训练神经网络
我们先来看这部分内容的综述,主要介绍了在训练网络中的一些基本方法与基本概念

激励函数(Activation Functions)
首先我们来看看神经网络用的激励函数之间的对比

Sigmoid函数主要有一下三个问题,第一是函数存在饱和区,这部分函数梯度基本为0,导致权重不会变化;第二是函数输出不是以0为中心;第三是指数函数计算量比较大

对于第二点我们重点说说,假如输出不是以0位中心那会出现什么问题呢?我们知道在神经网络中上一层的输出会作为下一层的输入,因此当上一层输出经过Sigmoid函数以后,我们将的到一个全为正的输出作为下一层输入,那么根据链式法则,我们知道对某个特定权重wi的导数等于上一层的导数乘以xi,由于xi全是正的,那么意味下一层权重wi的导数全为正或者全为负,代表所有权重只能朝相同的方向变化,大大限制了收敛的方向

tanh函数解决了输出全为正的问题,但是任然存在激励函数饱和的问题

ReLU激励函数是比较好的,也是我们在神经网络中用的比较多的激励函数。它在正区域不存在饱和区,计算起来也非常简便,但是他也存在不是以0为中心输出的问题
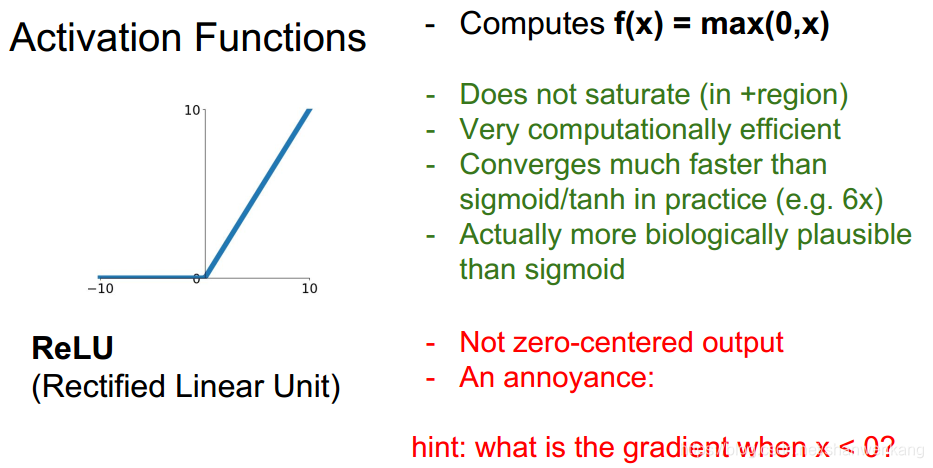
但是不好的是ReLU在负半区域导数仍然为0,这就意味着任然有出现死区,导致权重无法训练的可能

于是我们又有了一些对ReLU函数的改进解决了以上的问题

以及提出的一些新激励函数,比如ELU与Maxout


但是ReLU函数一般满足了我们大部分需求

数据预处理(Data preprocessing)
我们在训练网络的时候一般需要对数据进行预处理,包括均值归0与归一化等操作,这样做的原因是我们考虑之前讲的,如果输入数据全是正的,会导致某一层权重只能朝相同方向变化,从而导致训练缓慢的问题。但是这不代表我们进行数据预处理以后就可以采用Sigmoid函数了,因为在网络的深层还是可能出现这个问题。
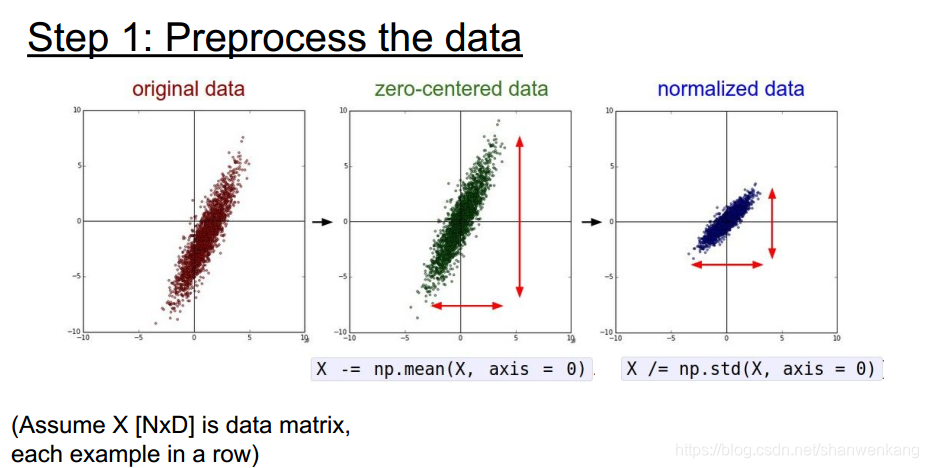
在实践中我们还可以采用降维的操作来处理数据

我们下面还可以举一个例子说明数据初始化的好处。如果我们在训练一个线性分类器,那么对于如下数据若不是分布在原点周围,分类结果会对权重变化非常敏感,因此我们需要权重在一个非常苛刻的区间内才能有很好的分类效果;如果数据分布在原点周围的话那么分类结果可以接受权重在一定范围内变化,这种情况下训练变得比较简单

权重初始化(Weight Initialization)
权重初始化也是一个非常重要的问题,我们先考虑在神经网络中如果我们直接将权重全初始化为0会出现什么问题。这样不管输入什么,我们每一层神经元的输出都将是一样的(因为权重是0,因此输出与输入无关),这样每一个神经元的导数都是相同的,那么产生的问题就是所有的权重的变化都是一样的,这样显然是不行的

