文章目录
课堂问答
- Q1: 什么时候造成 ReLU神经元失活?(Dead ReLU)
- A1: 当我们输入的有些输入使得ReLU的输入为负数的时候i,其反向传播梯度为0,即梯度在这里就断掉了。
- Q2: 在训练阶段预处理后在测试阶段也需要做吗?
- A2: 需要使用同一经验值来进行预处理,例如都减去训练集的均值
而且整个经验值,需要在分批之前在整个训练集合=上得到。 - Q3: 为什么批量归一化后需要新学两个缩放参数?
- A3: 可学习的参数使得我们的输入不总是单位高斯分布的,导致有时候激活函数可能会部分出现饱和,增加了神经元的丰富性。
- Q4: 类似于像强化学习这样的小批量输入,BN操作是否还有效?
- A4: 实践证明,BN在深度CNN中有效,或许小的批量会影响均值和方差的计算,减少准确率,但是总的来说依然有一定效果。
- Q5: 在BN操作的时,如果强制将输入变成单位高斯分布,会损失数据结构吗?
- A5: 假设我们的输入特征有高斯分布的结构,则即便使用预处理,也不会改变高斯分布结构,可能造成高斯分布的平移。而在卷积操作中,我们可能像保留一个卷积区域内空间的部分结构,所以我们会在该区域内进行BN(而不仅在每个特征维度上进行BN)。更多的,我们还可以学习两个缩放参数保留部分数据结构。
- Q6: 训练的时候,BN是使用的一个批次训练数据的均值和方差,那么在测试单个样本的时候,这个值该怎么得到?
- A6: 如我们在模型训练时我们就记录下每个batch下的均值和方差,待训练完毕后,我们求整个训练样本的均值和方差期望值,作为我们进行预测时进行BN的的均值和方差:
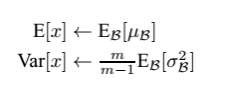
最后测试阶段使用的BN:
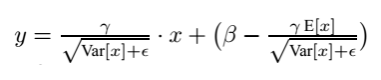
1. 激活函数(Activation Function)
1.1 Sigmoid激活函数
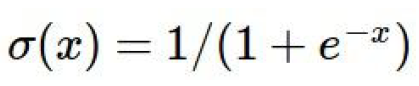
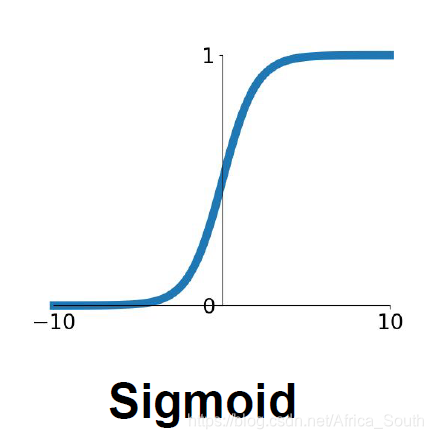
作用:将输入压缩在一个0~1的区间内
缺点:
- (正/负)饱和神经元使得反传梯度消失
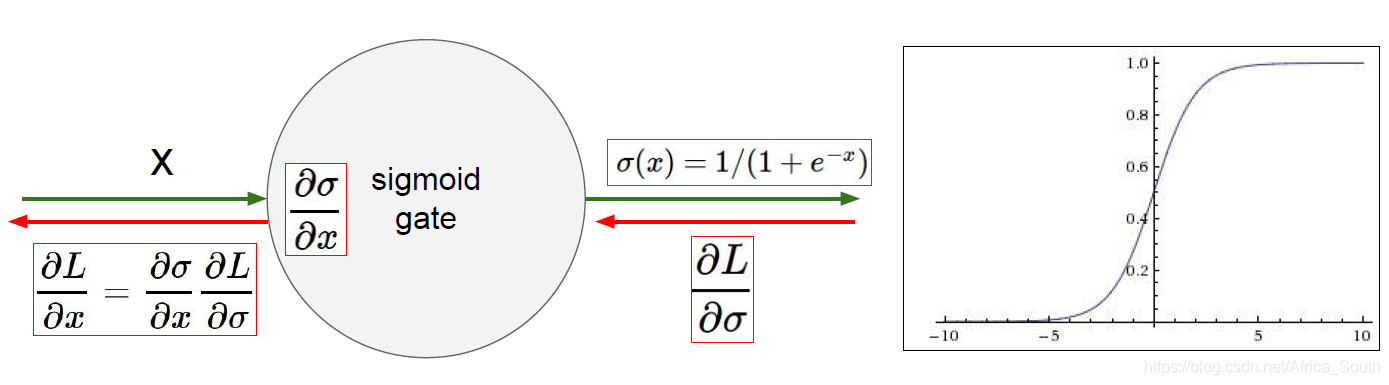
通过图像,我们可以看到,sigmoid函数在输入很大或者很小的值附近变化都很小,也代表着这附近的梯度趋近于0,所以会导致上流反传的梯度乘以一个很小的梯度,导致梯度越来越接近于0(这不利于我们权重的更新)。理论上,sigmoid的梯度表达式为:
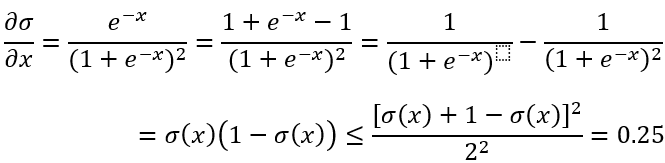
当值为0和1的时候,梯度都非常的小。 - 输出值不是以为0中心(not zero-centered),即总是正数。

考虑一个线性映射单元,其接收到的输入x总是正的(或者负的),即 对 的 局部梯度 总是正的(或负的),运用链式法则的时候就等效于我们将上游梯度的符号传回来了,意味着关于W(一个向量)的梯度的符号都是相同的。考虑右图中一个二维的W,它所允许的梯度是一象限或者三象限,所以负梯度方向就类似于两个红线方向,假设我们的期望方向是蓝线,则总是正(负)的梯度就只能锯齿前进,梯度更新比较低效。
所以,通常我们都需要输入的X的均值为0,即输入零均值的数据。
- 指数函数exp()计算代价比较高。
1.2 tanh(x)激活函数

