1. MobileNet V1
Howard, Andrew G., et al. “Mobilenets: Efficient convolutional neural networks for mobile vision applications.” arXiv preprint arXiv:1704.04861 (2017).
本文主要提出了一种深度可分离卷积(depthwise separable convolutions)用于替换传统卷积。将传统的卷积分解为了两步:用分组卷积来提取输入每个通道的特征图的特征,再用1x1卷积融合通道维的特征。我们将第一步称为Depthwise convolution,第二步称为Pointwise convolution。
在谷歌后面的Xception中也采用了深度可分离卷积,实验证明了这种分解传统卷积的有效性。
那么深度可分离卷积是如何减少参数量的呢,通过一个例子可以来说明:
假设输入一个正常卷积的特征图的形状是 M × H × W M \times H \times W M×H×W,输出的通道数为 N N N,采用 K × K K \times K K×K的卷积核需要的参数量为: M × K × K × N M \times K \times K \times N M×K×K×N。
如果采用深度可分离卷积,那么参数量为: M × K × K + M × 1 × 1 × N M \times K \times K + M \times 1 \times 1 \times N M×K×K+M×1×1×N
显然采用了深度可分离卷积的设计能够大大减少参数量。
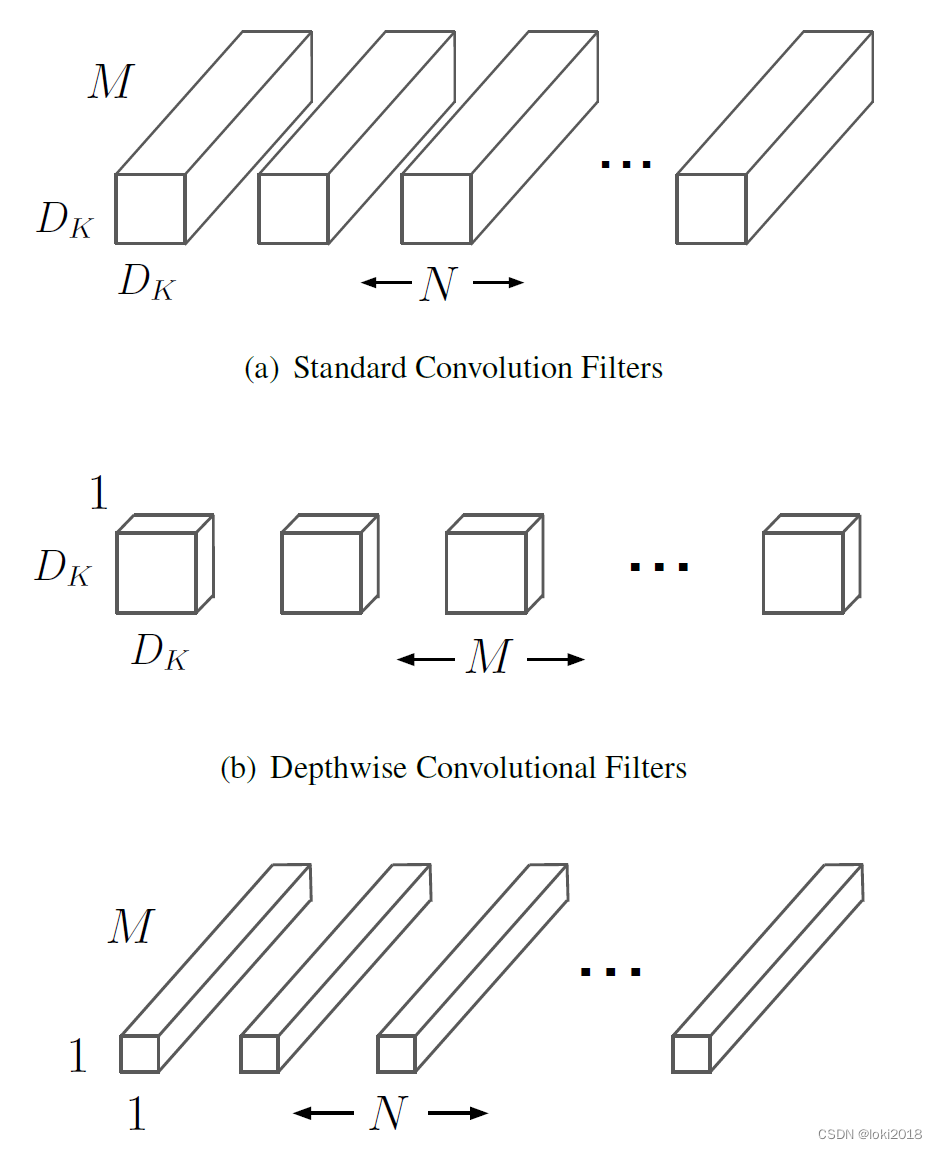

文章中也给出了每层参与计算的比例,可以看到1x1卷积参与了大部分的计算。
深度可分离卷积代码如下:
class DwsConvBlock(nn.Module):
"""
Depthwise separable convolution block with BatchNorms and activations at each convolution layers
"""
def __init__(self, in_channels, out_channels, stride=1):
super(DwsConvBlock, self).__init__()
self.conv3x3 = nn.Conv2d(
in_channels=in_channels,
out_channels=in_channels,
kernel_size=3,
stride=stride,
padding=1,
groups=in_channels
) # depthwise conv3x3, 改变形状不改变通道
# 每个卷积操作后紧跟bn和relu
self.bn1 = nn.BatchNorm2d(num_features=in_channels)
self.relu1 = nn.ReLU(inplace=True)
self.conv1x1 = nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=1
) # pointwise conv1x1,改变通道数
