
预训练模型的出现对于NLP各个子领域都具有里程碑式的意义,不管是在文本分类,还是在阅读理解,甚至凡是和文本数据相关的任务都想着使用预训练模型来解决。尤其是以BERT为代表的众多模型的思想,甚至被推广到了CV和语音领域的任务中。那么如何对现有的诸多预训练模型做合理的分类,尽力弄清楚黑盒里所隐藏的秘密,并将其很好的应用于下游的具体任务中,对于任何具体的应用场景都十分重要。
本文从以下四个方面对于现有的预训练模型进行了梳理和展望:
- 从背景知识、模型架构、预训练任务等不同的角度对于各种预训练模型做一个回顾和总体的理解
- 从不同的视角对现有的模型进行分类
- 描述了如何将预训练模型更好的应用于下游的任务
- 对于预训练模型的未来进行展望,提出了可能的发展方向
从最初的NNLM到word2vec、Glove、fasttext等静态词向量模型,以及发展到今天的各种预训练模型,它们本质上都是希望可以从数据中学习到关于词或文档更好的表示。对于词来说,一个好的表示向量应该可以表示一种通用性很强的先验知识,并且它不限定于某个具体的任务,从而帮助模型更好的解决任务。因此,从向量表示模型的发展中,我们也可以看出结果越来越向美好的初衷靠拢。
good representation should express general-purpose priors that are not task-specific
but would be likely to be useful for a learning machine to solve AI-tasks.
自然语言处理中的表示模型的通用架构如下所示:
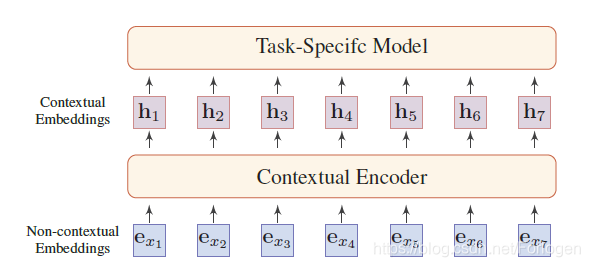
输入序列中的每个token经过编码器都可以获取到对应的表示向量,对于不同类型的编码器来说,得到的表示向量可能有所不同。如果编码器是类似于word2vec的架构,那么得到的词向量是静态的,即它无法根据具体的上下文环境变化;如果编码器是类似于BERT等类似的架构,那么得到的表示向量就属于上下文表示向量(Contextual Embedding),它可以较好的解决一词多义问题。
常用的编码器架构有卷积模型、序列模型和全连接模型,它们用不同的方式进行表示向量的学习:

此外还有基于图的表示模型, 它将词作为图中的节点,利用词与词之间的所存在语言学上的结构来学习表示向量。
预训练模型从不同的视角可以进行多种多样的分类,文中给出了一个总结性的分类图和表:
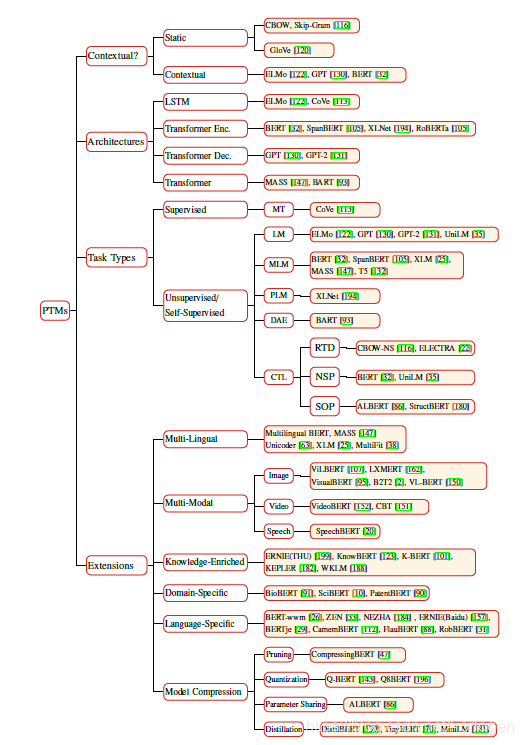
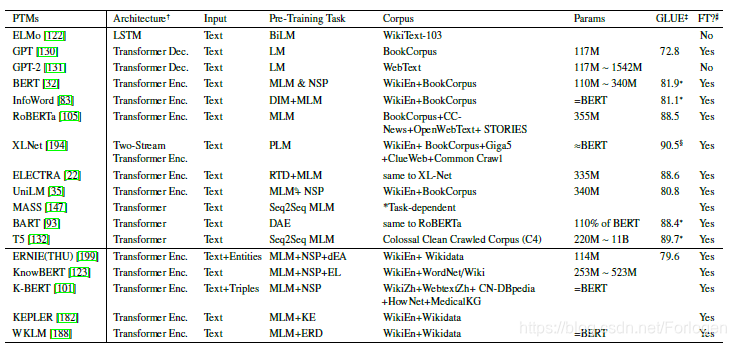
从现有的预训练模型来看,模型的基础架构普遍都倾向于Transformer,不同之处在于层的堆叠数多少不同。预训练阶段所使用的语料库通过质量较高,规模巨大,对于不同的预训练模型来说差别不是特别大。而不同的预训练任务对于模型最后的效果具有很大的影响,因此,目前的一个研究热点就是如何设计更为优秀的预训练任务来在同样的语料库和模型架构的基础上提升预训练模型的性能。