- 将输入激活到 区间
- 输出零中心化
- 依然存在梯度消失的问题
1.3 ReLU函数
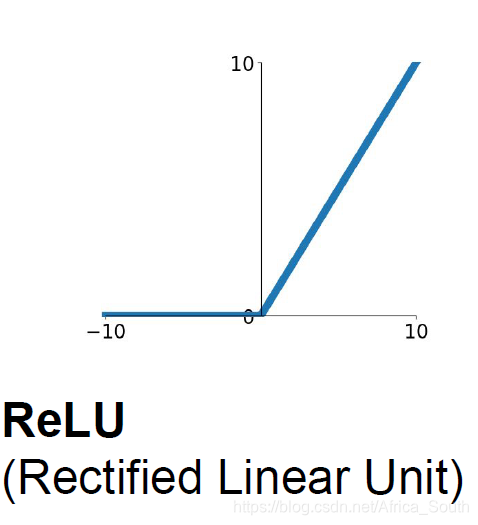
作用和优点
- ,计算代价小,收敛快(实践上比sigmoid和tanh快6倍左右)
- 按照元素操作(element-wise)
- 正半区域没有梯度消失问题
- 在生物学上比sigmoid更加合理
缺点
- 依然不是零中心化的输出
- 负半区域出现梯度消失(因为梯度为0),称之为Dead ReLU。
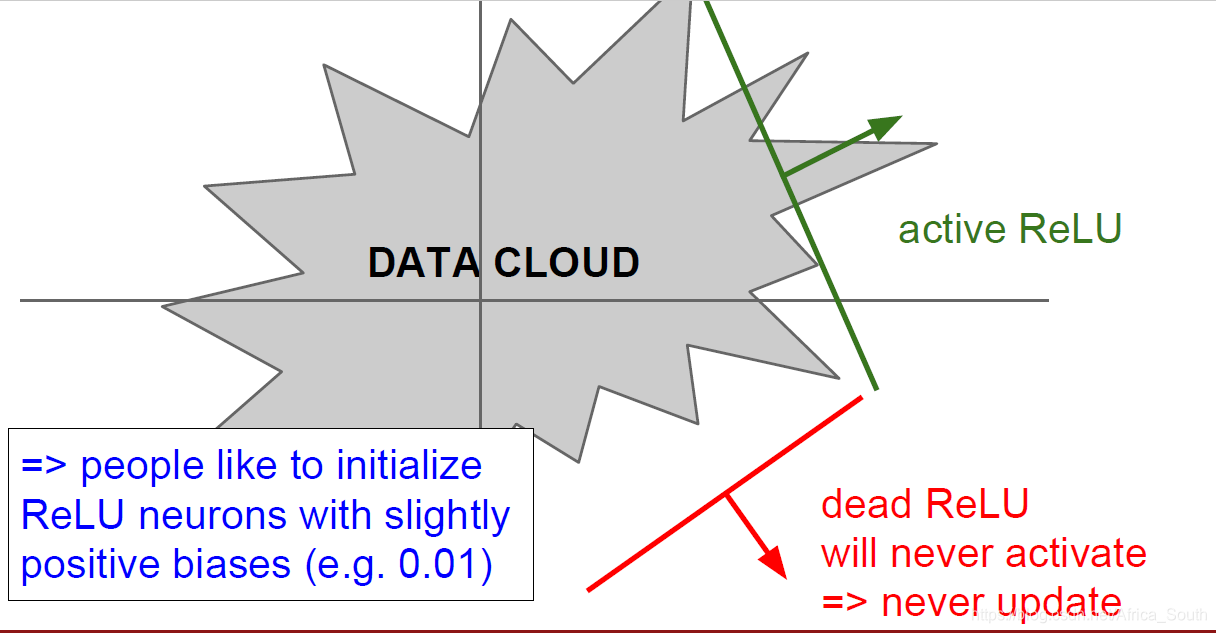
- 即当我们的权重初始化不好的时候,某些输入数据(DATA CLOUD)会使得ReLU的输入为负数,这样这些神经元就不会被更新。所以,某些人会在实践的时候给ReLu的输入偏置初始化一个小的正值。
1.4 Leaky ReLU激活函数

- 左边是 Leaky ReLU,避免了 ReLU 的一些缺点(失活)
- 输出有正有负,趋向于零均值
- 右边是参数整流单元(PReLU),其引入一个可学习的参数 ,而不是固定为0.01.
1.5 指数线性单元(ELU)
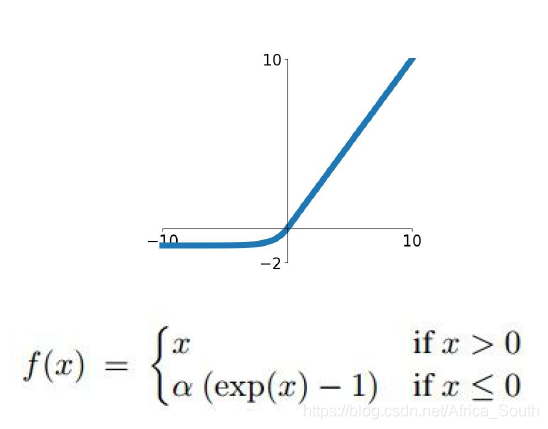
- 输出均值趋近于0(即有正有负)
- 负半轴区域不是像 Leaky ReLU那样线性,而是趋向于饱和,或许能抑制一些噪声(因为噪声输入的得分值会比较小)
- 效果介于 ReLU 和 Leaky ReLU 之间。
- 需要计算指数函数 exp()。
1.6 最大输出单元(Maxout)
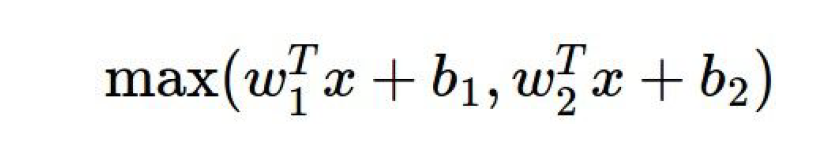
- 并不是先做点积运算(dot product),然后将激活函数运用在每个元素上(element-wise)
- 是ReLu和leaky ReLU的推广,因为其是在两个线性函数种取最大值
- 会使得参数翻倍,因为原来一个神经元的参数 ,现在是
- 没有神经元失活问题,因为每个输入有两组参数,其中一组肯定会更新
激活函数选择建议

