一、Commonly used activation function
1. Sigmoid
- 贴图
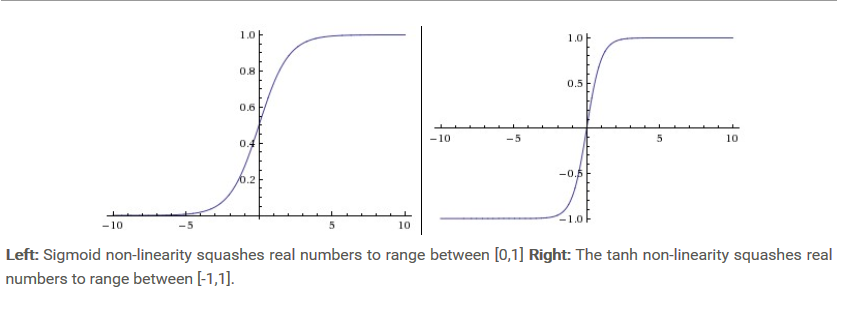
目前使用变少,主要存在以下缺点:
- 存在梯度爆炸和梯度消失,在反向传播的时候容易出现梯度消失,而在初始化权重参数时,容易出现梯度爆炸,就网络不怎么进行学习。
- 不是以零为中心的, 可能出现的问题就是在反向传播的时候,梯度总是正的或是负的,会出现不好的动态参数更新。
2. Tanh
-
贴图
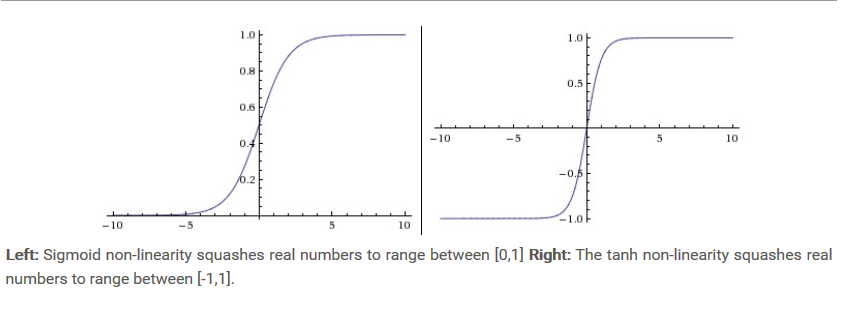
-
还是存在梯度爆炸和梯度消失的问题,但是以零位中心了。Sigmoid的第二个问题不存在了。
3. ReLU
-
贴图

-
最近这几年是比较受欢迎的激活函数。
优缺点:
- 发现随机梯度下降法收敛速度大大加快与Sigmoid和Tanh相比较。
- 计算花费较少。
- 可能出现梯度变0,无法再进行梯度更新。
二、Neural Network architectures
- 我们一般约定在说神经网络层数的时候,不包括输入层。
- 我们不能因为害怕过拟合就使用小的网络,我们应该使用正则化来减少过拟合。
三、Data Preprocessing
- Mean subtraction: zero-centered是通过减去每个维度的均值,意思就是将数据的中心点变成原点;normalized(归一化)就是对数据进行缩放,有几种形式,一种是缩放到0 ~ 1之间,也可以缩放到-1 ~ 1之间。标准化,就是变成均值为0, 方差为1的形式。
- SVD是啥???