为了解决这个问题,我们来看看几种解决方案,第一种是采用小随机数

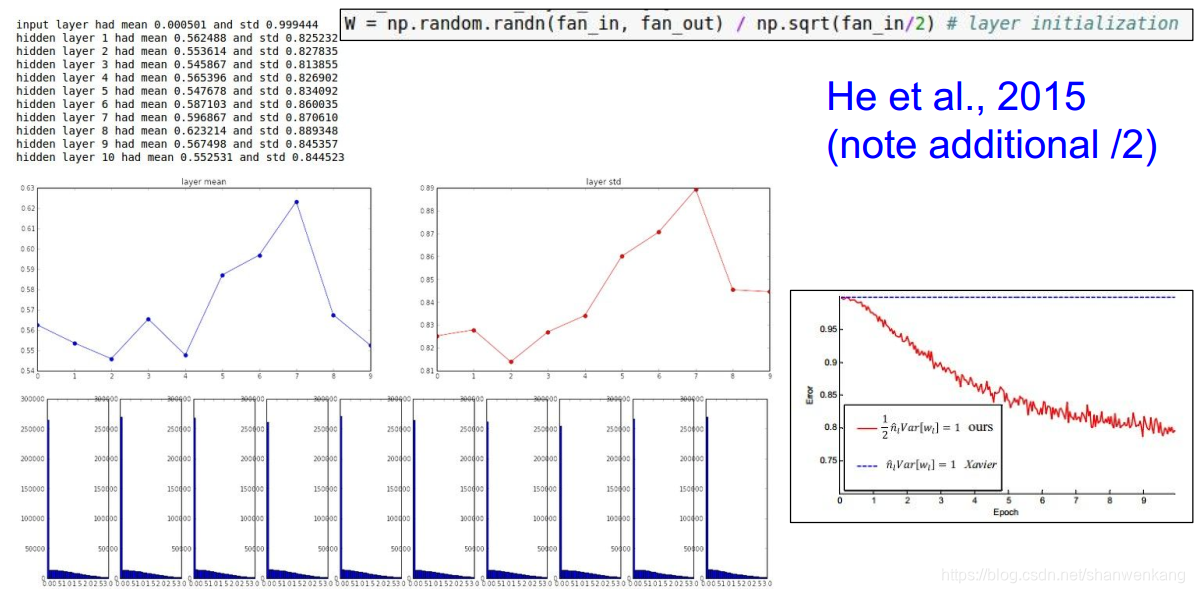
但是随着层数增加,权重太小会导致输出的值不断减小,最后这个值会接近于0,这样我们在计算导数的时候也会得到一个接近于0的值,这样权重就无法改变了(下图左侧图例的含义是每一层输出值的分布)

如果我们将随机化初始值增大,那么会出现的问题是由于权重太大,每一层的输出都会饱和,这种情况下导数也会变成0

一种好的初始化方式是Xavier初始化,它能够根据每个神经元输入个数来调整权重的初始化值,来保证输出的值能满足高斯分布的特征

但是当我们采用ReLU激励函数的时候以上方法又会失效,因为ReLU只有正半区域有值,我们可以将ReLU看作将输入值减半,直接把初始化的值除以2,这样修改能使我们获得比较好的效果
批归一化(Batch Normalization)
我们刚才讲了我们想要线性函数输出的值满足高斯分布,这样在进入激励函数以后不会存在太多的点处在饱和区导致权重无法调整。那么既然是这样,我们可以直接调整这个值,人为地让它满足高斯分布,这就是批归一化的思想。我们要做的是计算每个特征在一批内对于不同训练样本的均值方差然后做归一化

我们一般把批归一化放在全连接层或者卷积层的后面

我们想到有的时候线性输出的值全处在非饱和区内不一定是最好的,因此我们给予BN一个自由调整的空间,能够让它自动学习让多少的值处在饱和区内能取得最好的效果

以下是批归一化的总结,要注意的是我们在训练的时候会不断计算一个批内的均值与方差,但是在测试的时候我们不可能每次都重新计算这个值,因此我们往往采用的是训练时候的经验平均

训练过程监控(Babysitting the Learning Process)
下面让我们来看看如何进行训练,第一步是数据预处理

第二步是选择网络的结构

之后计算初始的损失值,利用不同激励函数的特点来验证这个值是否正确,需要注意的是如果加上了正则项,那么这个值会略有上升

之后我们需要找到一个合适的学习速率

一般来说损失函数基本没变化意味着学习速率太小,出现Nan值说明学习速率太大,算法无法收敛

混合参数优化(Hyperparameter Optimization)
对于混合参数的优化,我们需要不断在验证集上进行验证,来寻找到参数的最优的一个区间

我们让参数的值在一个区间内变化(在log空间),再根据准确率不断调整这个区间来找到最优解

这样相当于对混合参数进行了一次采样,而且是在log空间的均匀采样,而这样采出的样本不够精细,因此我们有时候会采用随机采样的方法来保证我们在一个区间内能获得更多的样本点。即我们将图一中重合的三个样本点分散开,来保证我们在重要参数上能取得更多的样本

以下是不同损失函数对应不同的学习速率大小

一般出现如下图的时候我们会怀疑是权重初始化太差了

我们还需要不断观察网络在训练集与测试集上的表现以及二者的差距,一般差距太大表示过拟合了,我们需要增大正则化的强度;差距太小代表欠拟合了,我们需要加强网络的复杂性,即增加网络参数个数

一般来说我们需要监控权重的变化值与绝对值的比例在一个合适的范围内来保证权重的变化不会过大或过小

以下是本节的一个总结