扫描二维码关注公众号,回复:
10969032 查看本文章

2. 数据预处理(Data Preprocessing)
2.1 去均值和归一化
- 简单的预处理包含去均值和标准化
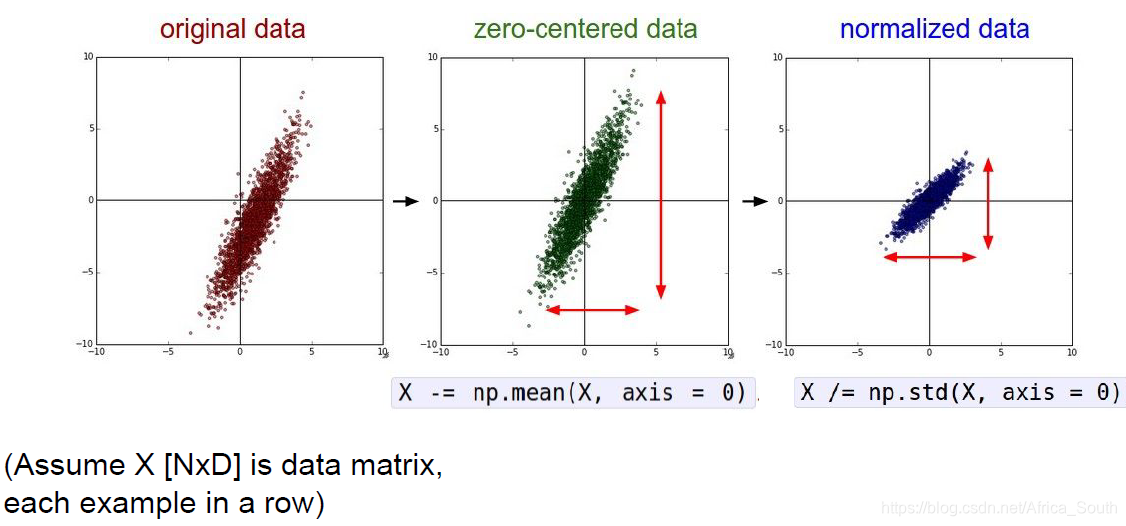
- 原因之一是之前讲过的,输入数据均为正或者负可能会导致某一层的权重各个维度朝着一个方向更新
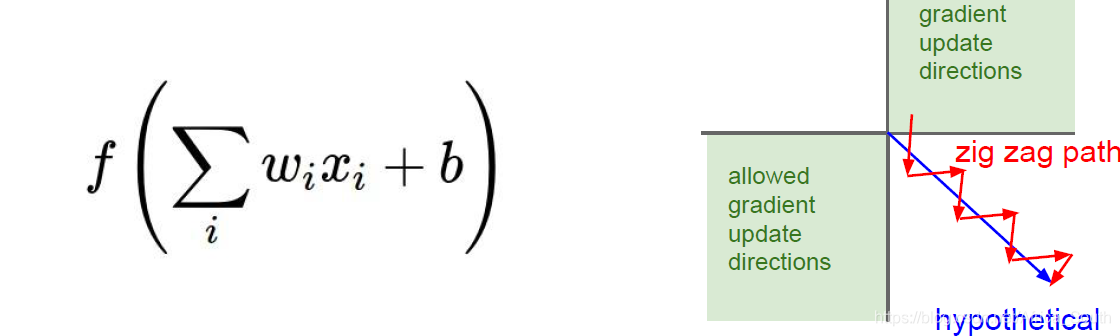
- 归一化数据,即我们有时候在概率中说的去单位化,它使得各个特征维度的特征都标准化,贡献率一致。
- 图像处理中很少用归一化,因为各个维度的特征的取值范围都差不多,但是在通用机器学习问题中,这种操作能避免某些偏差很大的特征的影响。
2.2 去相关和白化

- 图像的预处理或许只会使用零均值化,不会用这些复杂的预处理
- 或许这些处理方法适合在最后的特征表达,特征选择上使用
举个栗子

- 一般,图像中我们只做去均值化
- 有时候减去通道均值比减去均值图像更方便,因为只有3个数值。
3. 权重初始化(weight initialization)
3.1 引入
Q: 如果我们将图中的神经元的权重
都初始化为0,会发生什么?
A: 大部分神经元都表现出相似的行为(相似的输入,相似的输出,相似的反传梯度),即纵观整个神经网络的训练,我们可能会得到大量的相似神经元,这影响了我们网络的丰富性。
即会出现 参数对称问题(symmetry)。
3.2 解决方案
随机初始化
- 随机从一个分布(例如高斯分布)中选取参数

