会议:INTERSPEECH 2019
论文:Modulation Vectors as Robust Feature Representation for ASR in Domain Mismatched Conditions
作者:Samik Sadhu, Hynek Hermansky
Abstract
在这项工作中,我们在自动语音识别(ASR)系统中的训练和测试条件之间的域不匹配中,证明了调制矢量的鲁棒性。 我们的工作专注于处理混响引起的不匹配的特定任务。 我们使用TIMIT的模拟数据和REVERB挑战数据的真实混响语音来评估系统的性能。 本文还描述了一种多流系统,该系统将梅尔频率倒谱系数(MFCC)和M向量的信息组合在一起,以提高匹配和不匹配数据集中的ASR性能。 拟议的多流系统在不匹配条件下实现了25%的识别准确度的相对提高,而经过M向量训练的混合ASR系统显示了7-8%的识别准确度的改进,两者均达到了w.r.t. MFCC训练的混合ASR系统。
6、Conclusions
在这项工作中,我们展示了M向量对于ASR中域不匹配(尤其是混响中的不匹配)的有用性。 我们展示了我们可以将FDLP模型阶数降低为0.5秒窗口的非常低的p = 10值,以在与TIMIT数据库进行模拟混响不匹配时获得WER相对提高12%。 对于p = 30的中等较低模型阶,我们还可以在真实混响数据上获得7-8%的WER改善。 我们还表明,简单的多流系统可以对匹配和不匹配条件产生显着改善,单通道REVERB数据集的WER相对提高25%。
1、Introduction
所有机器学习系统均在隐式假设下工作,该隐含假设用于测试系统的数据来自与训练数据相似的分布。但是,在实际情况中并不总是满足这样的假设。在这项工作中,我们解决了语音信号中常见的混响中环境不匹配的问题。除了常见的变异性来源(例如性别,年龄和说话者的情绪等)以外,不同的环境条件还带来了其他挑战,需要从语音中提取核心不变信息。几乎不可能表征所有可能成为目标语音数据来源的不同环境域。结果,自动语音识别(ASR)系统会受到多种噪声源(麦克风失真,汽车噪声,家用电子设备的噪声等)和混响的影响。为了处理极为未知的数据域并提高ASR的鲁棒性,ASR文献中提出了多种方法。其中一些方法包括数据增强和多条件训练[1、2、3],模型自适应[3、4、5、6、7],鲁棒的声学建模[8、9],语音增强[10, 11],多流ASR [12、13],提供附加的噪声信息或“噪声感知” ASR [14、15]以及鲁棒的声学特征表示[16、17]。在这项工作中,我们研究了Mvector作为ASR声学特征表示的健壮性,以处理实际ASR系统混响中的失配。我们通过分析涉及Sec的所有参数的含义来描述计算M向量的步骤,第二部分,基线特征在第三节中描述。 在第四节中描述实验设置。 实验结果第五节。
2、Computing Modulations in Speech
M矢量作为一种特征表示被引入到多流混合或端到端ASR系统中,以获得更好的识别性能。这些表示遵循一种新的方法来捕获语音信号能量w.r.t.时间在长时间上下文中的不同频带中的调制。相比之下,MFCC在不同的子带上捕获帧级光谱能量。各子带能量的时间演化由带通语音信号的Hilbert包络表示。使用基于子带的调制作为特征的灵感来自于之前对这些调制组件对语音的人和机器识别的影响所进行的实验[19]。这些特征表示在0-15hz范围内语音信号不同子带Hilbert包络的自回归(AR)近似调制。
2.1. Approximation to Hilbert envelope by FDLP
Hilbert包络由Athineset 等人[20]介绍的频域线性预测(FDLP)技术估算的。该技术建立在一个定理的基础上,该定理表明,将线性预测(LP)应用于偶数对称信号的离散余弦变换(DCT)可以得到信号Hilbert包络的自回归模型。
2.2. Subband based feature extraction
由于DCT系数有效地表示了信号的频域,我们创建了三角形的类MFCC的melscaled滤波器组来在特定的子带上加权DCT系数。这些加权DCT系数用于该特定子带Hilbert包络的AR建模。
