作者团队:谷歌
关注点:同时优化网络模型的速度与大小
related works
A1、网络受depth wise seperable convolution (在Inception、Xception中也有用到)的启发
A2、factorized network
A3、Squeezenet使用到了bottleneck的方法
B1、对预训练网络的shrinking、factorizing以及compressing(涉及乘积量化、哈希、减枝、向量量化、霍夫编码等)
B2、distillation,大型网络teach小网络
B3、low bit network
模型结构
1、depth wise seperable convolution
将标准卷积分解成为depthwise convolution和pointwise convolution。类似的分解卷积的方法之前也接触过,在学习数字图像处理时,将二维卷积核分解成两个一维卷积核能够减少计算量与参数量。

假设标准卷积的输入为
DF×DF×M,输出为
DF×DF×N,由上图,则标准卷积的参数量为
DK⋅DK⋅M⋅N,计算量为
DK⋅DK⋅M⋅N⋅DF⋅DF
depthwise seperable convolution 的参数量为
DK⋅DK⋅M+M⋅N,计算量为:
DK⋅DK⋅M⋅DF⋅DF+M⋅N⋅DF⋅DF
那么,depthwise separable 与标准卷积参数量之比为
ParamstaParamdws=DK⋅DK⋅M⋅NDK⋅DK⋅M+M⋅N=N1+DK21
depthwise separable 与标准卷积计算量之比为
ParamstaParamdws=DK⋅DK⋅M⋅N⋅DF⋅DFDK⋅DK⋅M⋅DF⋅DF+M⋅N⋅DF⋅DF=N1+DK21
标准卷积与depthwise seperable conv的结构:

2、shrinking hyperparameters:width multiplier、resolution multiplier
width multiplier:添加超参
α,改变通道数,原来的输入通道数
M变为
αM,输出通道数
N变为
αN。这样使得计算量之比变为
Nα+DK2α2,参数量约减少为原来的
α2
resolution multiplier:添加超参
ρ,改变图像大小,原本的边长
DF变为
ρDF,这样使得计算量之比变为
Nαρ2+DK2α2ρ2,参数量约减少为原来的
α2ρ2
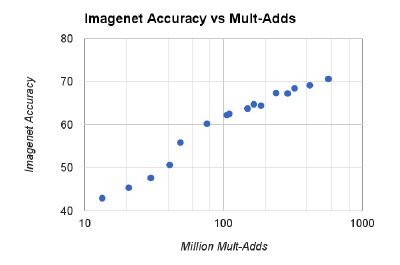
分类精度-计算量:对数线性关系
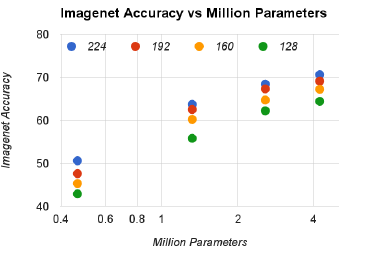
分类精度-参数量
3、具体网络结构
网络结构以及每层的卷积核设置
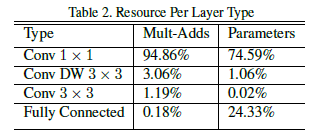
不同类型卷积层的计算量以及参数量如下:
这里发现的问题是
1×1卷积在整个网络中所占用的计算量以及参数量均为最大。这里的坑之后由ShuffleNet填上。