现有的预训练任务大致可分为三类:
- 有监督学习
- 无监督学习
- 自监督学习
它们和深度学习的分类是一致的。具体来看,常用的预训练任务有如下几种:
- Language Modeling(LM):LM使用自回归方式的语言建模任务来间接的学习表示向量,即建模 。由于语言建模任务自回归的本质,在获取某个词的表示向量时只能依赖于已经产生的序列,而无法使用它后面序列所表示的信息。即使采用双向的方式进行拼接,正向或是反向的单一方向上仍然受限于自回归的建模方式
- Masked Language Modeling (MLM):MLM的预训练方式广泛的应用于BERT及相关的各种变体中,它通过整体的序列信息来预测MASK的部分。MLM的整体思想类似于CBOW,及通过上下文来预测某个部分,不同之处在于CBOW使用的是窗口内的词,而MLM使用的是整个的序列信息
- Permuted Language Modeling (PLM):PLM的提出是为了解决MLM中[MASK]并不会在fine-tuning阶段出现而导致的不一致问题,对于给定的序列,PLM首先从所有可能的排列中随机抽样一个排列,然后将所选择的排列中的某些token作为目标,训练模型根据其他的token和目标的正常位置进行预测。它并不改变序列的内容,只是改变了token之间的相对位置,因此可以解决两阶段的不一致性问题
- Denoising Autoencoder (DAE):借助于DAE的原理,通过对输入序列做一系列的操作来加入“噪声”,然后训练模型去除加入的噪声来恢复原始的输入序列
- contrastive learning(CTL):对照学习假设:一些观察到的文本对在语义上比随机取样的文本更为接近。CTL 背后的原理是「在对比中学习」。相较于LM,CTL 的计算复杂度更低,因而在预训练中是理想的替代训练标准。
常用的CTL有三种:-
Replaced Token Detection,RTD:与 NCE 相同,但前者会根据上下文语境来预测是否替换 token。
-
Next Sentence Prediction,NSP:训练模型以区分两个输入句子是否为训练语料库中的连续片段
-
Sentence Order Predicting,SOP :使用同一文档中的两个连续片段作为正样本,而相同的两个连续片段互换顺序作为负样本。
NSP就是来预测下一个句子的,也就是一个句子是不是另一个句子的下一个句子。这个 任务的问题出在训练数据上面,正例就是用的一个文档里面连续的两句话,但是负例使用的是不同文档里面的两句话。这就导致这个任务包含了主题预测在里面,而主题预测又要比两句话连续性的预测简单太多。新的方法使用了sentence-order prediction(SOP), 正例的构建和NSP是一样的,不过负例则是将两句话反过来
-
预训练模型虽然可以从大规模行语料库中学习到优秀的基于上下文的表示向量,但是它缺乏领域知识。因此,目前一个研究热点就是如何使用现有的语言学、语义学、常识和特定领域的知识来加强预训练。