2.3. Recursive cepstral computation
调制系数作为近似Hilbert包络对数的幅度谱得到。我们使用递归算法来计算这些系数,这类似于从LP系数有效计算全极点模型的倒谱的算法[21]。
2.4. Frame-wise feature extraction
ASR系统通常使用约100hz的帧频。为了以100hz的帧速率导出M矢量,我们执行以下操作
- 汉宁窗-在考虑的帧周围相对较大的窗长T秒的语音信号
- 计算加窗信号的2型DCT
- 用适当的三角K个mel加权函数对DCT进行窗口化处理
- 导出K个子带中每个子带中模型阶数为p的FDLP模型,并对滤波器系数进行递归计算,得到调制系数
- 将所有K个子带的调制系数串接在适当的频率范围内[fbeg,fend]Hz
2.5. Understanding M-vectors
2.5.1. What do the parameters mean?
窗口长度T代表用于计算调制的时间上下文。 FDLP模型允许我们在较大的时间上下文中计算调制,以形成单个特征向量,从而替代在较长的上下文中拼接短时间特征向量的标准做法。 为了强调在这种大环境中的调制,我们用T秒长的Hanning窗口对语音信号进行窗口化,该窗口在边缘处衰减为零。 窗口长度T也决定了调制系数的分辨率,由下式给出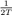 HZ,因此,对于T = 0.5秒的窗口长度,前15个系数对应于0-15 Hz的调制(参考文献[18]中的推测会错误地暗示0-8 Hz)。
HZ,因此,对于T = 0.5秒的窗口长度,前15个系数对应于0-15 Hz的调制(参考文献[18]中的推测会错误地暗示0-8 Hz)。
FDLP模型阶数p代表希尔伯特信封的近似水平。 较高的模型阶数会在封套中保留更多细节,而降低模型阶数会导致更平滑的近似。
频率范围[fbeg,fend]是由先前的研究得出的,结论是4 Hz左右的调制对于语音识别最为重要[19]。 大约2 Hz的慢速调制还会携带有关Hanning窗口的信息。 窗效应导致向特征添加等于汉宁窗倒谱的常数矢量(见图2)。 但是,我们在将特征用于ASR之前执行倒谱均值减法,这消除了特征的这种恒定加窗效应。
2.5.2. Motivation for using M-vectors in domain mismatch
FDLP技术利用AR模型的幂函数来获得不同程度的Hilbert包络逼近,将p作为一个重要的设计参数,以忽略语音信号中环境干扰对Hilbert包络的破坏。忽略对人类语音认知不重要的调制成分,也可以最小化环境干扰对特征表示的影响。这些特性激励我们检验这些特性的健壮性。
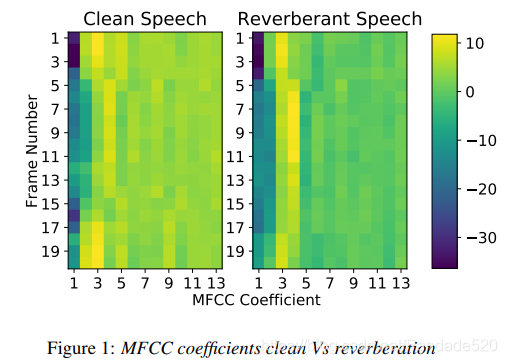
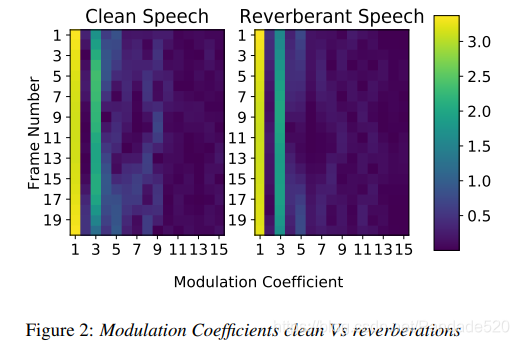
图1和2显示了模拟的大房间混响对MFCC和调制系数(来自特定子带)的影响。 在视觉上,回响语音的调制系数似乎保留了干净语音捕获的相似调制,而这两个条件的MFCC功能看起来却有所不同。 图2中两个域之间MFCC特征的Frobenius范数的相对变化百分比。 1为65.8%,而图2中的调制系数值相同。 2仅为14.08%。
2.5.3. Suitable parameters for mismatched conditions
