文章目录
无监督的流程及作用(迁移下游任务)
图1:点云上无监督表示学习的一般流程:深度神经网络首先通过在某些代理任务(pre-text tasks)上的无监督学习,用未注记的点云进行预训练。然后,学习到的无监督点云表示被迁移到各种下游任务中,以提供网络初始化,通过这些网络初始化,可以使用少量带注释的特定于任务的点云数据对预先训练的网络模型进行有效微调。
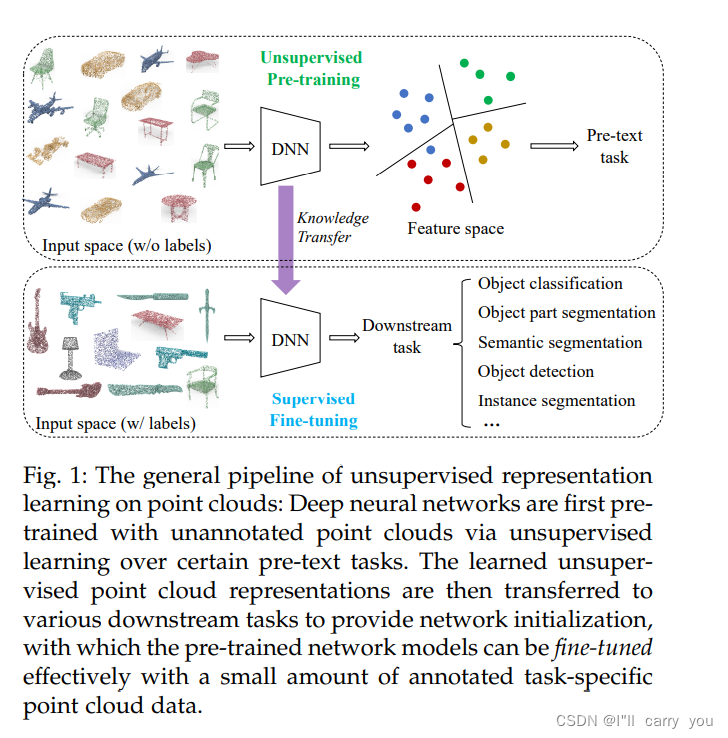
用于点云表示学习的现有无监督方法的分类
图2:用于点云表示学习的现有无监督方法的分类
点云任务描述
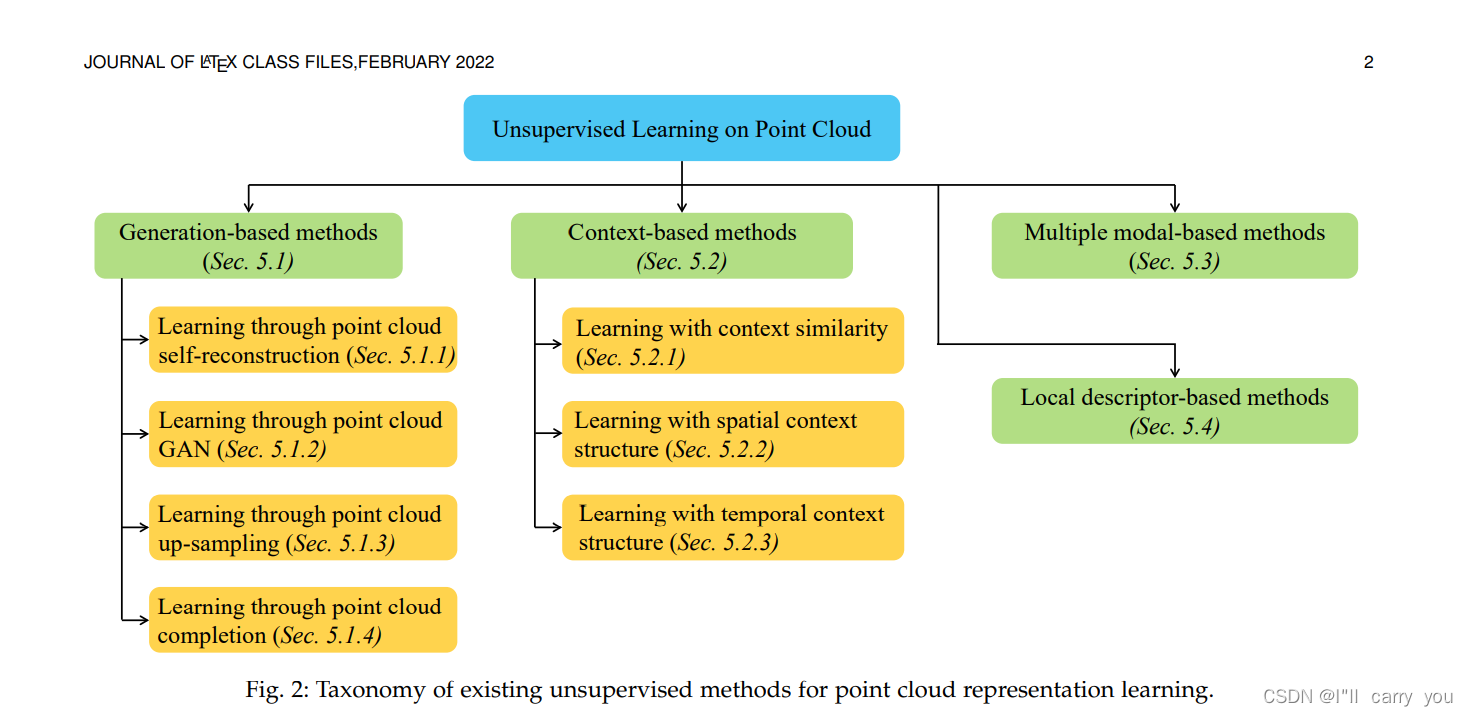
图3:object part segmentation(一个物体的不同部分)
图3:object part segmentation的图示。左列:对象示例,包括ShapeNet零件数据集[16]中的飞机和桌子;右栏:真实标签,不同颜色代表不同部分