self.bn2 = nn.BatchNorm2d(num_features=out_channels)
self.relu2 = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv3x3(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.conv1x1(x)
x = self.bn2(x)
x = self.relu2(x)
return x
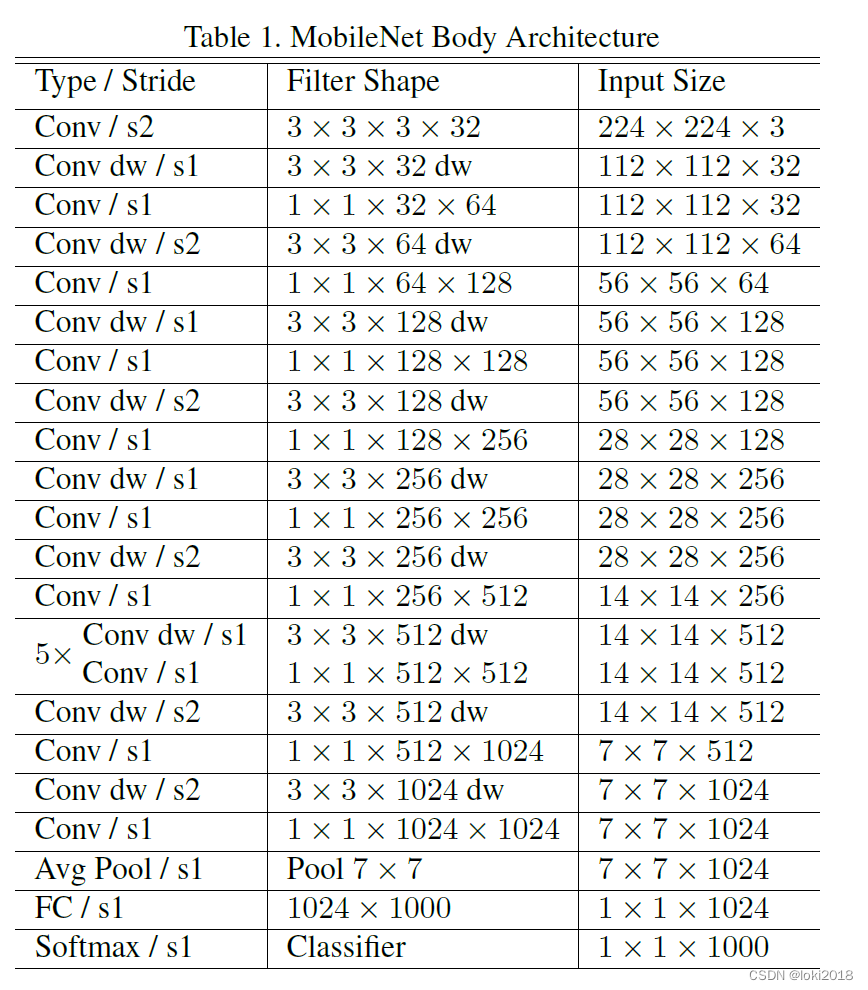
最后用深度可分离卷积构建MobileNet,文中的网络结构如图所示:
class MobileNet(nn.Module):
def __init__(self, in_channels=1, in_size=(224, 224), num_classes=10, version="orig"):
super(MobileNet, self).__init__()
if version == "orig":
channels = [[32], [64], [128, 128], [256, 256], [512, 512, 512, 512, 512, 512], [1024, 1024]]
first_stage_stride = False
elif version == "fd":
channels = [[32], [64], [128, 128], [256, 256], [512, 512, 512, 512, 512, 1024]]
first_stage_stride = True
self.in_size = in_size
self.num_classes = num_classes
self.features = nn.Sequential()
# 初始化层
self.features.add_module("init_block", nn.Conv2d(in_channels=in_channels,
out_channels=channels[0][0],
kernel_size=3,
stride=2))
in_channels = channels[0][0]
for i, channels_per_stage in enumerate(channels[1:]):
stage = nn.Sequential()
for j, out_channels in enumerate(channels_per_stage):
stride = 2 if (j == 0) and ((i != 0) or first_stage_stride) else 1 # 是否下采样。一般每个stage的第一个block都要做一次下采样
stage.add_module("Unit{}".format(j + 1), DwsConvBlock(in_channels=in_channels,
out_channels=out_channels,
stride=stride))
in_channels = out_channels
self.features.add_module("stage{}".format(i + 1), stage)
