论文传送门:https://arxiv.org/pdf/1905.02244.pdf
MobileNet V3的目的:对图片进行特征提取,依据特征进行分类。(也可以作为backbone完成检测和分割任务)
MobileNet V3的优点:相较于V2,模型更小(small),精度更高。
MobileNet V3的方法:
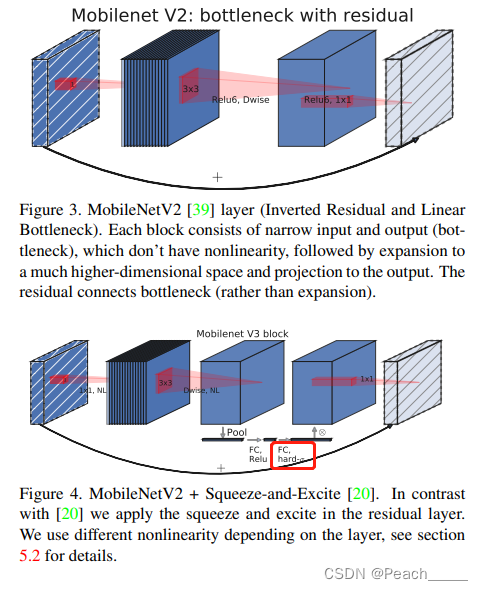
①引入SE(Squeeze-and-Excitation)注意力机制模块,改进倒置残差结构;(红框部分激活函数未注明,SENet中使用Sigmoid,这里使用HardSwish);
②使用h-swish(HardSwish)激活函数和relu激活函数;
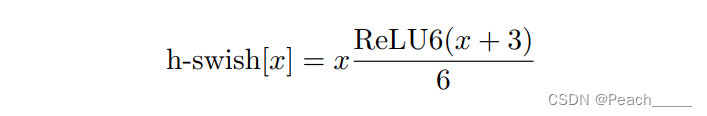
③使用NAS(Neural Architecture Search)技术搜索网络结构;
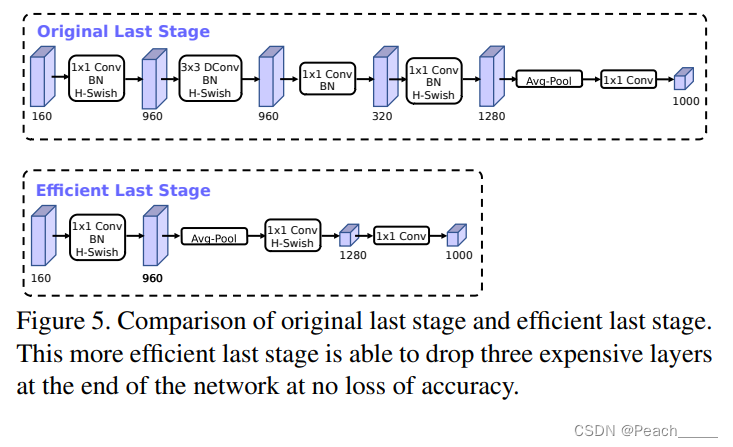
④改进了分类部分的网络结构。
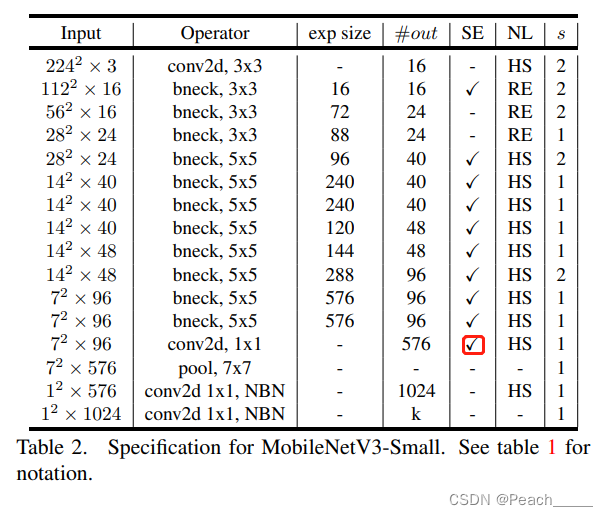
MobileNet V3的结构:
①Small:(红框部分表示使用SE结构,但在实现过程中并未使用)
②Large:
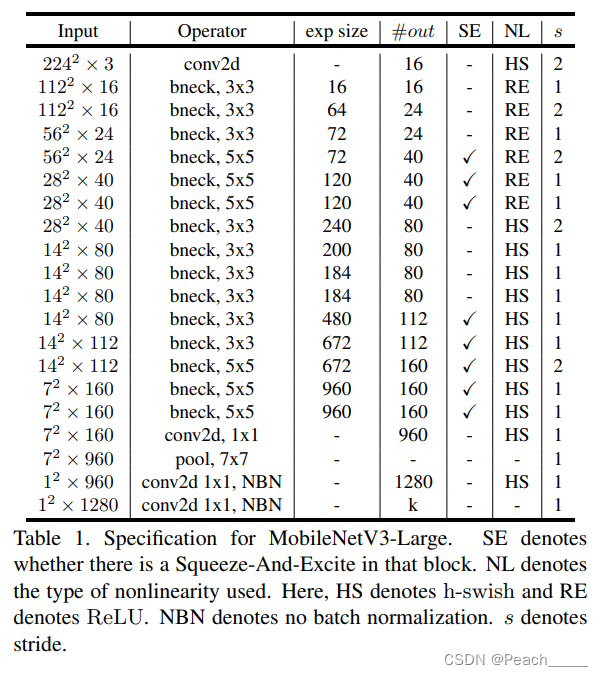
注:如想使用预训练权值,请参考pytorch官方实现代码。
import torch
import torch.nn as nn
def conv_block(in_channel, out_channel, kernel_size=3, strid=1, groups=1,
activation="h-swish"): # 定义卷积块,conv+bn+h-swish/relu
padding = (kernel_size - 1) // 2 # 计算padding
assert activation in ["h-swish", "relu"] # 激活函数在h-swish和relu中选择
return nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size, strid, padding=padding, groups=groups, bias=False), # conv
nn.BatchNorm2d(out_channel), # bn
nn.Hardswish(inplace=True) if activation == "h-swish" else nn.ReLU(inplace=True) # h-swish/relu
)
class SEblock(nn.Module): # 定义Squeeze and Excite注意力机制模块
def __init__(self, channel): # 初始化方法
super(SEblock, self).__init__() # 继承初始化方法
self.channel = channel # 通道数
self.attention = nn.Sequential( # 定义注意力模块
nn.AdaptiveAvgPool2d(1), # avgpool
nn.Conv2d(self.channel, self.channel // 4, 1, 1, 0), # 1x1conv,代替全连接
nn.ReLU(inplace=True), # relu
nn.Conv2d(self.channel // 4, self.channel, 1, 1, 0), # 1x1conv,代替全连接
nn.Hardswish(inplace=True) # h-swish,此处原文图中为hard-alpha,未注明具体激活函数,这里使用h-swish
)
def forward(self, x): # 前传函数
a = self.attention(x) # 通道注意力权重
return a * x # 返回乘积
class bneck(nn.Module): # 定义改进的倒置残差结构,对应原文中的bneck
def __init__(self, in_channel, out_channel, kernel_size=3, strid=1, t=6., se=True, activation="h-swish"): # 初始化方法