- 但是这种方法一般只在浅层神经网络中有效,深度网络中或许会出问题。例如下面这个10层神经网络,每层网络包含500个结点,而且用 激活函数。
#coding=UTF-8
import numpy as np
import matplotlib.pyplot as plt
# assume some unit gaussian 10-D input data
np.random.seed(2018)
D = np.random.randn(1000,500) # input data
hidden_layer_sizes = [500] * 10 # 10 layers with 500 nodes
nonliearities = ['tanh'] * len(hidden_layer_sizes)
act = {'relu':lambda x: np.maximum(0,x), 'tanh': lambda x: np.tanh(x)}
Hs = {} # 每一层结点
np.random.seed(8012)
for i in range(len(hidden_layer_sizes)):
X = D if i == 0 else Hs[i-1] # 当前层的输入
fan_in = X.shape[1]
fan_out = hidden_layer_sizes[i]
W = np.random.randn(fan_in,fan_out) * 0.01 # 权重初始化
H = np.dot(X,W)
H = act[nonliearities[i]](H)
Hs[i] = H # 状态保存
print(Hs[9].shape)
# 然后我们画出每一层的分布
print("input layer had mean %f and std %f" % (np.mean(D), np.std(D)))
layer_means = [np.mean(H) for i,H in Hs.iteritems()]
layer_stds = [np.std(H) for i,H in Hs.iteritems()]
for i,H in Hs.iteritems():
print('hidden layer %d had mean %f and std %f' % (i+1,layer_means[i],layer_stds[i]))
# 画出均值和方差
plt.figure()
plt.subplot(121)
plt.plot(Hs.keys(),layer_means,'ob-')
plt.title('layer mean')
plt.subplot(122)
plt.plot(Hs.keys(),layer_stds,'or-')
plt.title('layer std')
plt.show()
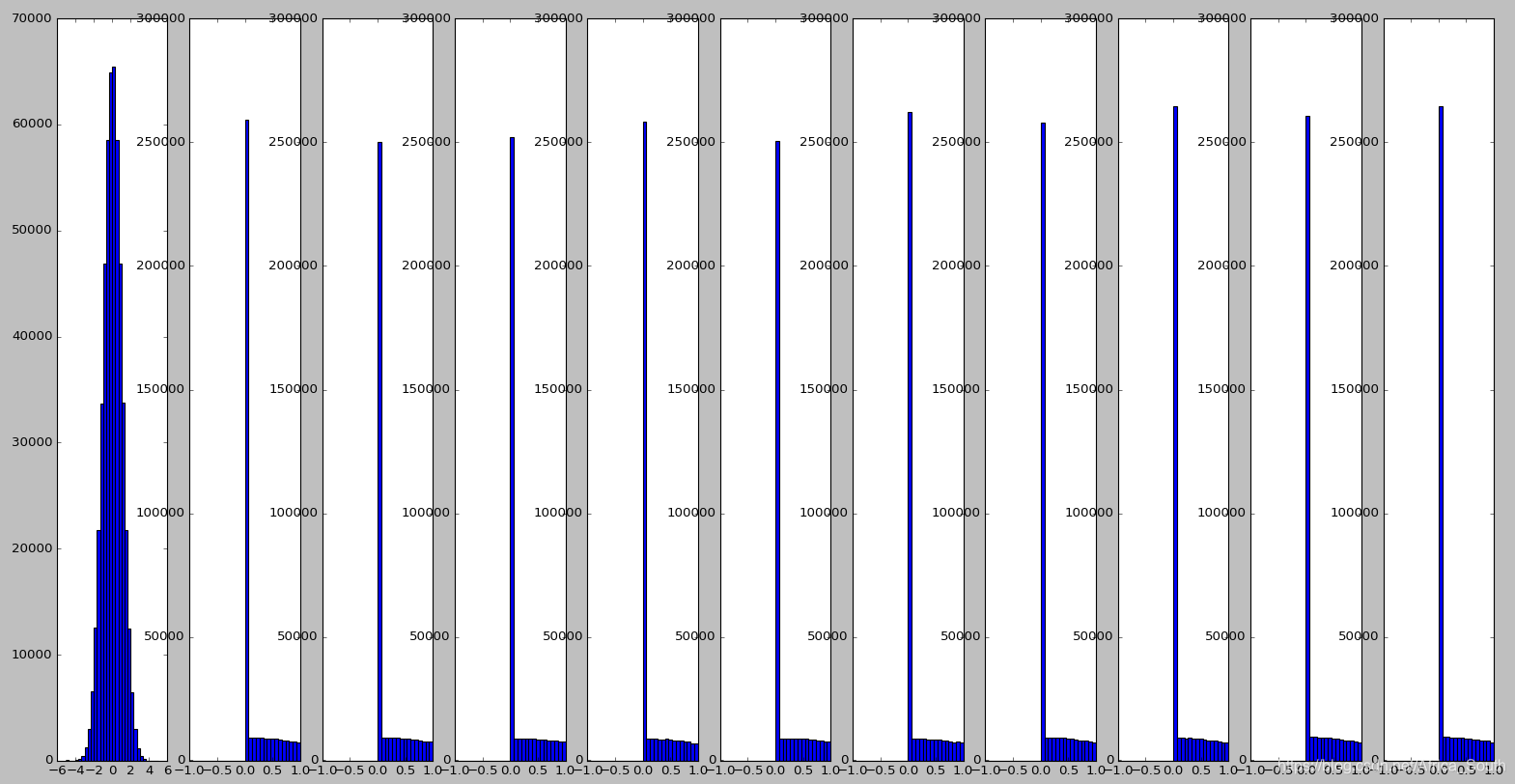
# 画出原始输入和各层神经结点的分布
plt.figure()
plt.subplot(1,len(Hs)+1,1)
plt.hist(D.ravel(),30,range=(-5,5))
for i,H in Hs.iteritems():
plt.subplot(1,len(Hs)+1,i+2)
# 每一层有500个结点, ravel()表示将该矩阵拉伸成一个一维数组(1000 * 500)
plt.hist(H.ravel(),30,range=(-1,1))
plt.show()
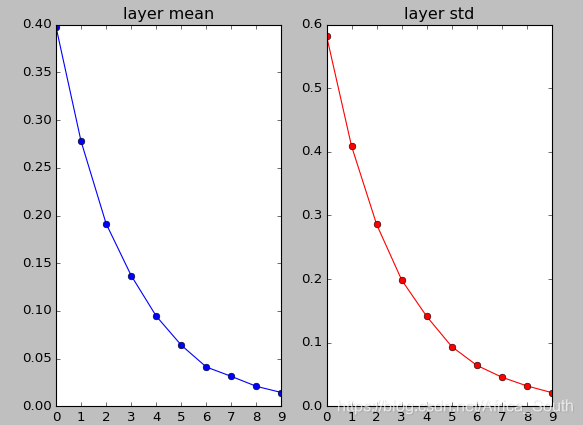
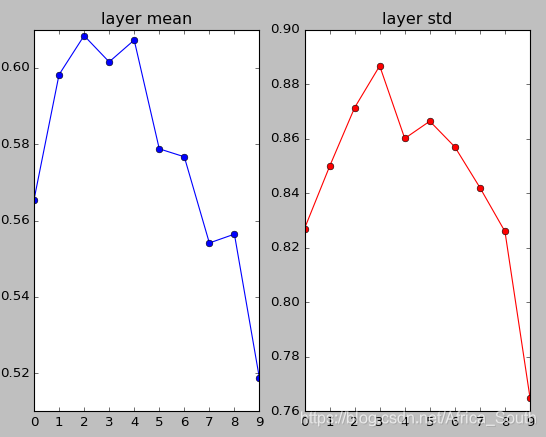
- 我们第一次,初始化一些比较小的符合高斯分布的权重,可能会得到下面实验图像:
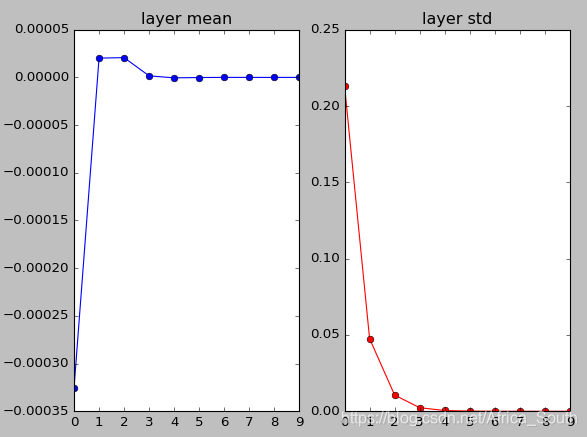