self.features.add_module("final_pool", nn.AvgPool2d(kernel_size=7, stride=1))
self.output = nn.Linear(in_features=in_channels,
out_features=num_classes)
def _init_params(self):
for name, module in self.named_modules():
if isinstance(module, nn.Conv2d):
nn.init.kaiming_normal_(module.weight)
if isinstance(module, nn.BatchNorm2d):
nn.init.constant_(module.weight, 1)
nn.init.constant_(module.bias, 0)
def forward(self, x):
x = self.features(x)
x = x.view(x.shape[0], -1)
x = self.output(x)
return x
2. MobileNet V2
Sandler, Mark, et al. “Mobilenetv2: Inverted residuals and linear bottlenecks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
这篇文章是MobileNet V1的延续,它提出了一种倒残差结构(inverted residual structure)以及揭示了非线性激活函数会导致低维信息的丢失,因此提出了一种采用线性激活函数的倒残差块。
当输入输入至一个卷积层之后会输出多通道的特征图,通常称多通道为manifolds of interest,然而并不是所有的通道都是重要的,起作用的往往只是那么几个,GhostNet也是基于这种想法设计的。因此,生成大量的通道看起来是非常冗余的,因此在设计卷积块时通常是先对输入降维再升维,中间再经过一个非线性的激活函数,例如Relu。

然而,低维的信息在经过非线性激活函数之后会有信息的丢失,如上图所示。
为了保证信息的完整,MobileNetV2在每个block后采用线性输出,并且设计了倒残差块,传统的残差块是两头大中间小,而为了能够捕捉更多的信息,倒残差块采用了两头小中间大的设计。
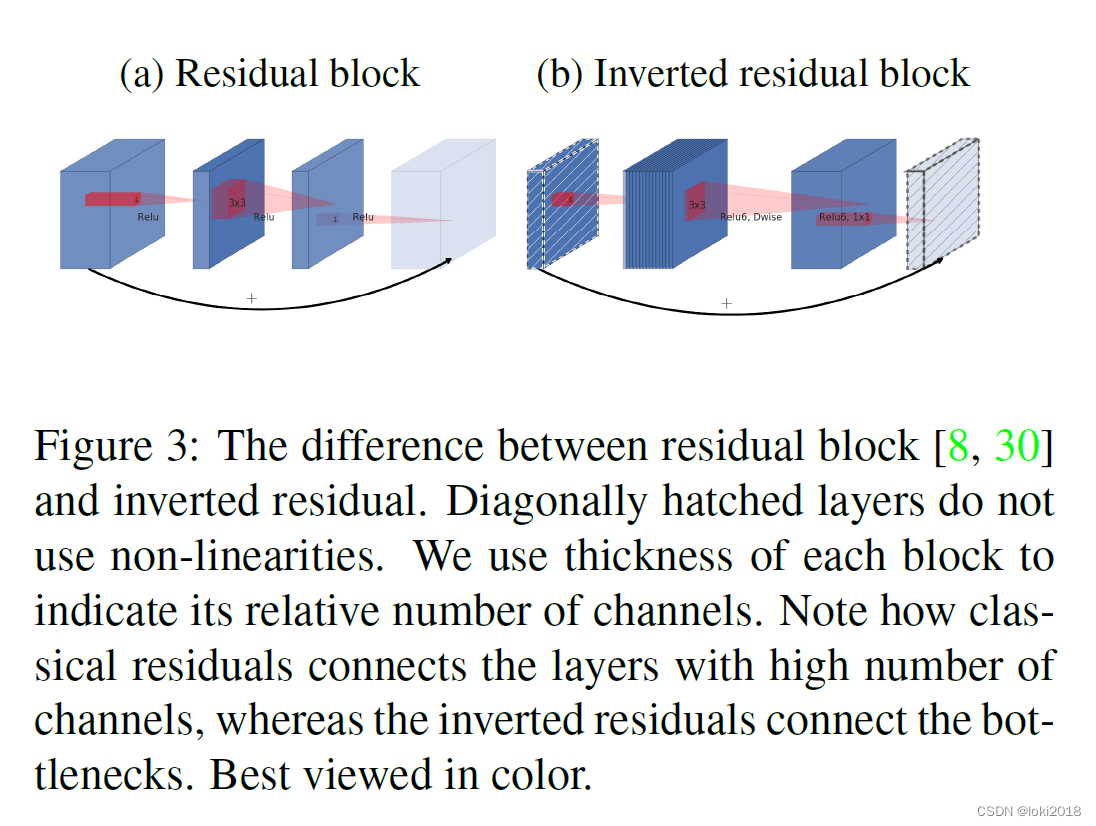
代码如下:
class InvertedLinearBlock(nn.Module):
def __init__(self, in_channels, out_channels, expansion=1, stride=1):
super(InvertedLinearBlock, self).__init__()
self.residual = (in_channels == out_channels) and (stride == 1) #输入和输出形状相等时做残差连接
mid_channels = in_channels * 6 if expansion else in_channels # 是否中间扩大通道数