较低的模型阶数(在我们的实验中为15到30个极点)应该会导致希尔伯特信封的平滑近似,这将忽略希尔伯特信封中的域级别细节。 在5.1.1节中,我们用HMM-GMM ASR模型支持该假设。 但是,对于较低的模型阶数,在匹配条件下ASR性能会下降。 在先前对语音调制的研究中[22],已经表明,在混响条件下,当计算整个发声中的DC时,DC或零频率分量是有害的,因此建议使用FDLP模型的“增益归一化”。 但是,对于T = 0.5秒的窗口,我们观察到DC分量的加入会以很小的幅度提高识别精度(请参阅第5.1.2节)。

3. Baseline MFCC Features
为了比较M向量的鲁棒性,我们使用了如下计算的传统MFCC功能:
- 使用20 ms长度的汉明窗对时域信号进行窗口化
- 计算信号的功率谱
- 根据信号的采样频率,计算20个重叠的三角形梅尔缩放滤波器中的频谱能量的对数
- 计算20个梅尔库能量的DCT并保留前13个系数
4. Experimental Setup
我们展示了在HMM-GMM系统,混合HMM-DNN系统以及多流系统上M矢量的鲁棒性,所有这些都使用Kaldi [23] ASR工具包进行了训练。
4.1. HMM-GMM
我们遵循标准的Kaldi配方,以获得具有上下文相关(三音)状态的LDA-MLLT和SAT HMM-GMM模型。我们使用LDA-MLLT模型中的比对来训练混合系统。对于MFCC特征,我们使用了±4个特征帧的拼接,但是,对于M向量,我们不执行特征的拼接操作。对于这两个功能,我们都使用在Kaldi中实现的标准倒谱均值减法。
4.2. Hybrid HMM-DNN System
我们在实验中使用了两种不同的混合系统:标准的Kaldi nnet2 TANH网络和最近引入的带有LFMMI训练的时域神经网络(TDNN)模型[24]。混合模型的比对来自LDA-MLLT系统。 TANH网络使用5个隐藏层进行训练,每个隐藏层包含512个隐藏单元。我们使用与[24]中所述相同的TDNN体系结构。但是,对于M向量,第一TDNN层的拼接更改为零,而200维多流特征的拼接更改为±1(请参见第4.3节)。训练TDNN时没有速度扰动的数据增强,i矢量和高分辨率功能,这些功能默认包含在标准Kaldi配方中。我们还在MMI训练中使用了10%的交叉熵正则化。
4.3. Multistream System
我们使用一个非常简单的多流系统[25,12,13],没有任何流选择算法。通过主成分分析(PCA),将训练数据的每个流中TANH混合模型中的softmax前后状态减少到100维,并连接起来形成200维特征,用于第二阶段混合ASR训练。
我们同时使用nnet2 TANH网络和TDNN来训练我们的第二阶段混合模型。 我们还在第二阶段的ASR训练中进行倒谱均值归一化,而TANH系统没有特征拼接。 但是,我们发现TDNN模型的±1特征拼接效果最好。
4.4. M-vector Configuration
我们使用窗口长度T = 0.5秒,并针对TIMIT数据库的匹配和不匹配任务尝试模型顺序。 但是,对于REVERB数据,模型阶数固定为p =30。对于0.5秒的窗口长度,我们还使用15个调制系数,并针对较高和较低的窗口长度相应地更改它,以表示相同的调制频率范围。 对于MFCC和M矢量功能,子带的数量固定为K = 20。
5. Results
5.1. Experiments on TIMIT
我们在干净的TIMIT训练集中以所有3696言语训练LDA-MLLT和SAT HMM-GMM模型。通过将TIMIT核心测试集中的192个发声与来自REVERB挑战的较大房间混响脉冲响应(混响时间≈700 ms)进行卷积,生成了模拟混响测试集[26]。我们将其称为“不匹配”集,并将原始192个匹配的测试话语保持为“干净”集。由于对于像TIMIT这样的小型数据集,混合系统没有显示任何明显的改进,因此我们在Kaldi工具包的两个标准HMM-GMM系统上显示了结果。