- 根据上图,我们能得到,我们的神经元激活值会逐渐趋近于0,因为我们使用的是点乘
操作,而很小的权重可能导致神经元的输出逐渐趋近于0,且方差越来越小,同时使用
激活,输出依然是零均值的。
这就导致了,当我们反传梯度的时候,上流梯度分配给权重的梯度乘上x也会非常的小,这就导致了 权重几乎没有更新。 而传给下层的梯度乘上 W 后也会越来越小并趋近于0。
- 这一次,我们增大权重的初始值,看看会发生什么?
W = np.random.randn(fan_in,fan_out) * 1 # 权重初始化
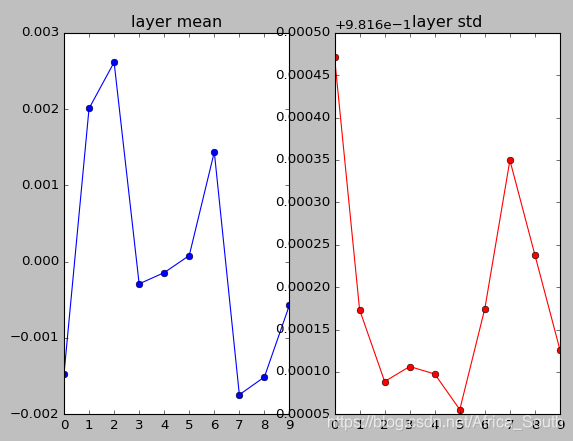

- 可以发现,大的权重导致不断的乘积下我们的神经元逐渐趋向于饱和,即输出为1或者-1(tanh激活后)。
这就导致了我们得到的梯度为0,神经元将不再更新。
根据我们神经元的分布情况初始化
由上面的实验,我们有,当权重太小的时候,网络崩溃;权重太大,网络饱和的问题。所以,有很多研究者提出各种权重初始化方式。
3.3 Xavier 初始化

