并查集 & 拓扑排序 - 547. 朋友圈
班上有
N名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A 是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C 的朋友。所谓的朋友圈,是指所有朋友的集合。给定一个
N * N的矩阵M,表示班级中学生之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。示例 1:
输入: [[1,1,0], [1,1,0], [0,0,1]] 输出: 2 说明:已知学生0和学生1互为朋友,他们在一个朋友圈。 第2个学生自己在一个朋友圈。所以返回2。示例 2:
输入: [[1,1,0], [1,1,1], [0,1,1]] 输出: 1 说明:已知学生0和学生1互为朋友,学生1和学生2互为朋友,所以学生0和学生2也是朋友,所以他们三个在一个朋友圈,返回1。注意:
N 在[1,200]的范围内。
对于所有学生,有M[i][i] = 1。
如果有M[i][j] = 1,则有M[j][i] = 1。
一. 知识要点
连通分量
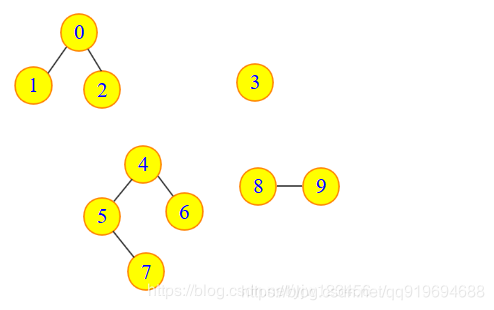
- 定义:不连通的图是由2个或者2个以上的连通子图组成的。这些不相交的连通子图称为图的连通分量。比如下图中有四个连通分量
拓扑排序方式
-
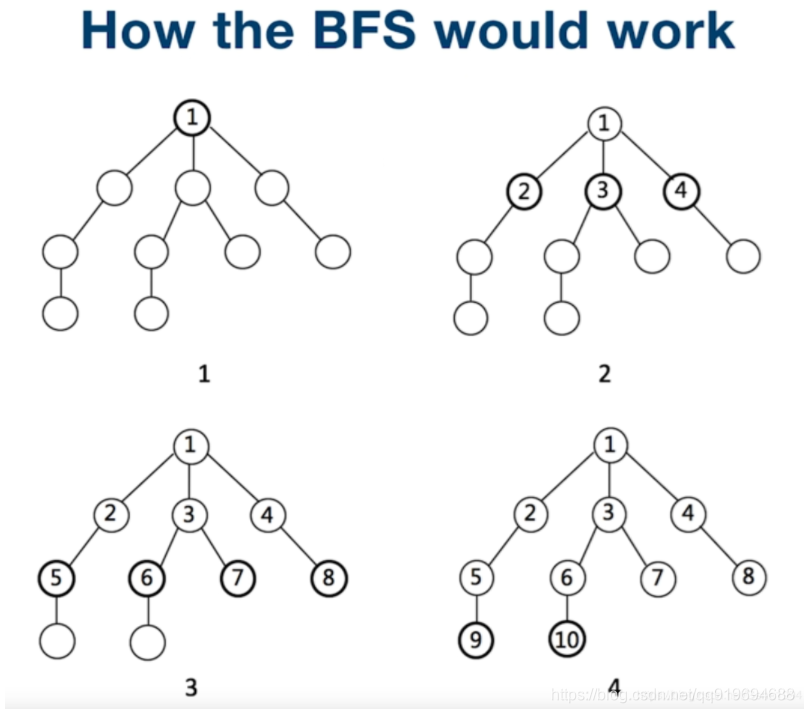
BFS - 广度优先搜索
-
DFS - 深度优先搜索
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lAIeZzGq-1574245242449)(en-resource://database/6736:1)]](https://img-blog.csdnimg.cn/20191120182238245.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxOTE5Njk0Njg4,size_16,color_FFFFFF,t_70)
并查集
- 定义:就是有“合并集合”和“查找集合中的元素”两种操作的关于数据结构的一种算法。 容易理解的解释:江湖中的并查集
- 作用:
- 网络连接判断
- 间接好友关系判断
- api设计:
union(p,q);: 合并p、q两点使他们两个连通.find(p);: 找到节点q的连通性,(处在什么状态合谁联通)isConnected(p,q);: 通过find的api,我们可以找到两个节点是否会连通的,即api
- 实现方式
- 快速查找:Quick-Find
- 快速合并:Quick-Union
- 加权快速合并:Weighted Quick-Union
- 路径压缩:Weighted Quick-Union With Path Compression
- 时间复杂度比较
| 方式 | union复杂度 | find复杂度 |
|---|---|---|
| Quick-Find | O(n) | O(1) |
| Quick-Union | 树的高度 | 树的高度 |
| Weighted Quick-Union | O(lgn) | O(lgn |
| Weighted Quick-Union With Path Compression | O(1) | O(1) |
二.实现思路
本题有两种实现方式
- 通过
拓扑排序的DFS方式 判断图中连通分量的数量- 通过
并查集判断图中连通分量的数量
DFS(深度优先遍历)
- 初始化
- 被访问数组
visited:默认每个节点都为0 - 连通分量个数
count:默认为0 - 循环从每个
没被访问过的节点进行dfs- 如果被访问过,则将这个节点的visited变为1
- 每次dfs。count++
- 被访问数组
并查集:
- 初始化(默认每个节点和其他节点都没有连线)
- 连通分量个数
count:分量数目为节点数目 - 节点父节点数组
parent:所有父节点默认是自己 - 所在树的树深度数组
rank:所有树深度为1
- 连通分量个数
- 循环判断节点是否是邻接节点(是否有临边)
- 如果是邻接节点就调用
union方法,并将节点传入方法- 查找(找父亲,换父亲,本质上更新
parent数组):- 第一次:如果父节点不是当前节点,则做路径压缩。把当前节点指向
爷爷节点 - 然后从当前节点向上循环。直到到根节点停止,并将父节点返回
- 第一次:如果父节点不是当前节点,则做路径压缩。把当前节点指向
- 合并(将父亲不同的树拼到一起):
- 如果两个节点的父节点不同,则将短的树直接合并到长的树上
- 每次合并之后,把
连通分量减一
- 查找(找父亲,换父亲,本质上更新
- 如果是邻接节点就调用
三.代码实现
DFS
public class Solution {
