文章目录
相关信息
论文年份:2020年04月
论文地址:https://arxiv.org/pdf/2004.13922.pdf
论文代码(官方):https://github.com/ymcui/MacBERT
论文模型(Hugging Face): hfl/chinese-macbert-base ; hfl/chinese-macbert-large
论文阅读前提:熟悉BERT模型及其前置知识
一句话概括一下本文的内容:作者对原有的BERT的MLM任务进行了魔改,不使用[MASK]作为掩码,而是使用相似的字进行掩码,然后发现Performance提升了,起个新名字MacBERT。
摘要(Abstract)
作者提出了一个中文Bert,起名为MacBert。
该模型采用的mask策略(作者提出的)是 MLM as correction (Mac)
作者用MacBert在8个NLP任务上进行了测试,大部分都能达到SOTA
1. 介绍(Introduction)
作者的贡献:提出了新的MacBert模型,其缓和了pre-training阶段和fine-tuning阶段的gap。采用的方式是“mask字时,采用相似的字进行mask”
2. 相关工作(Related Work)
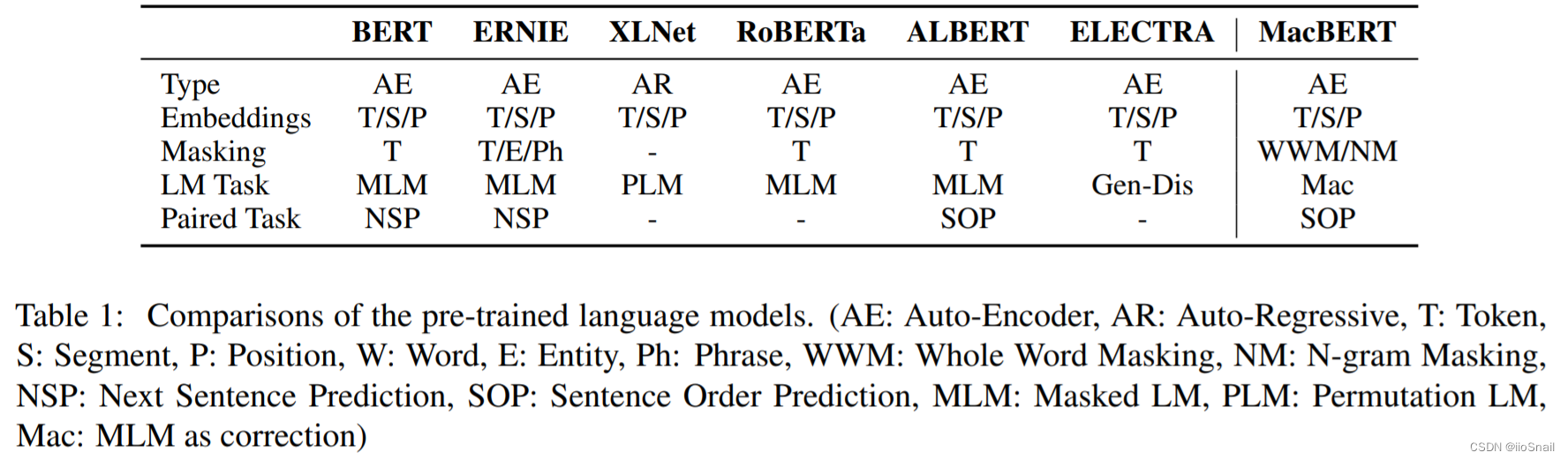
这个表总结的不错。其他略
3. 中文预训练模型(Chinese Pre-trained Language Models)
3.1 BERT-wwm & RoBERTa-wwm
略(也是相关工作)
3.2 MacBERT
MacBERT的训练使用了两个任务,MLM和SOP(sentence-order prediciton)
对于MLM任务,与BERT类似,但做了如下修改:
- 作者使用N-gram的方式来选择要mask的token,按照40%,30%,20,10%的比例进行1-gram到4-gram的mask
- 相对于BERT中使用
[MASK]来替换token,作者使用的方式是使用相似的字来进行替换。相似字使用的是Synonyms toolkit - 对于要进行mask的token,15%使用
[mask]替换,80%使用相似字,10%使用随机字,剩下10%使用原始字。
在原文中,作者使用的是word,其实我也不太清楚他说的word是一个字还是一个词。一般中文的BERT模型都是按字来处理的,所以我这里也认为是word指代的是一个字。
对于SOP任务,其负样本就是将两个连续的句子交换顺序。
4. 实验设置(Experiment Setups)
4.1 Setups for Pre-Trained Language Models
数据集:①中文维基百科,0.4B个字;② 新百科全书(encyclopedia news)+问答网站,5.4B个字
分词工具:LTP(Language Technology Platform) , 4.2k star, 基于深度学习,包括:分词、词性标注、句法分析等
训练方式:①对于BaseModel,基于Chinese BERT-base继续训练;②对于LargeModel,从0开始训练。
其他设置:
- 句子最大长度: 512
- Weight Decay Optimizer:Adam
- Optimizer: Lamb
- 对MacBERT-large:2M steps, 512 batch_size, 1e-4 learning rate
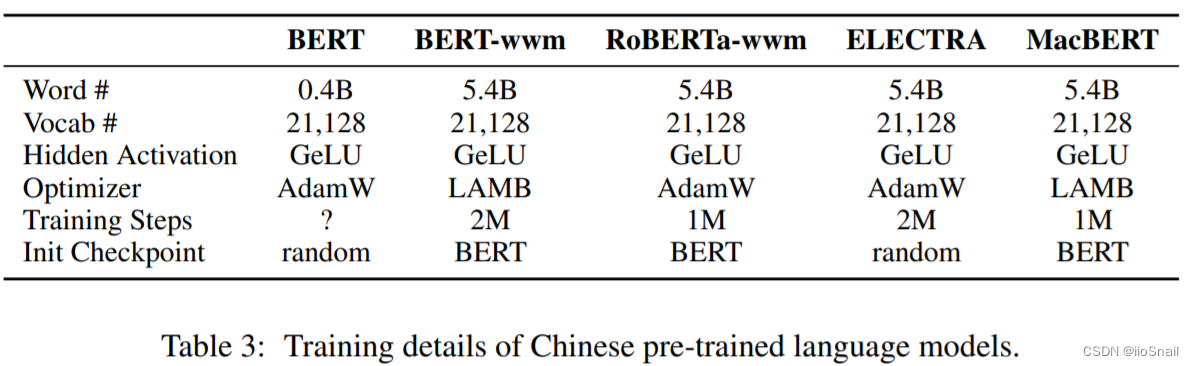
训练细节汇总如下表:
4.2 Setups for Fine-tuning Tasks
本节是关于下游任务的设置,略。
5. 结果(Results)
本章展示了在各个下游任务的实验结果。这里我简单列个表:
| 任务 | Level | MacBERT结果 |
|---|---|---|
| Machine Reading Comprehension | document-level | 最强 |
| Single Sentence Classification | sentence-level | 一般,与其他差异不大 |
| Sentence Pair Classification | sentence-level | 稍好,平均来讲,比其他模型稍微好一丢丢 |
6. 讨论(Discussion)
作者做了消融实验,得出了以下结论:
- MacBERT对Performance的提升主要是因为N-gram mask和相似词替换(Similar word replacement)这两个机制
- SOP(Sentence-order Prediciton)任务虽然对Performance也有提升,但微乎其微。
7. 结论(Conclusion)
略