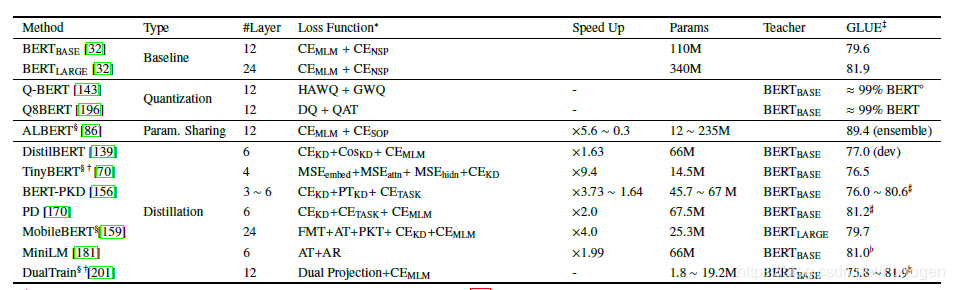
此外,预训练模型参数众多,预训练和推断所需的时间往往较长,因此无法直接将其应用于对于实时性要求较高的场景中。模型压缩的目的就是需要通过减小模型的容量来提高计算效率,同时希望模型的效果不会下降很多。常用的模型压缩方法有:
- 模型剪枝,即删除不重要的参数
- 参数量化,即使用少量的位去表示参数
- 参数共享,即相同类型的层间进行参数共享
- 知识蒸馏,即使用知识蒸馏的方式将老师网络中学到的知识转移到容量较小的学生网络中
文中指出了几种常用的fine-tuning策略,如两阶段的方式、多任务学习以及使用额外的适应模块(extra adaption module)帮助fine-tuning。
最后作者指出了预训练模型几个可能的发展方向:
- PTM的上限在哪?从最初的ELMO、BERT到最近的Turing-NLG等,继续加大语料库的规模和提高语料的质量,堆叠更多的Transformer、以及使用更大的步长进行训练等都可以持续的提升预训练模型在下游任务中的效果。因此,如何在现有的软硬件基础上,设计出更高效的模型结构、自监督预训练任务、优化器和训练技巧等来提升模型性能,最终逼近于可能的上限值得思考
- 如何针对于具体的任务进行预训练模型的构建和模型的压缩?在实践中,不同的目标任务需要 PTM 拥有不同功能。而 PTM 与下游目标任务间的差异通常在于两方面:模型架构与数据分发。尽管较大的 PTM 通常情况下会带来更好的性能表现,但实际问题是如何在一定情况下使用这类较大的 PTM 模型,比如低容量的设备以及低延迟的应用程序。而通常的解决方法是为目标任务设计特定的模型体系架构以及与训练任务,或者直接从现有的 PTM 中提取部分信息用以目标任务。
- 如何设计更优秀的模型架构?现有的预训练模型大多数都使用了Transformer进行特征提取,但是受限于设备,它无法处理超过512个token的输入序列,尽管有类似Transformer-XL等改进版本的出现,但并没有从根本上解决这个问题。因此,能否使用NAS来自动化的搜索更好的模型架构变得十分重要
- 如何让预训练模型更好的在下游任务中发挥作用?Fine-tuning是目前最主要方法,但效率却很低,每个下游任务都有特定的微调参数。而改进的解决方案是修复 PTM 的原始参数,并特定为任务添加小型的微调适配模块,因此可以使用共享的 PTM 服务于多个下游任务
- 如何提升预训练模型的可解释性和可靠性?可解释性是DL中一个极其重要的方向,它对于我们理解模型内部的知识学习过程帮助极大。因此,使用不同的方式来提升PLM的可解释性,可以帮助我们更好的理解模型内部是如何学习知识的,Transformer中的多头注意力机制中的多头分别有什么差异等。另外,深层神经网络模型在对抗性样本中显得十分脆弱,在原输入中加入难以察觉的扰动即可误导模型产生攻击者预先设定好的错误预测。因此,如何提升PTM 对攻击的防御是一个很有前途的方向
