
我是目录!!!
Introduction
本文旨在为Large Language Model (LLM)中的shortcut learning问题给出一个详细的综述。shortcut learning最早是在CV中被提出的 [1](其实2020年也不是很早了),并一直在CV中有很多相应工作,但是在NLP中的研究还不是特别多。shortcut意味“捷径”,正如同字面意思一样,这意味着模型会从一个数据中学习到一个解决问题的捷径,但是实际上模型并没有真正地理解相关任务。以[2]中给出的图片为例进行说明:

对Indian elephant的判断,模型并没有通过学习大象的轮廓特征进行预测,而是通过大象粗糙的表皮、褶皱等特征进行了判断。那么,在©中,一个带有猫咪轮廓的具有大象纹理的图片却还是被视为了大象。因此,模型学习到了大象的皮肤的相关的捷径,并没有真正地认识大象。同样地,在一些NLP地任务中,LLM也会学习到shortcut,这会妨碍LM的Out-of-Distribution (OOD) generalization以及adversarial robustness。比如,在一些NLI任务中,LLM会记住一些任务无关的词汇(‘do’, ‘is’ ‘will not’)并利用这些高频词进行下游推断,尽管这些词没什么卵用。
因此,文本概述了识别LLM中捷径学习行为的方法,描述了捷径学习的原因,介绍了缓解解决方案,确定了主要挑战,并介绍了这一研究路线与其他方向的联系。
一些同义词:shortcut learning也会被叫做其它名字,比如:learning bias, superficial correlations, Clever Hans effect(聪明汉斯Clever Hans是1900年代左右活跃的一头马匹,以懂得计算四则运算著名。后来被人发现汉斯实际上是透过观察发问者的表情而猜出问题的答案,而并非真正进行运算。聪明汉斯的案例是观察者期望效应的一个例子。)
Shortcut Learning Phenomena
What is Shortcut Learning?
模型捕获的特征一般可以分为:useless features, robust features, and non-robust features这三种,其中捷径学习就是学到了非鲁棒的特征:
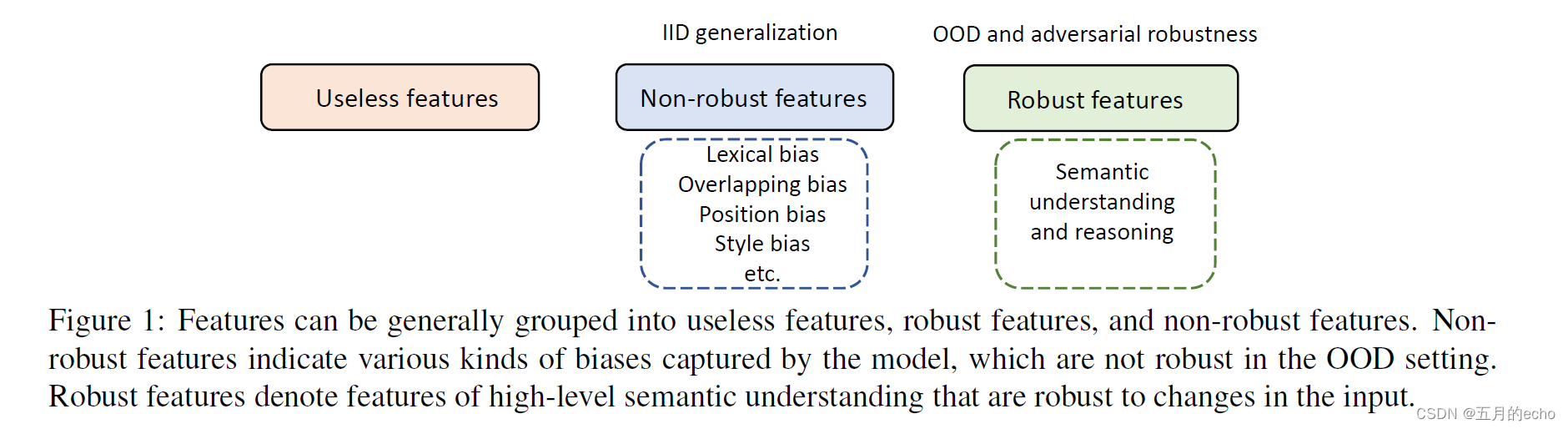
非鲁棒的特征一般包含下述几种:
- Lexical Bias。某些词汇特征与某些类标签具有高度的共现相关性。比如一些否定词会和负面的预测产生联系,比如no,never这种。
- Overlap Bias。比如在QA任务中,问题和答案可能会有重叠,LLM学习到了这种重叠但是并没有真正理解QA。
- Position Bias。这个好理解,比如阅读理解中的答案可能在段首出现的频率比较高。
- Style Bias。独立于语义,可能是一种行文写作的风格。比如非洲裔美国人的一些惯用写作方法与白人美国人的写作方法有所区别。
Generalization and Robustness Challenge
捷径学习可能导致OOD数据的性能大幅下降。因为训练集和测试集通常是identically distributed (IID),因此二者都有捷径可以学;但是当测试集没有了类似的捷径(不再独立同分布),那么学习到了捷径的模型的泛化性就会大幅度下降。这时候,模型学习到的是一些非任务本质性的表层特征,因此也容易受到攻击和欺骗,从而展现出较低的鲁棒性。
Identification of Shortcut Learning
接下来给出一些识别出捷径的方法。
Comprehensive Performance Testing
OOD generalization test旨在在非IID的测试集上进行测试。还可以实现对抗性攻击,以测试LLM的鲁棒性。也可以使用随机消融方法来分析LLM是否利用了这些基本因素来实现有效的语言理解。比如[3]分析了单词的顺序对模型性能的影响,然后发现语序对预训练的语言模型并不重要。这说明模型并没有学习到语序的信息。
Explainability Analysis
现有文献主要采用特征归因(Feature attribution)形式的解释来分析NLU模型中的捷径学习行为[4]。NLU的特征归因比较好做,比如看一个token对最终预测结果的贡献程度(可以用注意力啦或者其他一些衡量指标)。[4]中利用了模型梯度的变化计算相应的指标进行归因,观察到LLM的预测结果依赖于假设句中的数据集偏差,包括虚词、否定词等。
也有工作使用instance attribution,探究一些影响程度高的实例如何影响模型的学习(比如在情感分类中一些具有强烈倾向得分的句子对模型的分类性能影响更大)。
Origins of Shortcut Learning
训练数据集、LLM模型和微调训练过程。
Skewed Training Dataset
训练数据在特征和类标签方面是不平衡的,这种数据会影响模型的特征学习。比如常见的长尾分布,会造成模型对head样本的倾斜,而忽略tail样本。
LLMs Models
有两个关键因素:模型大小(由参数的数量衡量)和预训练时候的目标。比如,BERT和RoBERTa参数数量不一致,一些研究表明较小的模型更容易捕获虚假的模式,更依赖于数据进行预测,而大型模型往往更稳健。包括蒸馏模型,也更容易受到攻击。