- 从高斯分布中取样,并根据输入神经元个数进行缩放。
- 初衷是 输入的方差等于输出的方差,直观上少量的输入需要乘以大的权重以平衡输出的方差与输入相同,保持相同的分布进行传播。
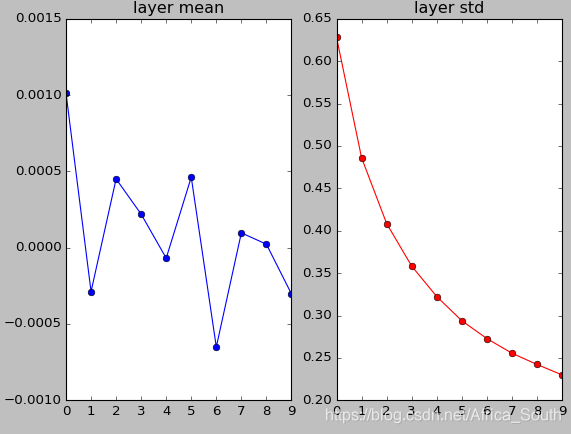
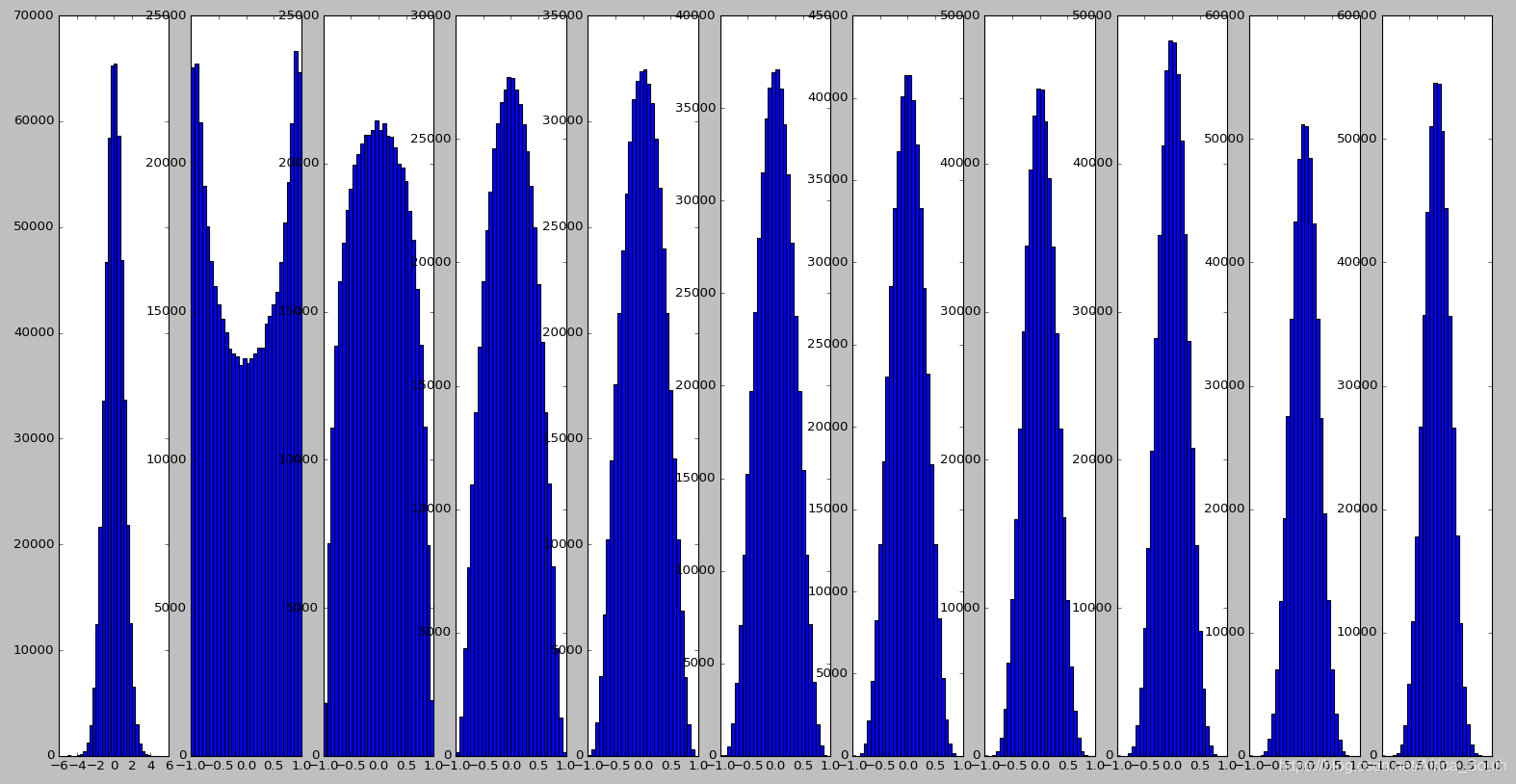
- 所以,当我们每一层的输入都是单位高斯分布的时候,使用 初始化会在每一层都得到一个高斯分布。
- 但是,当使用
激活函数的时候,它可能会随机将一半的神经元屏蔽掉,导致方差只有原来的一半。导致高斯分布会不断收缩,最后只存在0附近的一个单峰,使得神经元逐渐失活。
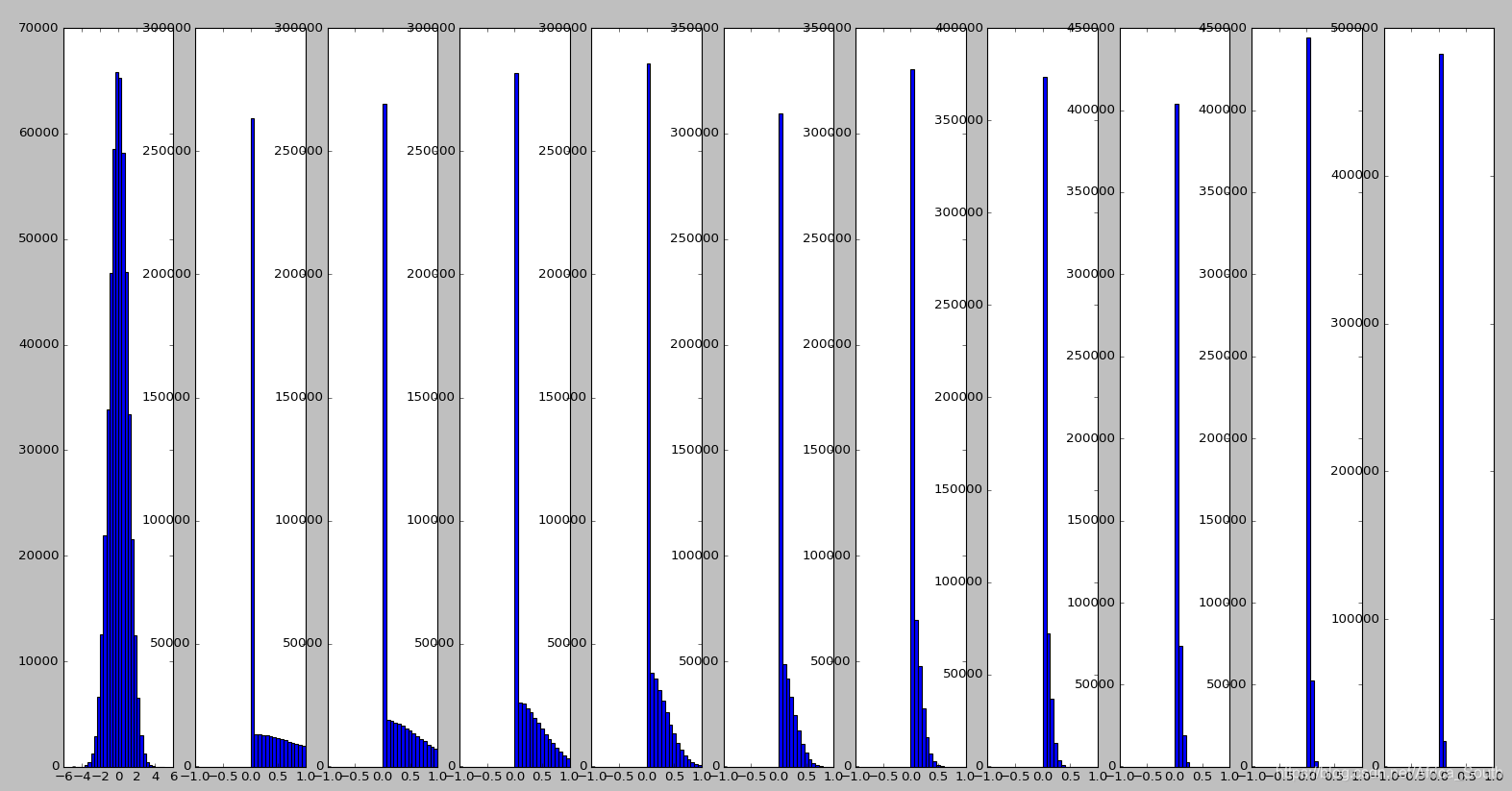
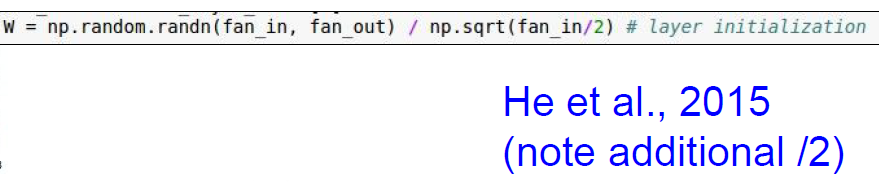
3.3 He et al 初始化
- 为了解决上诉问题,He 在2015年中建议,将缩放因子除以2,因为
会造成一半的神经元屏蔽,导致我们实际的输入其实只有 ReLU激活前的一半。
- 这样,我们能一定程度上避免最后神经元集中在 附近。
4. 批量归一化(BatchNorm)
批量归一化让我们的输入数据在高斯范围内保持激活,即