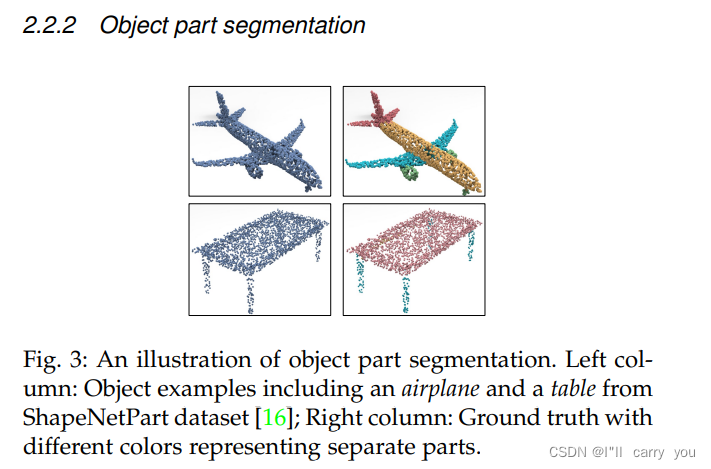
图4:3D object detection
图4:点云对象检测中3D边界框(3D object detection)的图示:这两个图形分别从[20]和[21]中裁剪。
图5:3D semantic segmentation(相同的标签归为一类)
图5:语义点云分割(3D semantic segmentation)示意图:对于左侧显示的S3DIS[23]中的点云样本,右侧的图表显示了相应的真实标签,不同类别用不同的颜色突出显示。

图6: 3D instance segmentation(相同标签但不同个体也要分类)

数据集
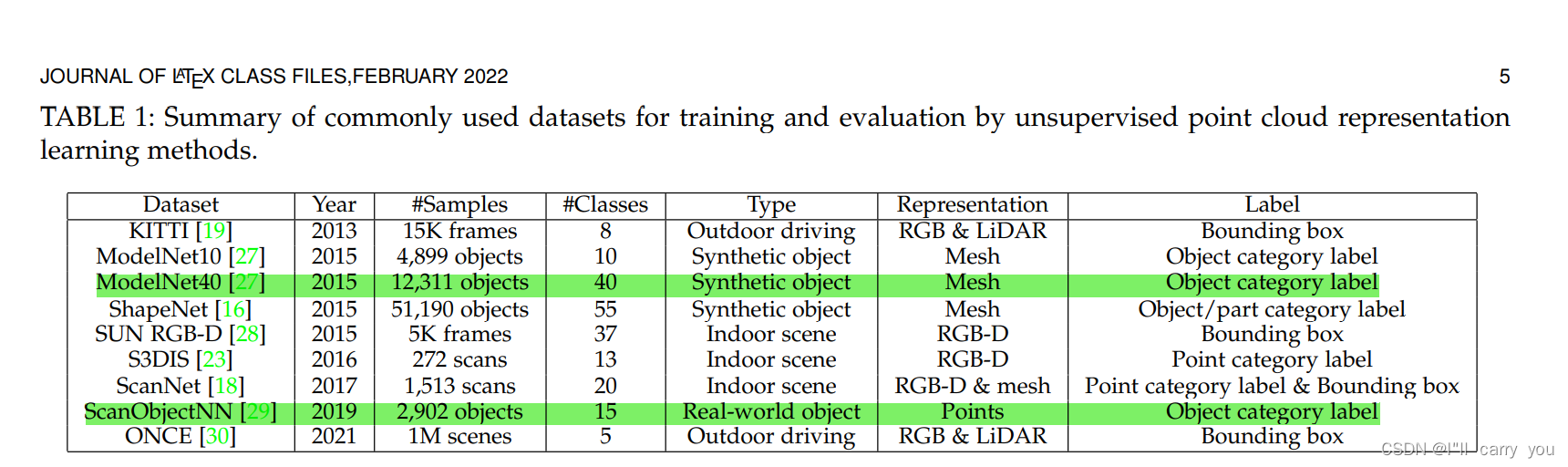
表1:通过无监督点云表示学习方法进行训练和评估的常用数据集汇总。
5 无监督点云表示学习
