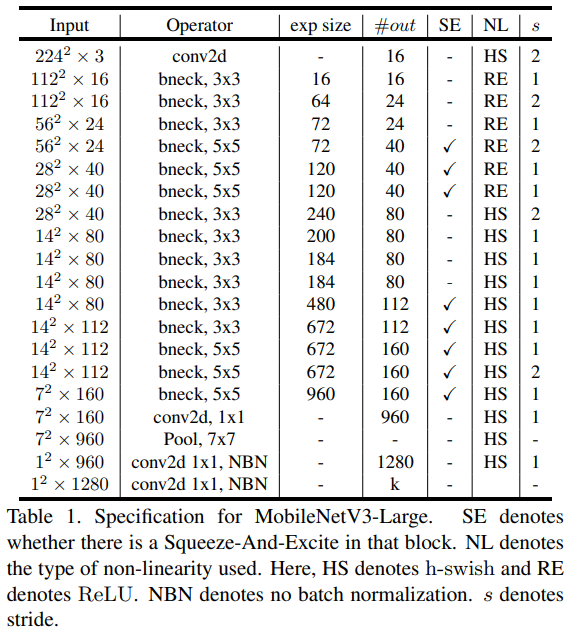
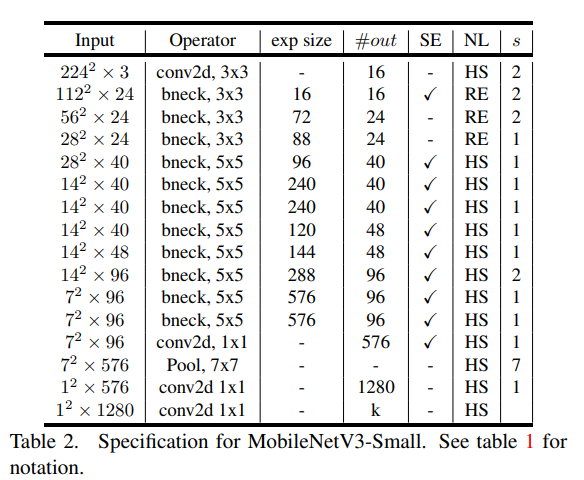
2.5 网络结构图
网络模型结构如图所示。exp size 代表11卷积上升的通道数;#out 代表11卷积下降的通道数,即输出特征图数量;SE 代表是否使用注意力机制;NL 代表使用哪种激活函数;s 代表步长;bneck 代表逆残差结构;NBN 代表不使用批标准化。
3. 参考
【1】https://blog.csdn.net/dgvv4/article/details/123476899