super(bneck, self).__init__() # 继承初始化方法
self.in_channel = in_channel # 输入通道数
self.out_channel = out_channel # 输出通道数
self.kernel_size = kernel_size # 卷积核尺寸
self.strid = strid # 步长
self.t = t # 中间层通道扩大倍数,对应原文expansion ratio
self.hidden_channel = int(in_channel * t) # 计算中间层通道数
self.se = se # 是否使用SE注意力机制模块
self.activation = activation # 激活函数形式
layers = [] # 存放模型结构
if self.t != 1: # 如果expansion ratio不为1
layers += [conv_block(self.in_channel, self.hidden_channel, kernel_size=1,
activation=self.activation)] # 添加conv+bn+h-swish/relu
layers += [conv_block(self.hidden_channel, self.hidden_channel, kernel_size=self.kernel_size, strid=self.strid,
groups=self.hidden_channel,
activation=self.activation)] # 添加conv+bn+h-swish/relu,此处使用组数等于输入通道数的分组卷积实现depthwise conv
if self.se: # 如果使用SE注意力机制模块
layers += [SEblock(self.hidden_channel)] # 添加SEblock
layers += [conv_block(self.hidden_channel, self.out_channel, kernel_size=1)[:-1]] # 添加1x1conv+bn,此处不再进行激活函数
self.residul_block = nn.Sequential(*layers) # 倒置残差结构块
def forward(self, x): # 前传函数
if self.strid == 1 and self.in_channel == self.out_channel: # 如果卷积步长为1且前后通道数一致,则连接残差边
return x + self.residul_block(x) # x+F(x)
else: # 否则不进行残差连接
return self.residul_block(x) # F(x)
class MobileNetV3(nn.Module): # 定义MobileNet v3网络
def __init__(self, num_classes, model_size="small"): # 初始化方法
super(MobileNetV3, self).__init__() # 继承初始化方法
self.num_classes = num_classes # 类别数量
assert model_size in ["small", "large"] # 模型尺寸,仅支持small和large两种
self.model_size = model_size # 模型尺寸选择
if self.model_size == "small": # 如果是small模型
self.feature = nn.Sequential( # 特征提取部分
conv_block(3, 16, strid=2, activation="h-swish"), # conv+bn+h-swish,(n,3,224,224)-->(n,16,112,112)
bneck(16, 16, kernel_size=3, strid=2, t=1, se=True, activation="relu"), # bneck,(n,16,112,112)-->(n,16,56,56)
bneck(16, 24, kernel_size=3, strid=2, t=4.5, se=False, activation="relu"), # bneck,(n,16,56,56)-->(n,24,28,28)