- 白化操作以特征基中的数据为基础,将每个维数除以特征值对尺度进行归一化处理。
- 常见的陷阱,就是数据预处理的时候,计算数据平均值仅仅是计算训练集中,然后用此平均值再在(训练集,验证集,测试集)中相减,而不是所有数据进行计算平均值,然后相减再划分数据集。
- 这一块没有看懂,需要后续补线性代数的知识。
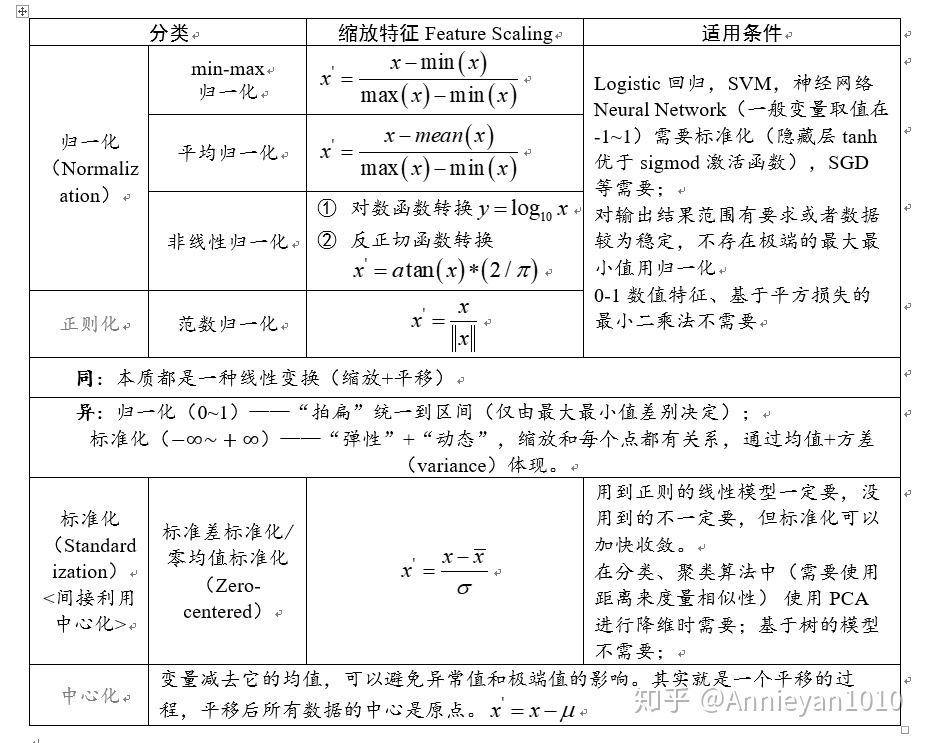
四、Weight Initialization
- 常见的问题就是:
- 所有权重都初始化为0,这样是不行的,因为每个神经元都会计算出相同的结果,在反向传播的过程中即梯度计算都会更新相同的参数,合理的初始化是一半权重为正和一半权重为负。
- 初始化的权重,我们想要能够尽可能接近于0,也就是随机初始化的权重尽可能的小。但也不是说越小的数字越好。例如在神经网络层中,如果初始的权重太小就会出现反向传播的梯度很小。
- 推荐的启发式方法是将每个神经元的权向量初始化为:
w = np.random.randn(n) / sqrt(n),其中n为输入的数量。 - 在ReLU激活函数中,推荐的初始化方法是:
w = np.random.randn(n) * sqrt(2.0/n)
- 批量归一化(Batch Normalization):用于增强鲁棒性,也是作为每个网络层之前的预处理,以一种可微的方式融入网络本身。
五、Regularization
- 用于防止网络过拟合
- L2正则化: 如果不是关注于明确的特征选择,L2正则化优于L1正则化。偏重于发散数据和严重惩罚峰值权重向量。
- L1正则化: 仅仅使用最重要的一个稀疏的数据,不受噪声的影响。
- Max norm constraints: 对每个神经元的权向量大小施加一个绝对上界,并使用投影梯度下降来施加约束。它的一个吸引人的特性是,即使在学习率设置得太高时,网络也不会“爆炸”,因为更新总是有限的。
- Dropout: 是一个很有效的方法。通过保持一个神经元以一定的概率p(超参数)激活,或者将其设置为0,就可以实现dropout。(贴图)

六、Loss functions
-
SVM(贴图)
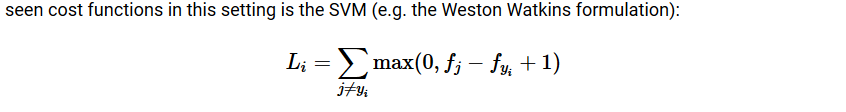
-
Softmax
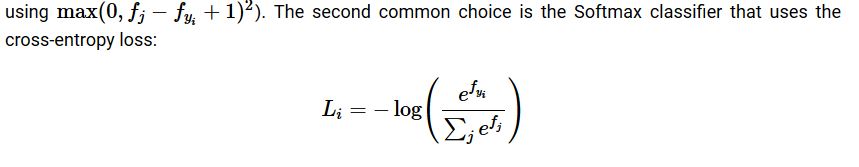
-
L2 loss :是更难以优化的相比于稳定的Softmax, 同时它的要求非常高,鲁棒性较差,因为极端值可能会导致巨大的梯度。