Part I :
- Activation Functions
- Data Preprocessing
- Weight Initialization
- Batch Normalization
- Babysitting the Learning Process
- Hyperparameter Optimization
-
Activation Functions


-
Sigmoid

问题:
1.梯度消失

2.非零中心 ------> 梯度更新低效

3.指数函数的计算代价高
-
tanh

以零为中心,但还是没有解决梯度消失的问题
-
ReLU

计算速度快,收敛速度快,在正半轴不会饱和
不是以零为中心,在负半轴饱和(包括0)

dead relu不会被激活或更新,导致的原因:
(1)权值初始化不好
(2)学习率太高 ---> 权值波动大
-
Leaky ReLU

-
PReLU

-
ELU

-
Maxout

-
In practice:

-
Data Preprocessing
一般会做零中心化处理
![]()
不总是做归一化
![]()
仅作中心化的方法:

-
Weight Initialization
1. 初始化为0时(相同的值)
神经元会做相同的事情,没有打破参数对称问题
2. 初始化为很小的随机数
![]()
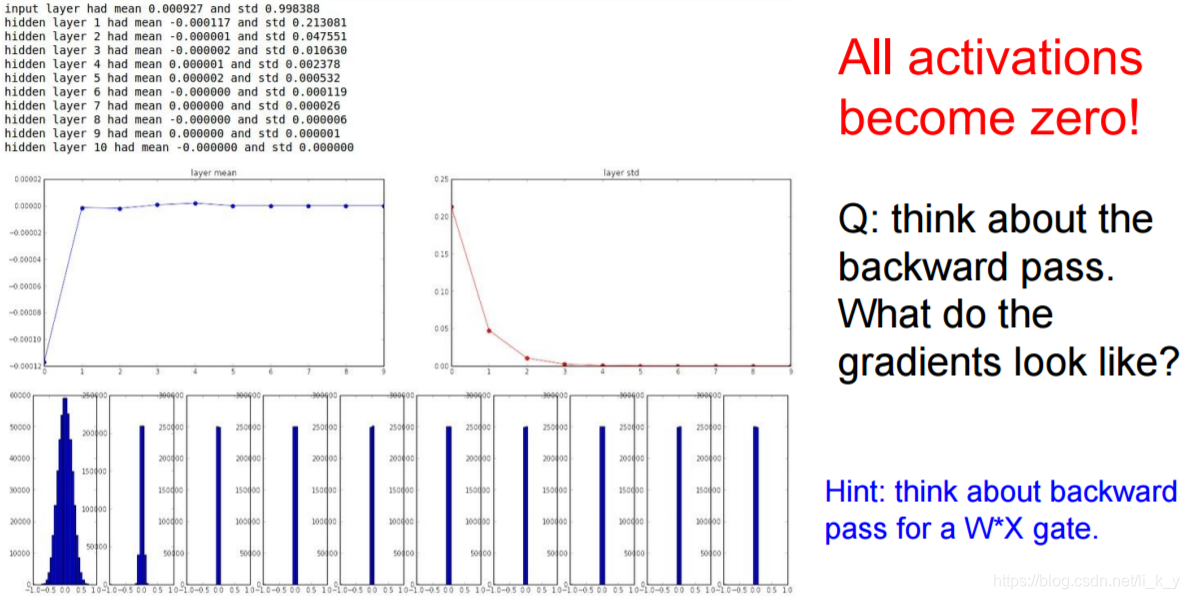
梯度会趋近于0
3. 初始化在高斯分布(-1, 1)中
![]()
会饱和(在tanh中)

4. Xavier (tanh)

5. Xavier (ReLU)

-
Batch Normalization
- 减少坏初始化的影响
- 加快模型的收敛速度
- 可以用大些的学习率
- 能有效地防止过拟合

归一化 + 缩放,平移



-
Babysitting the Learning Process
- Step 1: Preprocess the data

- Step 2: Choose the architecture
- Step 3: Double check that the loss is reasonable


- Step 4: try to train
1. Make sure that you can overfit very small portion of the training data

Very small loss, train accuracy 1.00, nice!
2. Start with small regularization and find learning rate that makes the loss go down.

loss not going down : learning rate too low
3. try a big learning rate

loss exploding : learning rate too high
4. Rough range for learning rate we should be cross-validating is somewhere [1e-3 … 1e-5]
-
Hyperparameter Optimization


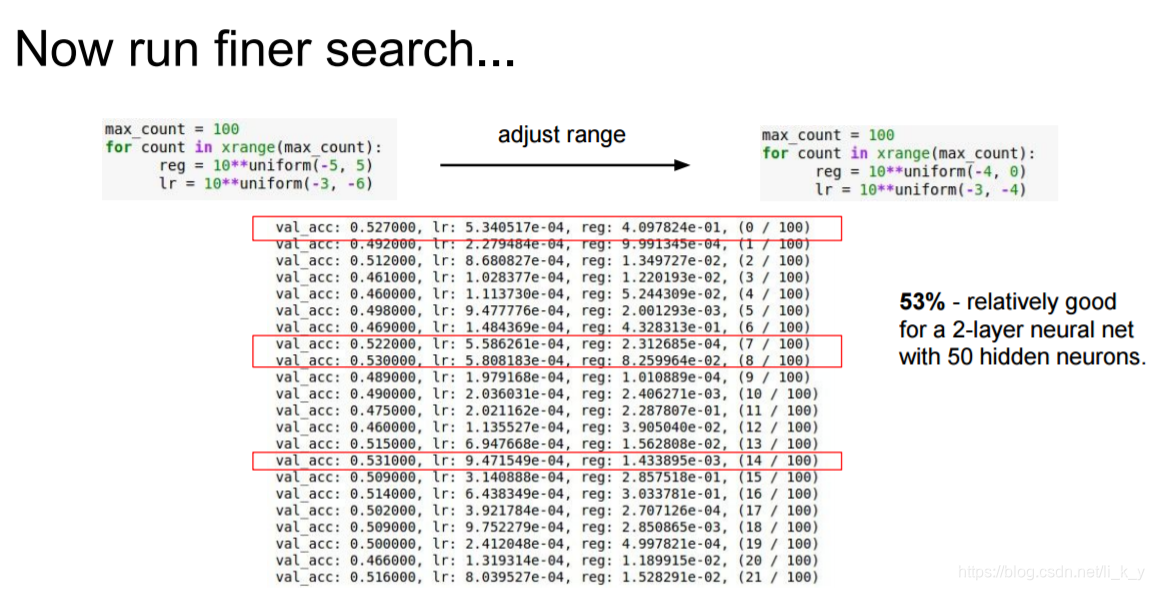
问题:不能在空间上充分寻找,寻找范围是有限的
Random Search: More sample

Hyperparameters to play with:
- network architecture
- learning rate, its decay schedule, update type
- regularization (L2/Dropout strength)




-
Summay