bneck(24, 24, kernel_size=3, strid=1, t=88 / 24, se=False, activation="relu"), # bneck,(n,24,28,28)-->(n,24,28,28)
bneck(24, 40, kernel_size=5, strid=2, t=4, se=True, activation="h-swish"), # bneck,(n,24,28,28)-->(n,40,14,14)
bneck(40, 40, kernel_size=5, strid=1, t=6, se=True, activation="h-swish"), # bneck,(n,40,14,14)-->(n,40,14,14)
bneck(40, 40, kernel_size=5, strid=1, t=6, se=True, activation="h-swish"), # bneck,(n,40,14,14)-->(n,40,14,14)
bneck(40, 48, kernel_size=5, strid=1, t=3, se=True, activation="h-swish"), # bneck,(n,40,14,14)-->(n,48,14,14)
bneck(48, 48, kernel_size=5, strid=1, t=3, se=True, activation="h-swish"), # bneck,(n,48,14,14)-->(n,48,14,14)
bneck(48, 96, kernel_size=5, strid=2, t=6, se=True, activation="h-swish"), # bneck,(n,48,14,14)-->(n,96,7,7)
bneck(96, 96, kernel_size=5, strid=1, t=6, se=True, activation="h-swish"), # bneck,(n,96,7,7)-->(n,96,7,7)
bneck(96, 96, kernel_size=5, strid=1, t=6, se=True, activation="h-swish"), # bneck,(n,96,7,7)-->(n,96,7,7)
conv_block(96, 576, kernel_size=1, activation="h-swish") # conv+bn+h-swish,(n,96,7,7)-->(n,576,7,7),此处没有使用SE注意力模块
)
self.classifier = nn.Sequential( # 分类部分
nn.AdaptiveAvgPool2d(1), # avgpool,(n,576,7,7)-->(n,576,1,1)
nn.Conv2d(576, 1024, 1, 1, 0), # 1x1conv,(n,576,1,1)-->(n,1024,1,1)
nn.Hardswish(inplace=True), # h-swish
nn.Conv2d(1024, self.num_classes, 1, 1, 0) # 1x1conv,(n,1024,1,1)-->(n,num_classes,1,1)
)
else:
self.feature = nn.Sequential( # 特征提取部分
conv_block(3, 16, strid=2, activation="h-swish"), # conv+bn+h-swish,(n,3,224,224)-->(n,16,112,112)
bneck(16, 16, kernel_size=3, strid=1, t=1, se=False, activation="relu"), # bneck,(n,16,112,112)-->(n,16,112,112)
bneck(16, 24, kernel_size=3, strid=2, t=4, se=False, activation="relu"), # bneck,(n,16,112,112)-->(n,24,56,56)
bneck(24, 24, kernel_size=3, strid=1, t=3, se=False, activation="relu"), # bneck,(n,24,56,56)-->(n,24,56,56)