self.conv1 = nn.Conv2d(in_channels=in_channels,
out_channels=mid_channels,
kernel_size=1)
self.bn1 = nn.BatchNorm2d(num_features=mid_channels)
self.activate1 = nn.ReLU6(inplace=True)
self.conv2 = nn.Conv2d(in_channels=mid_channels,
out_channels=mid_channels,
kernel_size=3,
stride=stride,
padding=1,
groups=mid_channels)
self.bn2 = nn.BatchNorm2d(num_features=mid_channels)
self.activate2 = nn.ReLU6(inplace=True)
self.conv3 = nn.Conv2d(in_channels=mid_channels,
out_channels=out_channels,
kernel_size=1)
# 最后一层没有激活函数
def forward(self, x):
if self.residual:
identity = x
x = self.conv1(x)
x = self.bn1(x)
x = self.activate1(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.activate2(x)
x = self.conv3(x)
if self.residual:
x = x + identity
return x

根据文章中的结构进行搭建MobileNetV2:
class MobileNetV2(nn.Module):
def __init__(self, in_channels=1, init_block_channels=32, final_block_channels=1280, num_classes=10, in_size=(224, 224)):
super(MobileNetV2, self).__init__()
self.in_size = in_size
self.num_classes = num_classes
self.features = nn.Sequential()
self.features.add_module("init_block", nn.Sequential(nn.Conv2d(in_channels=in_channels,
out_channels=init_block_channels,
stride=2,
kernel_size=3),
nn.ReLU6(inplace=True)))
in_channels = init_block_channels
channels_per_layers = [16, 24, 32, 64, 96, 160, 320]
layers = [1, 2, 3, 4, 3, 3, 1]
downsample = [0, 1, 1, 1, 0, 1, 0]
