一、摘要
研究目的是解决在事件抽取任务中手动标注训练数据的费时费力以及训练数据不足的问题。首先提出了一个事件抽取模型,通过分离有关角色(roles)的参数预测来客服角色重叠的问题。此外,针对训练数据不足的问题,提出了一种通过编辑原型(prototypes)来自动生成标注好的数据,通过对质量进行排序来筛选生成的样本的方法。
二、背景
角色重叠问题(the roles overlap problem):一个论元(arguement)可以在一句话中扮演不同的角色。例如,"The explosion killed the bomber and three shoppers"这句话中,kill是事件attack的触发词,而the bomber既是角色attacker,也是角色victim。
此外,针对现在远程监督的事件抽取存在的问题,将目光转向预训练的语言模型,试图利用它们从大规模语料库中获取的知识来做事件生成。
三、抽取模型
研究将事件抽取看作由两个子任务(触发词抽取、论元抽取)组成,并提出了以预训练语言模型为基础的事件抽取器(PLMEE)。
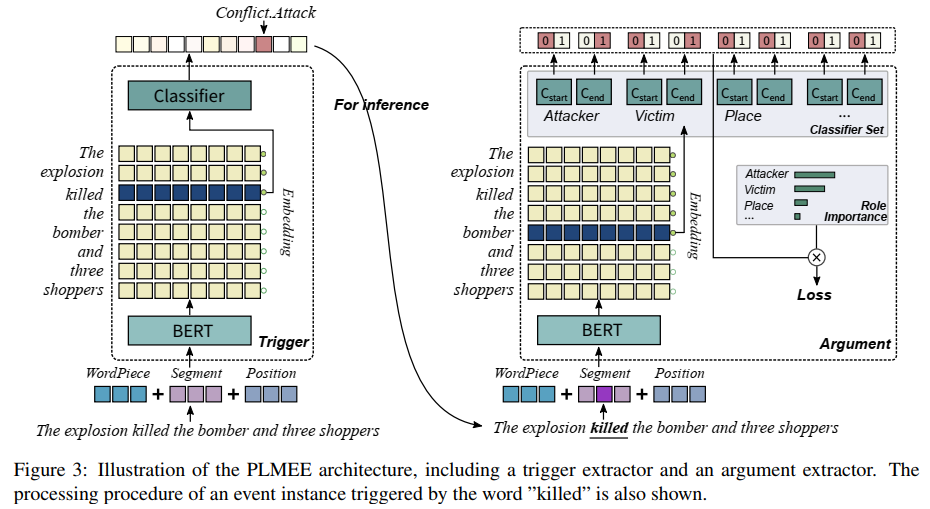
1. 触发词抽取器
用于预测token是不是事件的触发词。将触发词抽取看作一个对token的分类任务,其中label是事件类型。只需要在BERT上添加一个多分类器就可以构建触发词抽取器。
2. 论元抽取器
用于提取相关的论元及其扮演的角色。为了克服大部分论元都是长短语以及角色重叠这两个问题,在BERT上添加了多组二分类器,每组分类器为一类角色服务,确定所有属于它的论元的范围(短语开始到结束)。
3. 论元范围的判定
PLMEE中,一个token t被认定为角色r的论元的开头的概率是:![]()
被认定为结尾的概率是:![]()
其中下标s代表开头,e代表结尾。Wsr是二分类器探测角色为r的论元开始的权重,同理Wer是二分类器探测角色为r的论元结束的权重。B是BERT embedding。
对于每个角色r,根据上述概率,可以得到两个0-1数列Bsr和Ber,代表句子中的token是否是角色为r的论元的开始或结束。最后通过一个有限状态机来判定论元范围。

四、训练数据生成
除了PLMEE之外,还提出了一个基于预训练语言模型的事件生成方法。通过编辑原型,该方法可以生成数量可控的标记样本作为额外的训练语料库。这个方法分为三步:预处理、事件生成和评分。