public void dfs(int[][] M, int[] visited, int i) {
for (int j = 0; j < M.length; j++) {
if (M[i][j] == 1 && visited[j] == 0) {
visited[j] = 1;
dfs(M, visited, j);
}
}
}
public int findCircleNum(int[][] M) {
int[] visited = new int[M.length];
int count = 0;
for (int i = 0; i < M.length; i++) {
if (visited[i] == 0) {
dfs(M, visited, i);
count++;
}
}
return count;
}
}
并查集
class UnionFind {
/**
* 连通分量的个数
*/
private int count;
private int[] parent;
/**
* 以索引为 i 的元素为根结点的树的深度(最深的那个深度)
*/
private int[] rank;
public UnionFind(int n) {
this.count = n;
this.parent = new int[n];
this.rank = new int[n];
for (int i = 0; i < n; i++) {
this.parent[i] = i;
// 初始化时,所有的元素只包含它自己,只有一个元素,所以 rank[i] = 1
this.rank[i] = 1;
}
}
public int getCount() {
return this.count;
}
public int find(int p) {
// 在 find 的时候执行路径压缩
//第一种:部分压缩,速度快但是压缩不彻底
while (p != this.parent[p]) {
// 两步一跳完成路径压缩
this.parent[p] = this.parent[this.parent[p]];
p = this.parent[p];
}
//第二种:全部压缩,速度稍慢但是压缩彻底,每个元素直接指向根节点
//if (p!=this.parent[p])
// this.parent[p]=find(this.parent[p]);
//return this.parent[p];
return p;
}
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
public void union(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot) {
return;
}
// 元素rank少的,合并到元素多的
if (rank[pRoot] > rank[qRoot]) {
parent[qRoot] = pRoot;
} else if (rank[pRoot] < rank[qRoot]) {
parent[pRoot] = qRoot;
} else {
parent[qRoot] = pRoot;
rank[pRoot]++;
}
// 每次 union 以后,连通分量减 1
count--;
}
}
public class Solution {
public int findCircleNum(int[][] M) {
int len = M.length;
UnionFind uf = new UnionFind(len);
for (int i = 0; i < len; i++) {
for (int j = 0; j < i; j++) {
if (M[i][j] == 1) {
uf.union(i, j);
}
}
}
return uf.getCount();
}
public static void main(String[] args) {
int[][] M = {{1, 1, 0},
{1, 1, 0},
{0, 0, 1}};
Solution solution = new Solution();
int res = solution.findCircleNum(M);
System.out.println(res);
}
}
附:四种并查集实现方式(转)
- 快速查找:Quick-Find
/**
* 简单的数组并查集
* 通过数组来维护区域是否连通,相同区域id的数据连通
* find时间复杂度为O(1)
* Union时间复杂度为O(n)
* @author xuexiaolei
* @version 2017年12月13日
*/
public class UFS01 {
//用一个数组来表示节点的连通性,有相同id内容的节点是连通的
private int[] mIds;
//节点个数
private int mcount;
/**