5.1 Generation-based methods
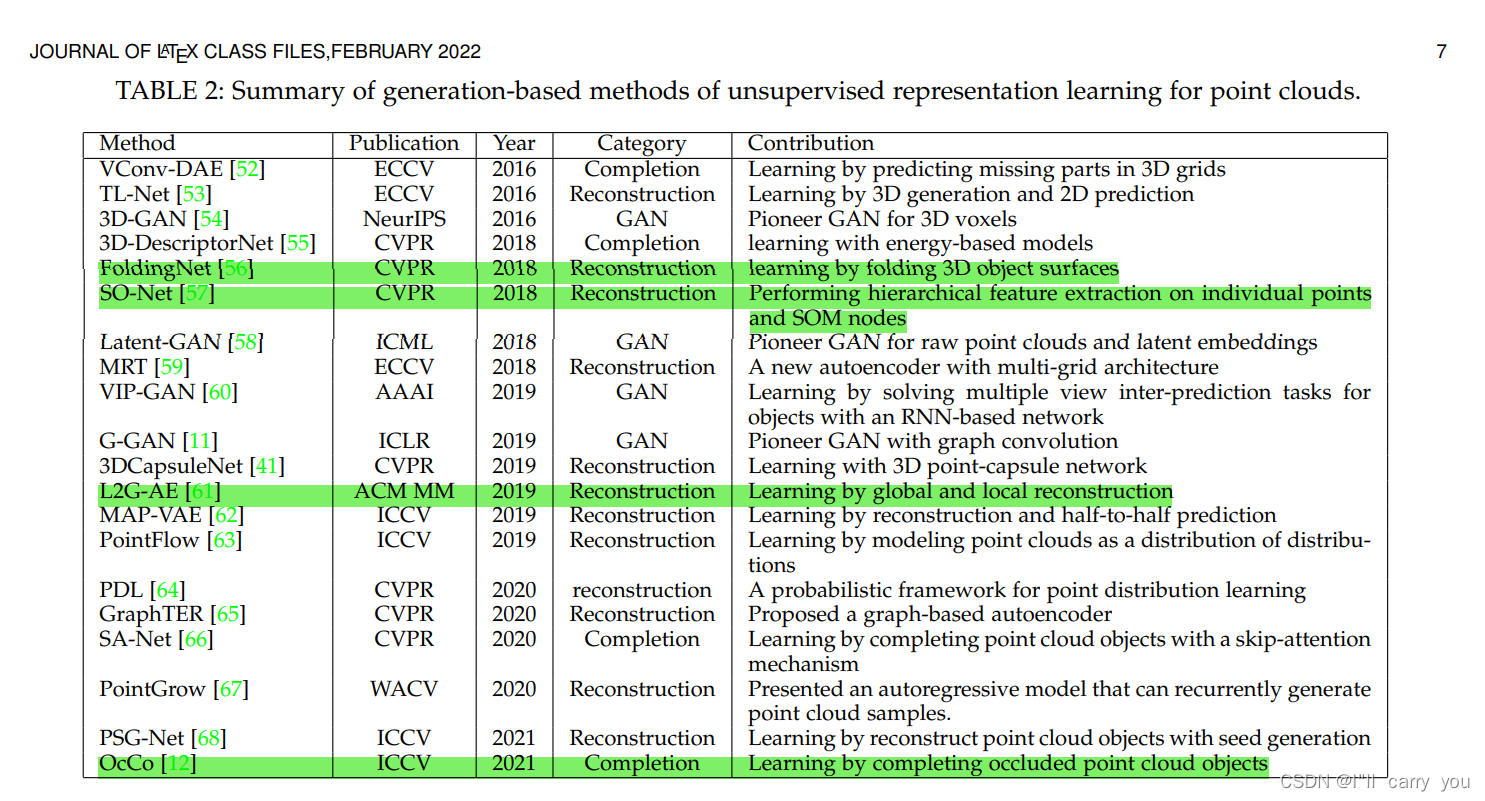
基于生成的无监督点云表示学习方法涉及生成点云对象的过程,根据代理任务(pre-text tasks),可以进一步归纳为四个子类,包括点云自重构(生成与输入相同的点云对象)、点云GAN(生成假点云对象),点云向上采样(生成形状类似但比输入密度更大的点云)和点云完成(预测部分点云对象的缺失部分)。训练这些方法的基本原理是点云本身,它不需要人工注释,可以被视为无监督学习方法。表2中列出了基于生成的方法。
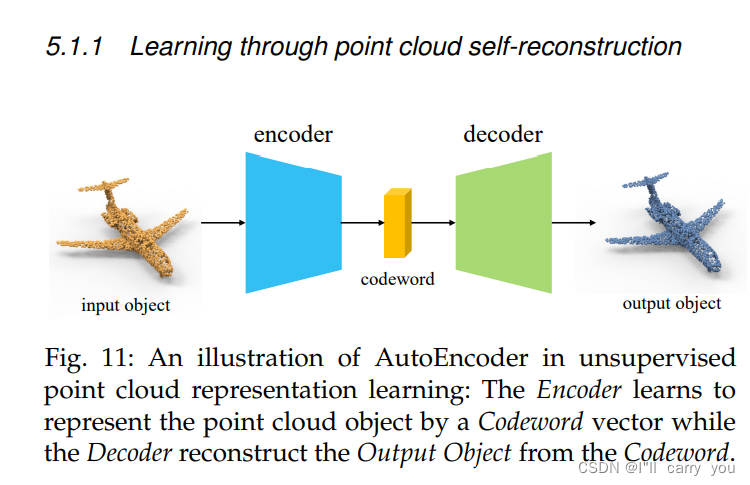
5.1.1 Learning through point cloud self-reconstruction
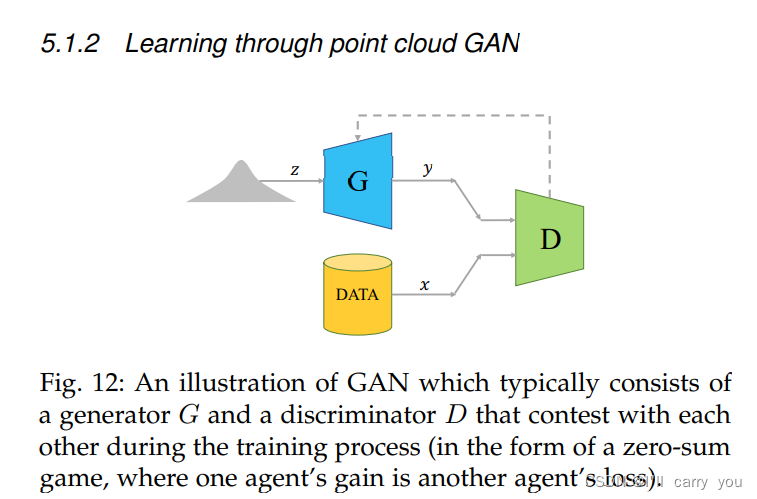
5.1.2 Learning through point cloud GAN
