part II :
- Fancier optimization
- Regularization
- Transfer Learning
-
Optimization
Problems with SGD
1.

当我们在水平方向变化时,损失函数的变化非常慢
而在竖直方向(等高线方向)变化时,损失值变化很快
在这样函数上,SGD:
Very slow progress along shallow dimension, jitter along steep direction

2. 局部极小值(local minima),鞍点(saddle points)
local minima:

Zero gradient, gradient descent gets stuck
saddle points:

Saddle points much more common in high dimension
解决方法:
SGD + Momentum


Nesterov Momentum


用换元法改进一下,以便于求loss,gradient

AdaGrad


当沿一个轴有很小的梯度时,在更新参数时除以累加梯度平方,得到一个比较大的值,从而加快学习速度
当沿一个轴有很大的梯度时,在更新参数时除以累加梯度平方,得到一个比较小的值,从而减慢学习速度
随着时间的增加,步长会越来越小,这一特点在凸函数中表现很好,但在非凸函数时会有问题 ---> RMSProp
RMSProp

Adam(almost)

在第一次循环的时候,second_moment 可能接近0,会导致步长非常大。---->
Adam (full form)

About learning rate


通常首先选择一个不带衰减的,不错的学习率,查看结果如何,仔细观察损失曲线,决定在哪个地方开始衰减
二次逼近





模型集成
用于减小训练和测试之间的误差差距



-
Regularization
提升单一模型的表现,防止过拟合
1.

2. dropout




若是在意 test 的效率,也可以:

3. Batch Normalization
加入一些随机性的元素:

4. Data Augmentation
可以做水平翻转
可以抽取不同尺度大小的裁剪图像,在测试时,评估一些固定的裁剪图像

可以做色彩抖动:

还可以:

5. DropConnect

6. Fractional Max Pooling

7. Stochastic Depth

-
Transfer Learning
在小样本中更好的训练,防止过拟合
冻结前部分,调整后部分


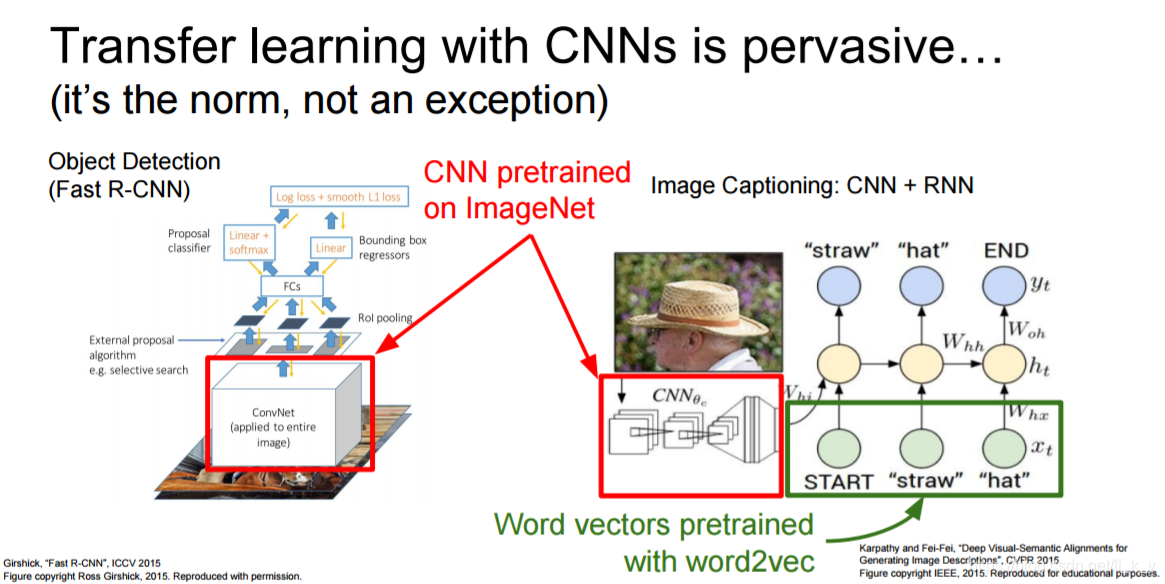
数据集很小时:
1.找到一个有类似数据的非常大的数据集,在那里训练一个大的convnet
2.在你的数据集做迁移学习

Caffe: https://github.com/BVLC/caffe/wiki/Model-Zoo
TensorFlow: https://github.com/tensorflow/models
PyTorch: https://github.com/pytorch/vision
-
Summary