bneck(24, 40, kernel_size=5, strid=2, t=3, se=True, activation="relu"), # bneck,(n,24,56,56)-->(n,40,28,28)
bneck(40, 40, kernel_size=5, strid=1, t=3, se=True, activation="relu"), # bneck,(n,40,28,28)-->(n,40,28,28)
bneck(40, 40, kernel_size=5, strid=1, t=3, se=True, activation="relu"), # bneck,(n,40,28,28)-->(n,40,28,28)
bneck(40, 80, kernel_size=3, strid=2, t=6, se=False, activation="h-swish"), # bneck,(n,40,28,28)-->(n,80,14,14)
bneck(80, 80, kernel_size=3, strid=1, t=2.5, se=False, activation="h-swish"), # bneck,(n,80,14,14)-->(n,80,14,14)
bneck(80, 80, kernel_size=3, strid=1, t=2.3, se=False, activation="h-swish"), # bneck,(n,80,14,14)-->(n,80,14,14)
bneck(80, 80, kernel_size=3, strid=1, t=2.3, se=False, activation="h-swish"), # bneck,(n,80,14,14)-->(n,80,14,14)
bneck(80, 112, kernel_size=3, strid=1, t=6, se=True, activation="h-swish"), # bneck,(n,80,14,14)-->(n,112,14,14)
bneck(112, 112, kernel_size=3, strid=1, t=6, se=True, activation="h-swish"), # bneck,(n,112,14,14)-->(n,112,14,14)
bneck(112, 160, kernel_size=5, strid=2, t=6, se=True, activation="h-swish"), # bneck,(n,112,14,14)-->(n,160,7,7)
bneck(160, 160, kernel_size=5, strid=1, t=6, se=True, activation="h-swish"), # bneck,(n,160,7,7)-->(n,160,7,7)
bneck(160, 160, kernel_size=5, strid=1, t=6, se=True, activation="h-swish"), # bneck,(n,160,7,7)-->(n,160,7,7)
conv_block(160, 960, kernel_size=1, activation="h-swish") # conv+bn+h-swish,(n,160,7,7)-->(n,960,7,7)
)
self.classifier = nn.Sequential( # 分类部分
nn.AdaptiveAvgPool2d(1), # avgpool,(n,960,7,7)-->(n,960,1,1)
nn.Conv2d(960, 1280, 1, 1, 0), # 1x1conv,(n,960,1,1)-->(n,1280,1,1)
nn.Hardswish(inplace=True), # h-swish
nn.Conv2d(1280, self.num_classes, 1, 1, 0) # 1x1conv,(n,1280,1,1)-->(n,num_classes,1,1)
)
def forward(self, x): # 前传函数
x = self.feature(x) # 提取特征
x = self.classifier(x) # 分类
return x.view(-1, self.num_classes) # 压缩不需要的维度,返回分类结果,(n,num_classes,1,1)-->(n,num_classes)