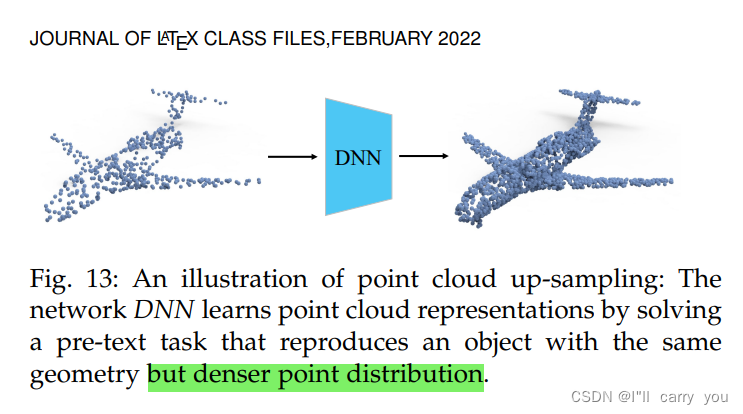
5.1.3 Learning through point cloud up-sampling
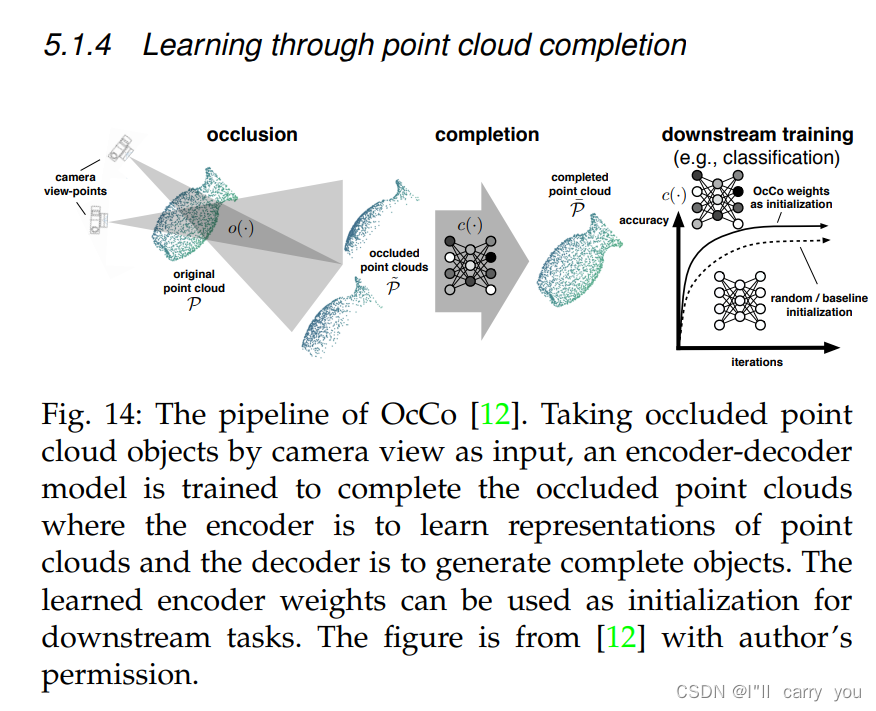
5.1.4 Learning through point cloud completion
5.1.5 Discussion
基于生成任务的点云无监督学习是一个历史悠久的主要研究方向。现有的方法主要集中在从对象级(object-level)点云学习,而很少有研究场景级(scene-level)数据,这限制了无监督学习的应用。相反,基于生成的无监督学习方法在NLP[6]、[32]和2D vision[10]中都取得了巨大成功。为此,我们认为这方面有很大的潜力。
5.2 Context-based methods
