目录
Abstract
使用自然语言prompt和task demonstrations作为额外信息插入到输入文本中很好的利用了GPT-3模型中的知识。于是,本文提出少样本在小模型下的应用。我们的方法包括了基于prompt的微调,同时使用了自动生成的prompt;针对任务demonstration,我们还重新定义了一种动态和有选择地方法将其融入到上下文中。
Introduction
虽然GPT-3只使用提示和任务示例就可以在无需更新权重地情况下表现得很好,但是GPT-3模型很大,无法应用于现实中的场景进行微调。所以本文提出了在BERT等小模型上,仅使用少量的样本去对模型进行微调。作者从GPT-3中得到灵感,使用prompt和in-context同时对输入和输出进行优化,他们使用了暴力搜索去获得一些性能较好的回答词,并且使用T5去生成了提示模板,他们说这种方法很cheap?使用T5单独生成一个模板还cheap?由于输入长度的限制,他们对每个类找出一个好的demonstration。感觉没什么新意啊?GPT-3真就被抄 麻了!!!
Methods

label words
Gao et al. (2021)使用了未进行微调的预训练模型,得到最优的K个候选词,将其作为剪枝后的回答词空间。然后他们在此空间上进一步对模型在训练集上进行微调进行搜索得到n个较好的回答词。最后再根据验证集的结果得到一个最优的回答词。
Prompt template
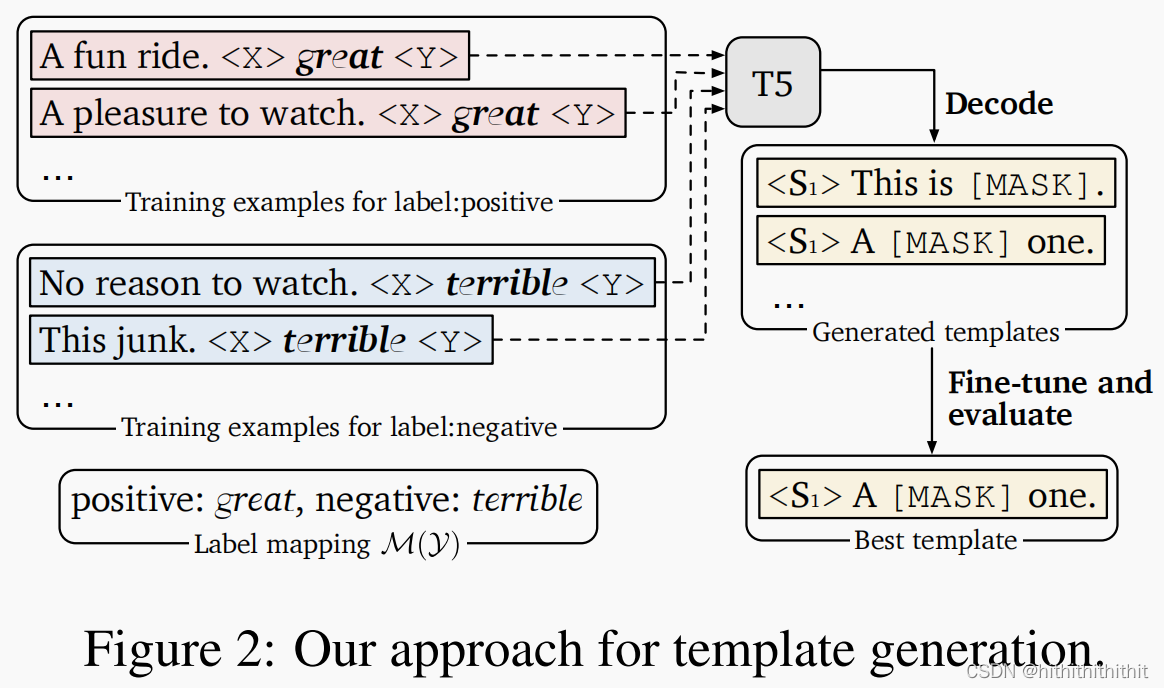
Gao et al. (2021)把prompt模板生成的问题视为一个文本生成的任务,使用T5(Raffel et al, 2020)作为生成器模型。他们将原始输入和输出拼接起来作为T5(Raffel et al, 2020)模型的输入,然后他们使用了束搜索生成多个提示模板,经过在开发集上进行微调得到一个最好性能的提示模板,此外他们还使用了束搜索得到的提示模板用于集成模型的学习。
Demonstrations
不想看了,没意思,就是通过对每个类采样一个示例插入到输入中,参考GPT-3。
Experiments
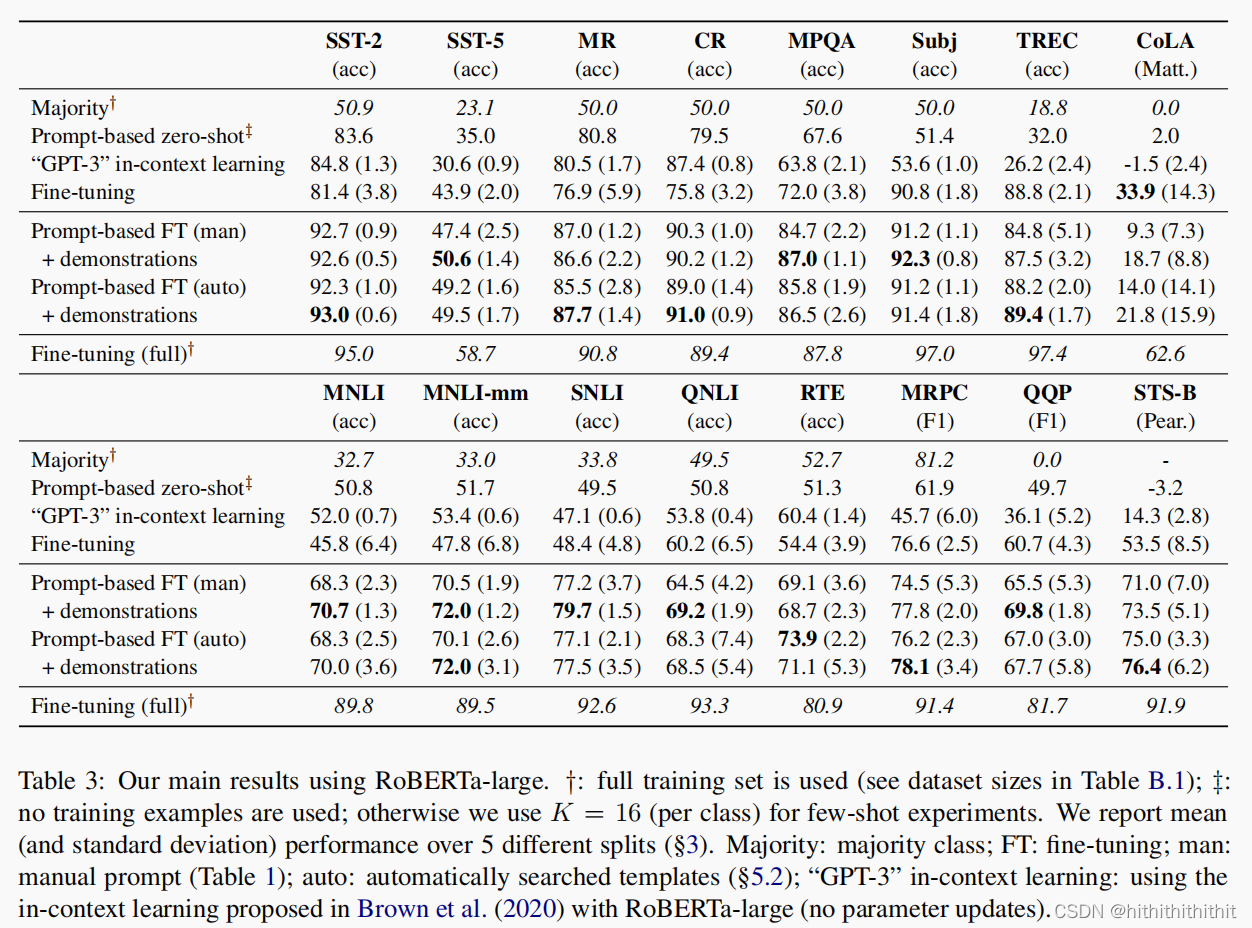
倒是做了不少的实验,也算是还行吧,对这些数据集不太了解,自己看吧