* 初始化状态,并设置每个节点互不连通
* @param capcity
*/
public UFS01(int capcity){
mIds = new int[capcity];
mcount = capcity;
for (int i = 0; i < capcity; i++) {
mIds[i] = i;//各自节点的id都不一样
}
}
/**
* 返回当前节点的连通id
* @param p
* @return
*/
public int find(int p){
if (p<0 || p>=mcount){
throw new RuntimeException("越界喽");
}
return mIds[p];
}
/**
* 判断a,b节点是否连通
* @param a
* @param b
* @return
*/
public boolean isConnect(int a, int b){
return find(a)==find(b);
}
/**
* 连通a,b节点
* 联合的整体思路:
* 要么把a索引在mIds中的状态变成b的,
* 要么把b索引在mIds中的状态变成a的
* @param a
* @param b
*/
public void union(int a, int b){
int aId = find(a);
int bId = find(b);
//如果已经连通,就不管了
if (aId == bId){
return;
}
//将bId的全部变成aId,需要将每个节点的id都变过来的
for (int i = 0; i < mIds.length; i++) {
if (mIds[i] == bId){
mIds[i] = aId;
}
}
}
}
- 快速合并:Quick-Union
/**
* 类似树的并查集
* 通过指向父节点的指针来维护区域是否连通
* 时间复杂度不定,如果组成了线性的树,时间复杂度偏高。
*
* 可以改进的方向:维护每个节点的下面层数 或者 子节点 个数,union的时候,将个数少的节点连接到个数多的节点上面
* @author xuexiaolei
* @version 2017年12月13日
*/
public class UFS02 {
/**
* 维护指向父节点的指针
*/
private int[] mParents;
private int mCount;
/**
* 初始化数组,默认每个节点都是区域头节点,即指针指向自己
* @param capacity
*/
public UFS02(int capacity){
mCount = capacity;
mParents = new int[capacity];
for (int i = 0; i < capacity; i++) {
mParents[i] = i;
}
}
/**
* 查找P节点的区域头结点
* @param p
* @return
*/
public int find(int p){
if (p<0 || p>=mCount){
throw new RuntimeException("越界喽");
}
/**
* 向上查找,直到是一个区域头结点
*/
while (p != mParents[p]){
p = mParents[p];
}
return p;
}
public boolean isConnect(int a, int b){
return find(a)==find(b);
}
/**
* 联合,将a,b节点的区域头结点联合即可
* @param a
* @param b
*/
public void union(int a, int b){
int aRoot = find(a);
int bRoot = find(b);
if (aRoot == bRoot){
return;
}
mParents[bRoot] = aRoot;
}
}
- 加权快速合并:Weighted Quick-Union
/**
* 可以改进的方向:维护每个节点的子节点 个数,union的时候,将个数少的节点连接到个数多的节点上面
* @author xuexiaolei
* @version 2017年12月13日
*/
public class UFS04 {
private int[] mParents;
//新加一个数组用来记录每一个节点,以它为根的元素的个数。
//mSize[i]表示以i为根的树结构中的元素个数。
private int[] mSize;
private int mCount;
public UFS04(int capacity){
mCount = capacity;
mParents = new int[mCount];
mSize = new int[mCount];
for (int i = 0; i < mCount; i++) {
mParents[i] = i;
//默认每个都是1:独立的时候含有一个元素.