from functools import reduce
channels = reduce(
lambda x, y: x + [[y[0]] * y[1]] if y[2] != 0 else x[:-1] + [x[-1] + [y[0]] * y[1]],
zip(channels_per_layers, layers, downsample),
[[]])
for i, channels_per_stage in enumerate(channels):
stage = nn.Sequential()
for j, out_channels in enumerate(channels_per_stage):
stride = 2 if (j == 0) and (i != 0) else 1
expansion = (i != 0) or (j != 0)
stage.add_module("unit{}".format(j + 1), InvertedLinearBlock(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
expansion=expansion
))
in_channels = out_channels
self.features.add_module("stage{}".format(i + 1), stage)
self.features.add_module("final_block", nn.Sequential(
nn.Conv2d(in_channels=in_channels,
out_channels=final_block_channels,
kernel_size=1),
nn.ReLU6(inplace=True)
))
in_channels = final_block_channels
self.features.add_module("final_pool", nn.AvgPool2d(
kernel_size=7,
stride=1
))
self.output = nn.Conv2d(
in_channels=in_channels,
out_channels=num_classes,
kernel_size=1,
bias=False
)
self._init_params()
def _init_params(self):
for name, module in self.named_modules():
if isinstance(module, nn.Conv2d):
nn.init.kaiming_uniform_(module.weight)
if module.bias is not None:
nn.init.constant_(module.bias, 0)
def forward(self, x):
x = self.features(x)
x = self.output(x)
x = x.view(x.shape[0], -1)
return x
3. MobileNet V3
Howard, Andrew, et al. “Searching for mobilenetv3.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