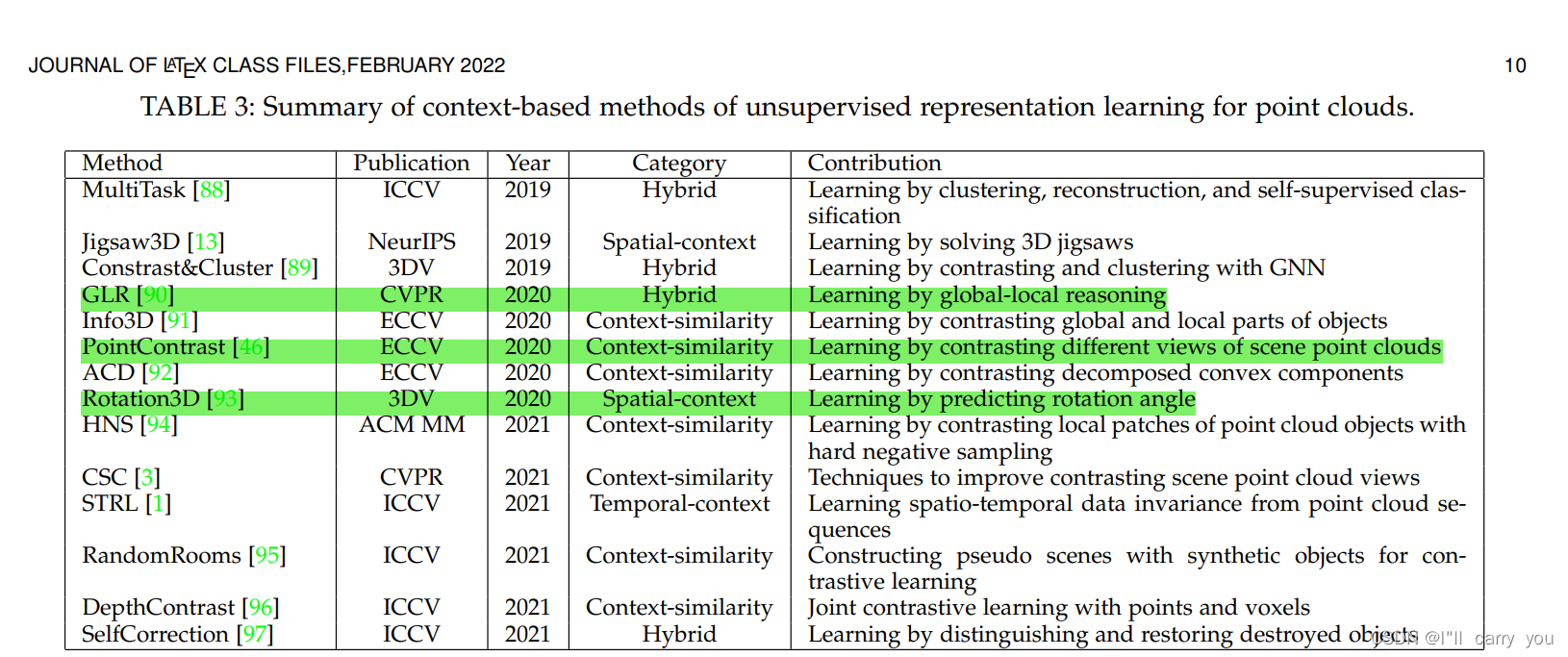
另一类无监督点云学习方法是基于上下文的方法。与通过生成点云进行学习的基于生成的方法不同,这些方法使用区分性的代理任务(discriminative pre-text tasks )来学习点云的不同上下文,包括上下文相似性、空间上下文结构和时间上下文结构(including context similarity, spatial context structures and temporal context structures.)。表3总结了一系列方法。
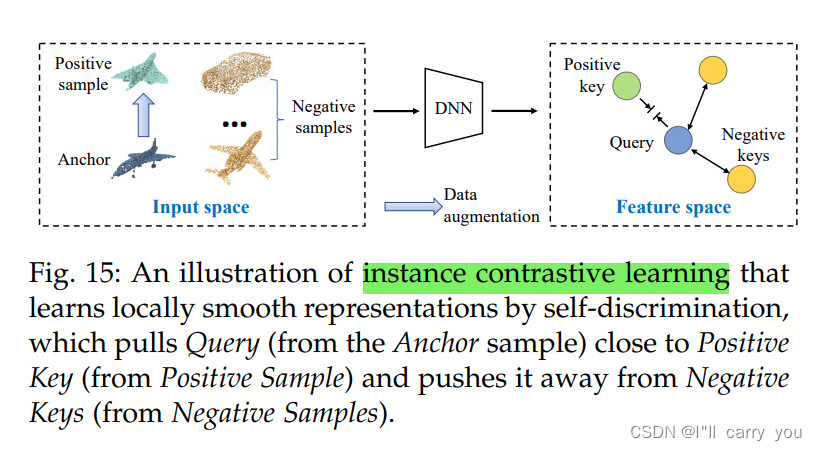
5.2.1 Learning with context similarity
图15:实例对比学习的一个例子,它通过自识别学习局部平滑表示,将查询(来自锚样本)拉到接近正关键点(来自正样本)的位置,并将其推离负关键点(来自负样本)。