- 它在输入的一批数据的 每一个维度上都进行归一化,得到一个 单位高斯 输出,因为在之前我们谈到,具有零均值的数据有时候是利于网络训练的。
- 而且它还是一个可微函数,因为我们的均值和方差都是常数。
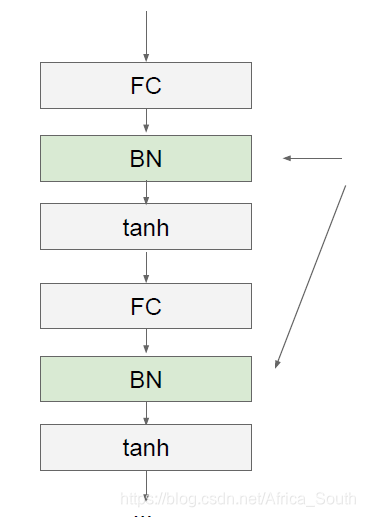
- 通常我们的批量归一化层放在全连接层和卷积层的后面,因为这些层我们会不断乘以权重W,造成不同程度的缩放。而且,在卷积层后进行批量归一化,我们不仅会BN每一个维度,而且空间上,我们也会BN同一个激活图(activation map)。
Q: 卷积后进行归一化是在一个卷积核内的激活图进行归一化还是在整个特征图(feature map)上进行归一化? - BN在一定程度上能避免饱和,但是有时候一定的饱和可能有利于我们神经元的处理,比如我们会对某些数据进行抑制,所以,BN还有一种改进:

- 即我们格外学习两个缩放参数 和 来进行部分还原。特别的,当学习到右图所示的时候,这是一个恢复的恒等函数。
- 所以,我们最终的BN层计算如下:

- 同时,BN操作会减少之前提到的学习率(可以设置更大的学习率)和权重初始化带来的影响,使得训练更加鲁棒。
- 而且,它也是一种正则方式。因为,我们得到的均值和方差是一个批次里的,它是一个经验值,而且是不断变化的,就像在输入X中加入了抖动,实现了正则化的效果。
5. 观察训练过程并调整参数
5.1 训练过程
- 数据准备与预处理
- 选择网络结构
- 损失完整性检查
- 例如之前我们的C分类softmax分类器,在初始化小权重之后,得到的初始损失应该是