本文主要采用了神经网络搜索的算法来优化超参数的设置,并且提出了一种新的非线性激活函数swish,表达式如下:
s w i s h ( x ) = x ⋅ σ ( x ) swish(x)=x \cdot \sigma(x) swish(x)=x⋅σ(x),为了进一步降低sigmoid函数的计算复杂度,作者提出了一种近似的函数来替代它:
h s w i s h ( x ) = x R e L U 6 ( x + 3 ) 6 hswish(x)=x \frac{ReLU6(x+3)}{6} hswish(x)=x6ReLU6(x+3)。
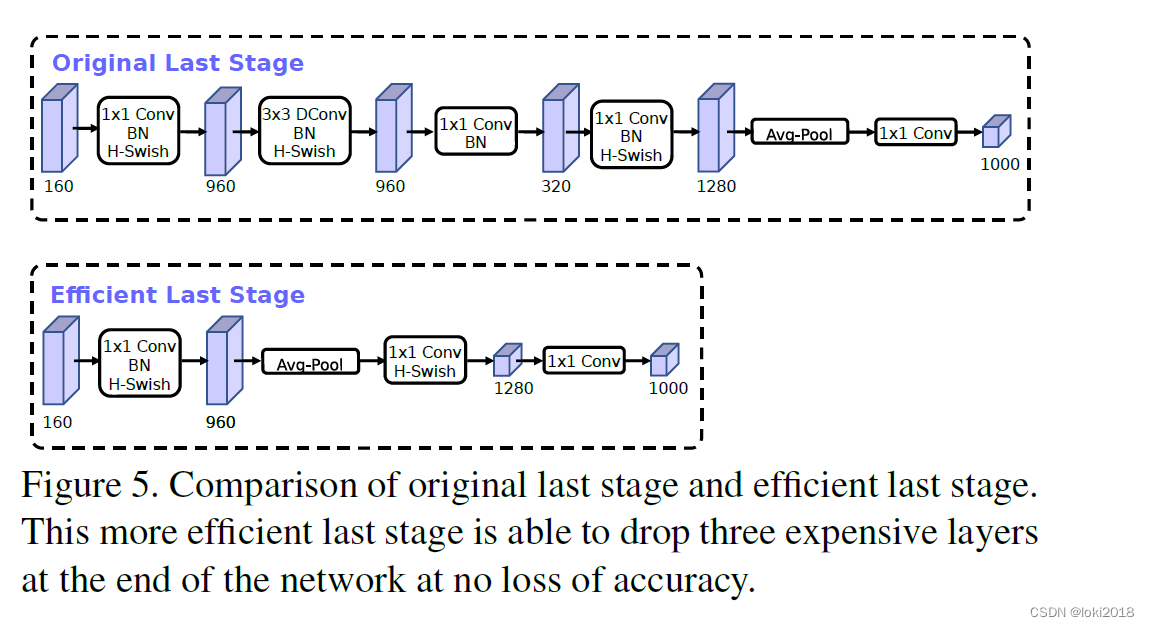
此外,作者对最后的stage进行了改进,在之前的MobileNet V2中,最后会采用一个1x1卷积对通道升维,但是这带来了巨大的开销,所以作者将平均池化放到了前面去做,这样减少了不少计算量。
对于倒残差模块,作者并没有做太多改进,只是加了一个SE块对通道做了一个注意力来提升预测的精度。
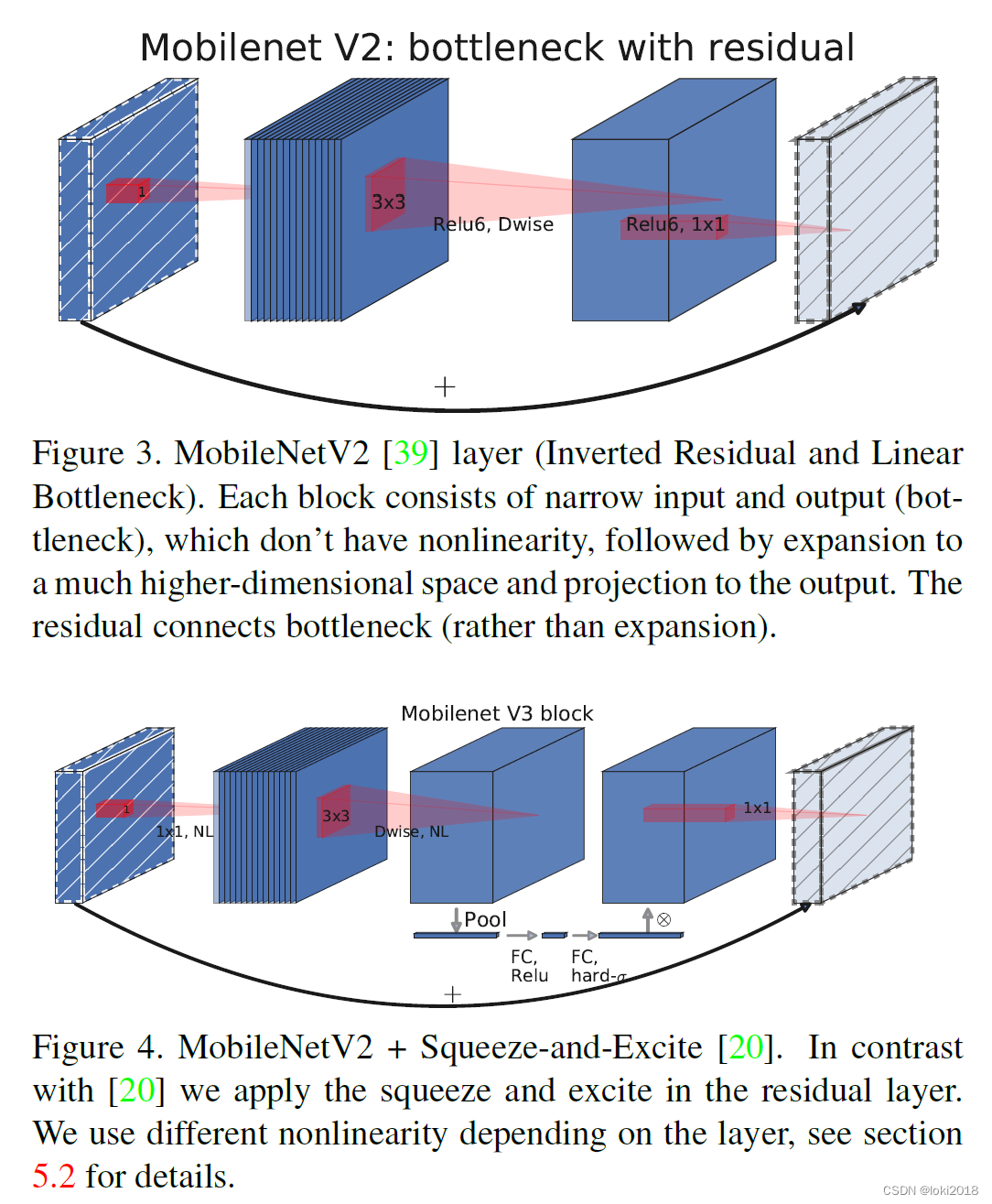
接下来我们把改进后的倒残差块代码给出:
class MobileNetV3Unit(nn.Module):
def __init__(self, in_channels, out_channels, exp_channels, stride,
use_kernel3, activation, use_se):
super(MobileNetV3Unit, self).__init__()
assert exp_channels >= out_channels
self.residual = (in_channels == out_channels) and (stride == 1)
self.use_se = use_se
self.use_exp_conv = exp_channels != out_channels
mid_channels = exp_channels
if self.use_exp_conv:
self.exp_conv = conv1x1_block(
in_channels=in_channels,
out_channels=exp_channels,
activation=activation
)
if use_kernel3:
self.conv1 = dwconv3x3_block(
in_channels=mid_channels,
out_channels=mid_channels,
stride=stride,
activation=activation
)
else:
self.conv1 = dwconv5x5_block(
in_channels=mid_channels,
out_channels=mid_channels,
stride=stride,
activation=activation
)
if use_se:
self.se = SEBlock(
channels=mid_channels,
reduction=4,
round_mid=True,