5.1.1. Effect of model order
表1显示了模型顺序的变化如何导致不匹配测试集和干净测试集的性能之间的折衷。结果表明,随着模型顺序的减少,不匹配集的识别准确度将提高,而干净案例的性能将逐渐变差。对于不匹配的条件,M向量可以将WER从MFCC的70.1%提高到LDA-MLLT系统的61.6%,但是在匹配条件的损失下WER从24.5%增加到36.7%。对于SAT系统也可以观察到类似的趋势。这促使我们着眼于多流体系结构,以融合来自MFCC和M矢量功能的信息,如第4.3节中所述。我们将在5.2节中使用REVERB质询数据为实验研究这种多流系统。
5.1.2. Effects of gain coefficient
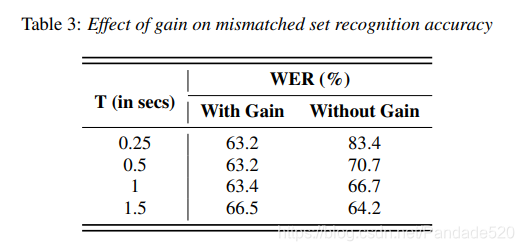
据文献报道,增益捕获了语音中的线性失真,将其从特征表示中移除是有益的,特别是在混响条件下[27,28]。 对于其他类似的研究,通常是在整个发音范围内计算增益[22,29]。 在表3中,我们显示了带有或不带有DC系数的LDA-MLLT系统对于不同窗口长度T的识别精度。 可以看出,随着窗口长度从0.25秒增加到1.5秒,增益对性能的影响减小,从而证实了较早的研究。 但是,由于对于大多数实验而言,我们选择的最佳窗口长度为0.5秒,因此我们选择保留增益系数。
5.2. Experiments on REVERB
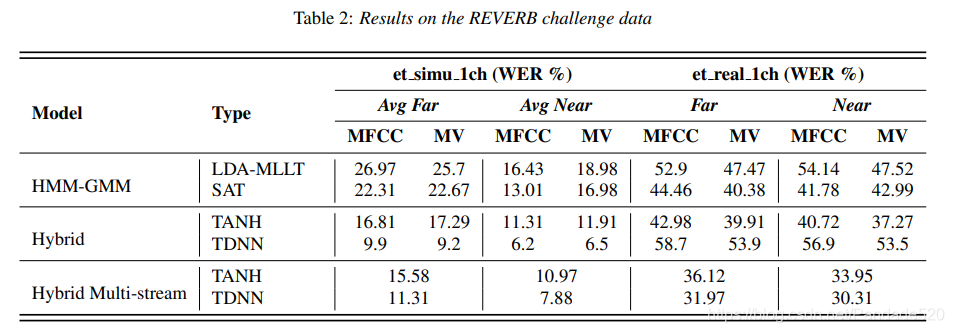
我们使用来自REVERB挑战[26]的单通道数据测试我们的功能,该挑战创建了一个特别有趣且实用的不匹配条件,使用模拟混响语音训练ASR和使用真实混响语音进行测试。通过将语音信号与六种不同类型的混响条件进行卷积来生成模拟数据,混响条件包括三种房间大小和两种类型的麦克风距离(近≈50 cm和远≈200 cm),此外还添加了少量噪声。在Kaldi命名约定中,我们使用单通道模拟数据集trsimu1ch训练ASR模型,并分别在etreal1ch和etsimu1ch的单通道真实和模拟混响语音上测试系统。真实的测试数据是在同一个麦克风的两个不同距离的单个房间中,在两个真实的混响场景中收集的。表2中的结果按近场和远场麦克风场景分为性能。对于模拟集etsimu1ch,我们显示了所有三种房间大小的近和远麦克风的平均性能。
5.2.1. Observations
与MFCC特征相比,M向量特征的低模型阶数导致匹配的测试集etsimu1ch的性能明显变差。但是,对于使用TANH Hybrid模型的近房间和远房间场景而言,不匹配的测试集etreal1ch的WER相对增益为7-8%。多流混合系统可以有效地从MFCC流和M向量流中看到后代,这对于匹配和不匹配的条件都可以提供更好的识别精度。与具有MFCC功能的TANH Hybrid系统相比,多流TDNN系统的WER从40.72%提高到30.31%的WER相对提高了25%,这种不匹配条件的结果尤为明显。
5.2.2. Behaviour of TDNN
在单个流上训练的TDNN模型似乎对MFCC和M矢量特征在模拟数据域上具有严重的过拟合。如表2所示,这导致两个域之间的性能差异很大。它表明,以原始特征进行歧视性训练且没有大量数据的神经网络不能很好地推广到各个域。但是,多流系统中第二阶段的TDNN具有“更好地表现”的后验特征,在各个域中的表现都更加合理,实际上,它获得了我们实验中记录的最佳性能。