Adjunct token:除了触发词和论元之外的token,不仅包括单词和数字,还包括标点符号。例如句子"President Bush is going to be meeting with several Arab leaders"中,is和going就是adjunct token。
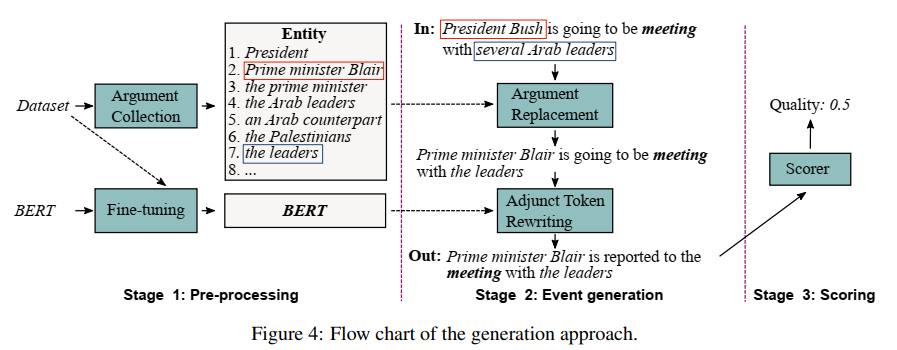
1. 预处理
首先在ACE2005数据集中收集论元以及它们所扮演的角色,但是与其他论元重叠的论元除外,因为这些论元大部分是含有不必要信息的长短语。
采用BERT重写adjunct token,并使用masked language model task (Devlin et al., 2018)对ACE2005数据集进行微调。与BERT的预训练相同,每次抽样一批句子,其中mask掉15%。目的是在无监督的情况下预测正确的token。
2. 事件生成
对一个原型执行两步操作。首先将论元替换为相似的、扮演相同角色的论元。之后用fine-tune的BERT重写adjunct token。操作后就可得到有标注的新句子。
论元替换
采用相似度作为替换的标准。使用embedding之间的余弦相似度来作为相似度,embed方法采用ELMO。一个论元有80%的概率被替换,20%的概率不变。
Adjunct token重写
重写是将一些adjunct token替换为更符合上下文语境的token,具体例子可参照上图。
3. 评分
该阶段是为了量化每个样本的质量,从中选出有价值的。评分的标准是困惑度(perplexity)和与原数据集的距离。前者反映生成的合理性,后者反应数据间的差异。
困惑度(PPL)
取adjunct token被重写的平均概率作为生成的句子S'的困惑度:![]()
其中A是S'中被重写的adjunct toekn集合。
距离(DIS)
采用BERT进行embed,计算句子的余弦相似度:![]()
最后定义质量函数:![]() ,其中λ是平衡参数。质量函数用于选择高质量的样本。
,其中λ是平衡参数。质量函数用于选择高质量的样本。
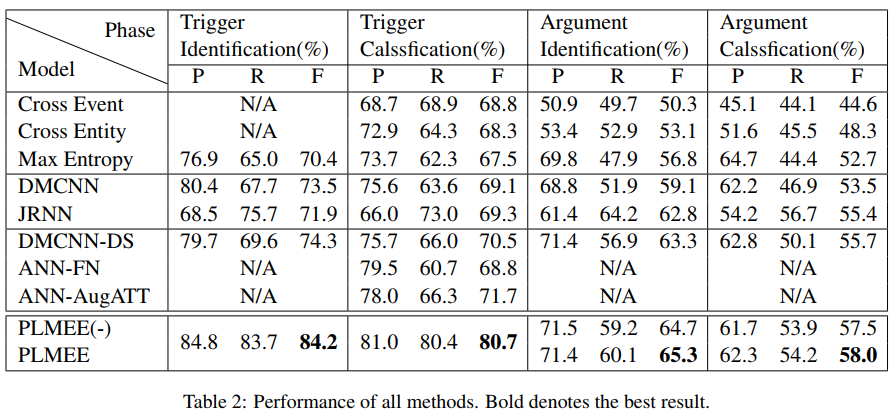
五、实验结果
六、不足之处
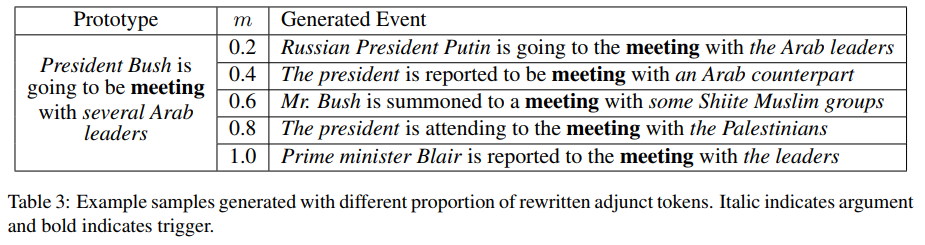
对于一些论元,重写会导致其意义发生很大变化。