out_activation="hsigmoid"
)
self.conv2 = conv1x1_block(
in_channels=mid_channels,
out_channels=out_channels,
activation=None,
)
def forward(self, x):
if self.residual:
identity = x
if self.use_exp_conv:
x = self.exp_conv(x)
x = self.conv1(x)
if self.use_se:
x = self.se(x)
x = self.conv2(x)
if self.residual:
x = x + identity
return x
还有最后一部分的改进:
class MobileNetV3FinalBlock(nn.Module):
def __init__(self, in_channels, out_channels, use_se):
super(MobileNetV3FinalBlock, self).__init__()
self.use_se = use_se
self.conv = conv1x1_block(in_channels=in_channels,
out_channels=out_channels,
activation="hswish")
if self.use_se:
self.se = SEBlock(channels=out_channels,
reduction=4,
round_mid=True,
out_activation="hsigmoid")
def forward(self, x):
x = self.conv(x)
if self.use_se:
x = self.se(x)
return x
class MobileNetV3Classifier(nn.Module):
def __init__(self, in_channels, out_channels, mid_channels, dropout):
super(MobileNetV3Classifier, self).__init__()
self.use_dropout = (dropout != 0.0)
self.conv1 = conv1x1_block(in_channels=in_channels,
out_channels=mid_channels,
activation="hswish",
use_bn=False)
if self.use_dropout:
self.dropout = nn.Dropout(p=dropout)
self.conv2 = conv1x1_block(in_channels=mid_channels,
out_channels=out_channels,
activation=None,
bias=True,
use_bn=False)
def forward(self, x):
x = self.conv1(x)
if self.use_dropout:
x = self.dropout(x)
x = self.conv2(x)
return x