- 接下来,加入正则项,看损失是否增加。
- 然后在一个 小数据集 上进行测试训练,同时关闭正则惩罚,看我们的准确率是不是不断接近于1(即多次迭代之后有没有很好的拟合训练集)
- 确定正则惩罚,然后开始调试比较优的 学习率(这个参数很重要)。
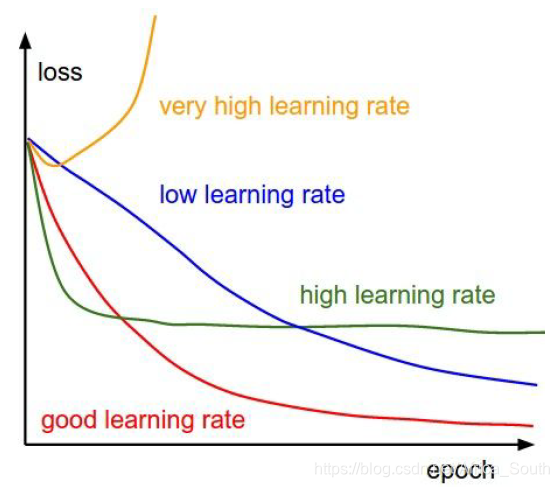
下图中损失变化很小,可能是学习率太小。 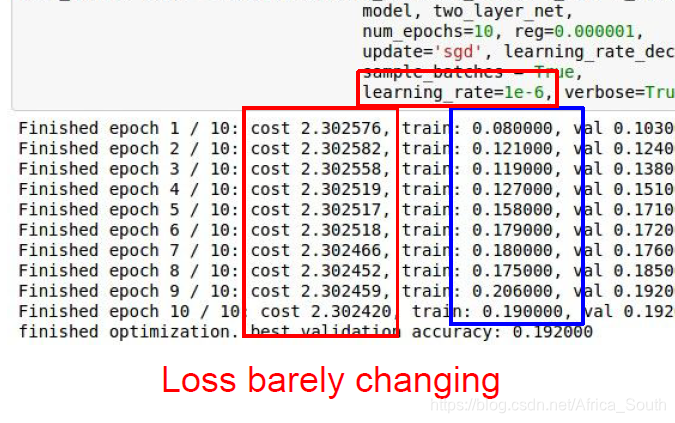
下图可能是学习率太大,导致损失NAN。
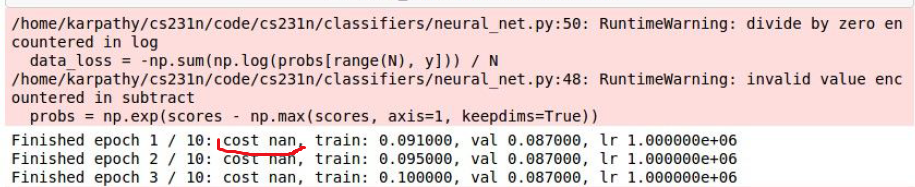
- 一般我们的学习率在 ,也取决于我们损失的变化。
5.2 超参数调优
- 使用交叉验证,且 超参数从粗到细进行调节(先用几个epoch来看损失的变化情况,再在这个粗的范围内进行微调)
- 一般我们的超参数都是在
区间中找,即
中,例如:
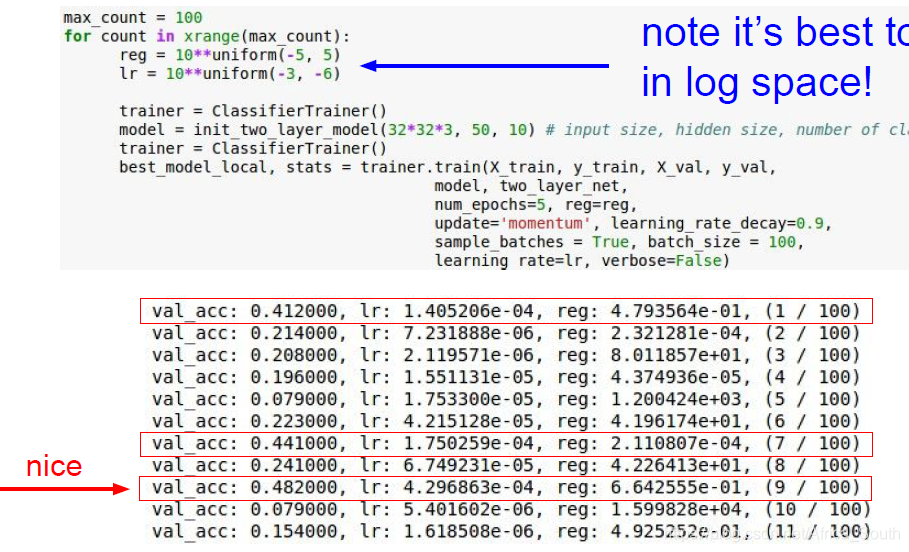
- 我们能初步锁定一个区间,它在
左右表现良好,然后我们进一步改变区间:

- 一般我们的超参数都是在
区间中找,即
中,例如:
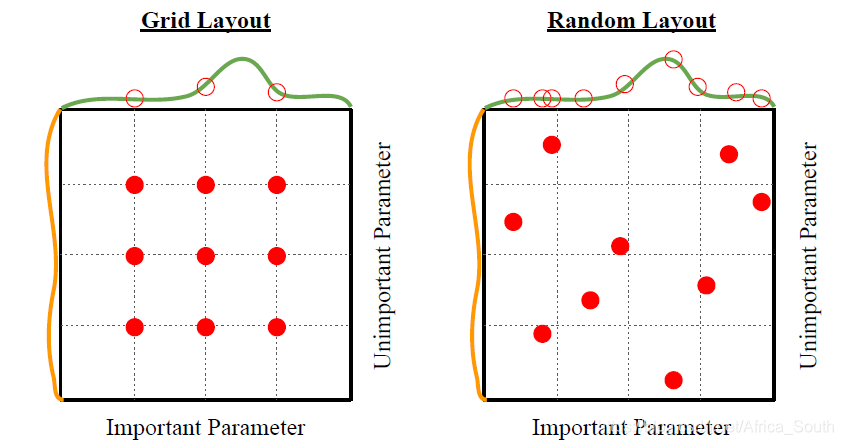
- 网格搜索(固定一组参数进行采样)和随机搜索
6. 总结

扩展阅读
网络权重初始化
- Understanding the difficulty of training deep feedforward neural networks by Glorot and Bengio, 2010
- Exact solutions to the nonlinear dynamics of learning in deep linear neural networks by Saxe et al, 2013
- Random walk initialization for training very deep feedforward networks by Sussillo and Abbott, 2014
- Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification by He et al., 2015
- Data-dependent Initializations of Convolutional Neural Networks by Krähenbühl et al., 2015
- All you need is a good init, Mishkin and Matas, 2015
批量归一化
- [Ioffe and Szegedy, 2015]