Model Fine-tuning Process
标准的训练程序通常倾向于学习简单的特征,这些简单特征就是捷径[5]。另外,模型对容易样本给出了过度自信的预测,对困难样本给出了低置信度的预测。模型倾向于在训练的早期阶段学习非鲁棒的和易于学习的特征[6]。甚至一些工作在理论上证明梯度下降方法倾向于学习非鲁棒网络(离谱啊)[7]。
Mitigation of Shortcut Learning
重点来了,本节讲述如何缓和捷径学习。
Dataset Refinement
最简单的当然是对数据集进行操作,目的是减轻训练数据集中的偏差[8]。比如在众包数据标注的时候,众包工作者将收到额外的指示,不使用一些会带来捷径的词。还可以重新组织训练和测试分割,使测试集中的偏差分布不同于训练集中的偏差分布。反事实数据增强[9]、mixup代表的数据增强似乎也是一个好办法。
Adversarial Training
对抗训练也是CV中缓和捷径的常用方法。NLP中大概有两种对抗方式:(1)任务分类器和对抗分类器共同使用同一个编码器,对抗分类器的目标是为训练数据中的偏差提供正确的预测,然后训练编码器和任务分类器来优化任务目标,同时降低对抗分类器在预测训练数据偏差的性能[10]。这种对抗的思路就是说,在编码器的层面把模型对偏差的依赖消除掉,因为在优化任务目标的时候,对抗分类器是不优化的。(2)以损失函数最大化为目标生成对抗例,以损失函数最小化为目标训练模型;例如,使用基于屏蔽语言模型的生成器扰动文本生成对抗样本。这个很符合对抗训练最大最小的思路[11]。
Explanation Regularization
利用人类建立的先验知识使模型训练规范化。通过用领域专家创建的理论基础注释将特征归因解释规范化来实现的,以强制模型根据正确的原因做出正确的预测。对于NLI任务,使用自然语言解释来监督模型,鼓励模型更多地关注解释中出现的单词[12]。但这个的局限性一眼就看出来了,专家知识没有的内容还是不行。
Product-of-Expert (PoE)
这个思路挺有意思,首先训练bias-only model以捕获数据集的偏差,例如NLI任务的仅假设偏差。然后在第二阶段,利用交叉熵损失训练去偏模型,将其输出与bias-only model的输出相结合:

优化的时候,只有去偏模型参数被反向传播更新。目的是鼓励去偏模型利用正交信息与来自仅偏模型的信息进行预测[13]。
Training Samples Reweighting
重权的主要思想是将更高的训练权重放在难训练的训练样本上,反之亦然。其基本假设是,提高最差组(硬样本)的性能有利于模型的鲁棒性。它通常通过两个阶段的训练来实现。第一阶段训练权重索引模型;在第二阶段,将索引模型的预测值作为权重来调整训练实例的重要性。soft weights[14]或者hard weights[15]都可以被使用,focal loss也可以被用于模型优化。
Confidence Regularization
这个方法鼓励去偏模型对这些有偏差的样本给出较高的不确定性(较低的置信度)。 它是基于这样一种观察:模型倾向于对有偏见的例子做出过度自信的预测[16]。
Partitioning Data into Environments
鼓励模型在多种环境中学习不变量。比如,例如,训练数据被划分为几个非IID的子集,然后鼓励模型学习到的假相关性(捷径)在不同的环境中不同,而可靠的相关性在不同的环境中保持稳定[17]。
Contrastive Learning
对比学习也可以哦,真实不错。目标是构造实例判别任务,指导模型捕获鲁棒和预测特征,同时抑制不需要的非鲁棒特征。实例识别任务要精心设计;否则,有可能抑制健壮的预测特征[18]。
Future Research Directions
More Inductive Bias,Better Pre-training Objectives,Introducing More Domain Knowledge,Analyzing Debiased Models,More Challenging Evaluation Datasets。
总结
挺有意思。
参考文献、帖子
[1] Robert, Geirhos et al. “Shortcut Learning In Deep Neural Networks”, NATURE MACHINE INTELLIGENCE 2.11 (2020): 665-673.
[2] https://zhuanlan.zhihu.com/p/277500980
[3] Sinha, Koustuv et al. “Masked Language Modeling and the Distributional Hypothesis - Order Word Matters Pre-training for Little.”, Empirical Methods in Natural Language Processing (2021): 2888-2913.
[4] Du, Mengnan et al. “Towards Interpreting and Mitigating Shortcut Learning Behavior of NLU models”, NAACL-HLT (2021): 915-929.