mSize[i] = 1;
}
}
//以下find和isConnected都用不到mSize.
public int find(int p){
if( p<0 || p>=mCount){
//...做一些异常处理
}
while(p!=mParents[p]){
p = mParents[p];
}
return p;
}
public boolean isConnected(int p,int q){
return find(p)==find(q);
}
//联合的时候就需要用到mSize了.看看那个节点为根的树形集合中元素多,
//然后把少的那个节点对应的根,指向多的那个节点对应的根。
public void union(int p,int q){
//前两步不变
int pRoot= find(p);
int qRoot = find(q);
if(pRoot == qRoot){
return;
}
int pSize = mSize[pRoot];//初始事都是根,为1
int qSize = mSize[qRoot];
//如果pRoot为根的树形集合含有的元素比qRoot的多
if(pSize > qSize){
//注意是少的索引的父节点指向多的
mParents[qRoot] = pRoot;
//注意此时mSize的改变,由于qRoot归并到了pRoot当中那么
//需要加上相应数量的size,注意qRoot对应的size并没有改变
mSize[pRoot] = pSize+qSize;
}/*else if(pSize < qSize){//同理
mParents[pRoot] = qRoot;
mSize[qRoot] = pSize+qSize;
}else{//如果两个相等那么就无所谓了,谁先合并到谁都可以.
mParents[qRoot] = pRoot;
mSize[pRoot] = pSize+qSize;
}*/
//然后就可以把等于的合入到大于或者小于的里面.
else{//此处把小于和等于合到一块
mParents[pRoot] = qRoot;
mSize[qRoot] = pSize+qSize;
}
}
}
- 路径压缩:Weighted Quick-Union With Path Compression
/**
* 可以改进的方向:维护每个节点的下面层数,union的时候,将个数少的节点连接到个数多的节点上面
* @author xuexiaolei
* @version 2017年12月13日
*/
public class UFS05 {
private int[] mParents;
//mRank[i]表示以i为根节点的集合所表示的树的层数
private int[] mRank;
private int mCount;
public UFS05(int capacity){
mCount = capacity;
mParents = new int[mCount];
mRank = new int[mCount];
for (int i = 0; i < mCount; i++) {
mParents[i] = i;
//默认每个都是1:表示深度为1层
mRank[i] = 1;
}
}
//以下find和isConnected都用不到mRank.
public int find(int p){
if( p<0 || p>=mCount){
//...做一些异常处理
}
while(p!=mParents[p]){
p = mParents[p];
}
return p;
}
public boolean isConnected(int p,int q){
return find(p)==find(q);
}
//找到p、q节点所在的树形集合的根节点,它的深度。然后把深度小的根节点合入到深度大的根节点当中
public void union(int p,int q){
//前两步不变
int pRoot= find(p);
int qRoot = find(q);
if(pRoot == qRoot){
return;
}
int pRank = mRank[pRoot];//初始事都是深度为1
int qRank= mRank[qRoot];
//如果p的深度比q的深度大.
if(pRank > qRank){
//注意是小的指向大的,也就是为小的重新读之
mParents[qRoot] = pRoot;
//此时把并不需要维护pRank,因为qRank是比pRank小的
//也就是q更浅,它不会增加p的深度,只会增加去p的宽度
}else if(pRank < qRank){
mParents[pRoot] = qRoot;
//同样的道理不需要维护qRank,p只会增加它的宽度
}else{
//当两个深度相同的时候,谁指向谁都可以,但是注意此时的深度维护
//被指向的那个的深度需要加1.
//此时让qRoot指向pRoot吧.
mParents[qRoot] = pRoot;
mRank[pRoot]++;
}
}
}
测试用例图