很难将物体与其他物体分别开:
- 分割(segmentation)
- 光线(lighting)
- 形变(deformation)
- 功能可见性(affordances)
- 观察点(viewpoint):维度跳跃(dimension-hopping):由于观察点变化,信息从一个维度跳跃到了另一个维度。
_______________________________________________________________________________________
视角变化解决办法
- 使用冗余的不变特征(use redundant invariant features)
- 在物体上放一个盒子来正则化像素点(normalized pixels)
- 使用重复特征,将他们池化,叫做卷积神经网(replicated features with pooling, called 'convolutional neural nets')
- 使用层次结构,清晰地展示了照相机或视网膜的各个部分的位置。(use a hierarchy of parts that have explicit poses relative to the camera)
不变特征:提取一个很大且冗余的特征集,并且在平移或者缩放或者旋转中不变。
需要大量特征,因为有了冗余的特征,一个特征才会告诉你另外两个特征如何相互关联。
在物体识别中,避免从不同物理提取特征。

放盒子:通过一些形状的知识来标记盒子的方向,进而识别物体。

测试的时候需要尝试所有不同角度和大小的盒子。

_____________________________________________________________________________________________
卷积神经网络在手写数字识别中的应用
Yann LeCun 1980s几个应用很好的神经网络之一。
卷积神经网络起源于重复特征的思想。如果一个特征检测器在图像的某个位置起作用,有很大可能这个特征检测器能够在其他位置派上用场。
所以在不同的位置采用相同的特征检测器。用很多特征,得到很多特征图(feature maps),图像的每块都能够表示为很多不同特征的集合。
在不同比例和方向上复制特征,会更困难复杂;
在不同位置复制特征大大减少了需要学习的自由参数的数量。

卷积神经网络与反向传播并不冲突:可以用反向传播来进行训练

重复特征达到的效果:同变性(Equivariant activities)
- 在神经元激活层面达到的是同变性
- 在权重方面达到的是不变性
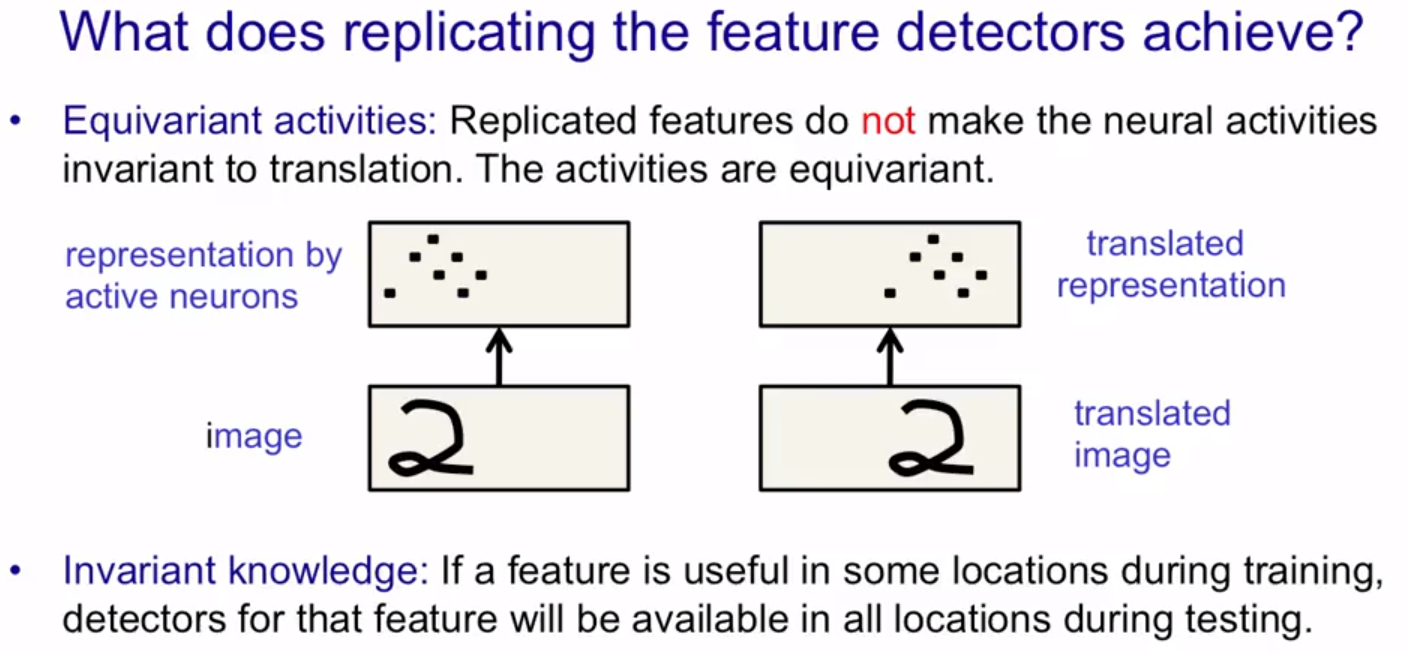
如果想要在神经元活动层面上达到不变性,则对重复特征进行池化(pooling)
池化:对输入的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征。
但是池化操作丢失了图片中物体的精确位置信息。


子采样:池化操作
S2:把C1中的重复特征合并到一起
如果在机器学习问题中加入先验知识
通过设计网络结构:
局部连接
对权重进行约束
选择合适的激活函数
还可以使用先验知识来合成数据。
在LeNet中加入合成数据,使错误率变小。

如何估计错误率:检测特定的错误

在第一个表格中,模型2要比模型1好。
__________________________________________________________________________________________________
识别彩色图像中的物体,比识别手写字体难很多。
- 物体种类多
- 很多像素(256*256 color vs 28*28 gray)
- 需要对3D图片进行处理,会丢失很多信息
- 需要分割不同杂乱的场景
- 每张图片中不同的物体
在识别手写字体中表现的很好的神经网络在识别彩色图片也会表现很好吗?

李飞飞创造了ImageNet数据集和比赛,推荐李飞飞的计算机视觉课程。
AlexKrizhevsky的神经网络:16%的错误率


GPU很擅长处理矩阵乘法,30倍速度