[5] Harshay, Shah et al. “The Pitfalls of Simplicity Bias in Neural Networks”, Neural Information Processing Systems 33 (2020): 9573-9585.
[6] Hermann, Katherine L., and Andrew K. Lampinen. “What shapes feature representations? Exploring datasets, architectures, and training”, Neural Information Processing Systems 33 (2020): 9995-10006.
[7] Vardi, Gal et al. “Gradient Methods Provably Converge to Non-Robust Networks”, arXiv preprint arXiv, 2202.04347 (2022)
[8] Wu, Yuxiang et al. “Generating Data to Mitigate Spurious Correlations in Natural Language Inference Datasets”, ACL 2022 Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (2022): 2660–2676.
[9] Kaushik, Divyansh et al. “Learning The Difference That Makes A Difference With Counterfactually-Augmented Data”, ICLR (2020)
[10] Stacey, Joe et al. “Avoiding the Hypothesis-Only Bias in Natural Language Inference via Ensemble Adversarial Training”, Conference on Empirical Methods in Natural Language Processing 2020.emnlp-main (2020): 8281-8291.
[11] Rashid, Ahmad et al. “Mate-Kd: Masked Adversarial Text, A Companion To Knowledge Distillation”, Annual Meeting of the Association for Computational Linguistics 2021.acl-long (2021): 1062-1071.
[12] Stacey, Joe et al. “Supervising Model Attention with Human Explanations for Robust Natural Language Inference.”, National Conference on Artificial Intelligence (2022): 11349-11357.
[13] Sanh, Victor et al. “Learning from others’ mistakes: Avoiding dataset biases without modeling them”, ICLR (2021)
[14] Utama, Prasetya Ajie et al. “Towards Debiasing NLU Models from Unknown Biases”, Conference on Empirical Methods in Natural Language Processing 2020.emnlp-main (2020): 7597-7610.
[15] Liu, Evan et al. “Just Train Twice: Improving Group Robustness Without Training Group Information”, International Conference on Machine Learning 139 (2021): 6781-6792.
[16] Ajie, Utama Prasetya et al. “Mind the Trade-off: Debiasing NLU Models without Degrading the In-distribution Performance”, Annual Meeting of the Association for Computational Linguistics 2020.acl-main (2020): 8717-8729.
[17] Damien, Teney et al. “Unshuffling Data for Improved Generalization”, arXiv preprint arXiv, 2002.11894 (2020)
[18] Robinson, Joshua et al. “Can contrastive learning avoid shortcut solutions?”, Annual Conference on Neural Information Processing Systems 34 (2021): 4974-4986.