5.2.3 Learning with temporal context structure
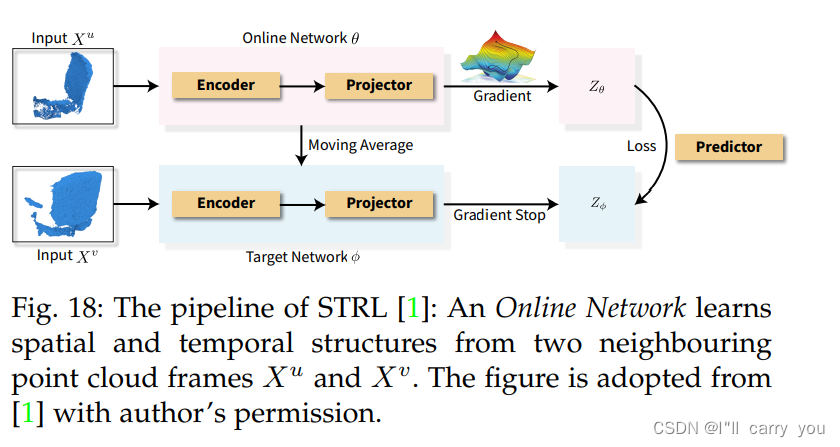
5.2.4 Discussion
上下文学习是无监督点云表示学习的一个新兴方向,近年来受到了越来越多的关注。
虽然大多数点云的URL(Unsupervised Representation Learning)方法都是为对象级表示学习而设计的,但最近几项基于上下文的工作[1]、[46]、[49]、[96]已经成功证明,通过提高不同场景级任务的性能,学习到的表示特征可以跨域泛化(generalize across domains)。
这些发现启发了对点云上URL的研究,并鼓励更多关于3D深度表征学习的无监督代理任务设计的研究
5.3 Multiple modal-based methods
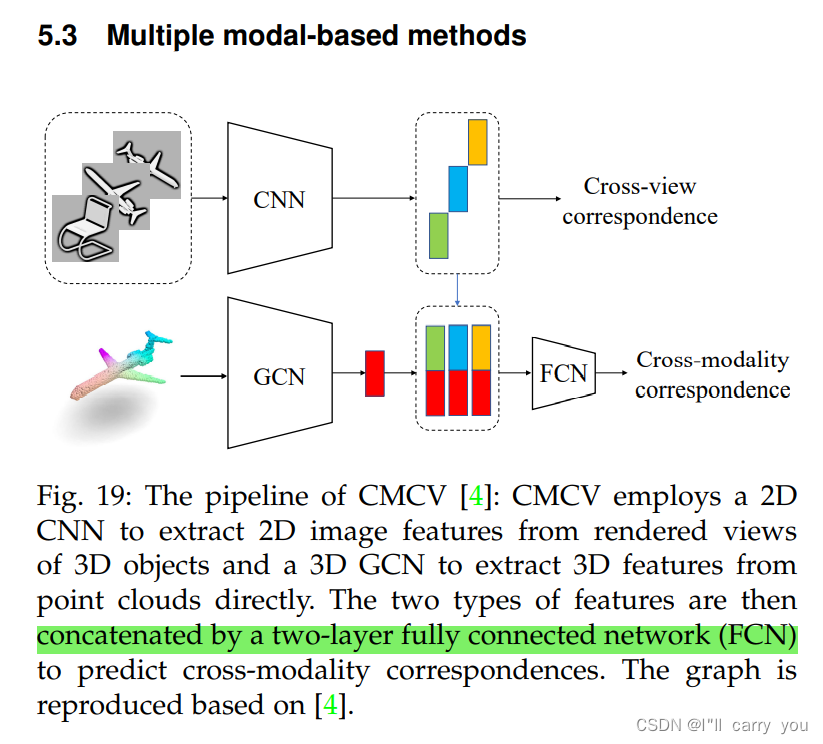
5.4 Local descriptor-based methods
上述介绍的方法旨在学习点云的语义结构(semantic structures),以便进行高层理解(high-level understanding),而基于局部描述符的方法(local descriptor-based methods)则侧重于从点云中学习底层信息(low-level information):
7 future direction(未来研究方向)
- Unified 3D backbones are needed:
- Larger datasets are needed:
- Learning features from multi-modal data:
- Learning spatio-temporal features:
- Learning features from synthetic data:



8 CONCLUSION(结论)
