写在前文:懒编是准备参加数学建模,并且负责编程部分(matlab)。因为时间有限,所以目前个人的看法就是以编程学习(因为是小白)为主,模型学习为辅(这里的辅是知道这个模型怎么用,它的代码怎么写)。当然,大家如果有兴趣深入研究数学模型,那也是没问题的。(极力赞同)
今天是来介绍一种确定几个指标各自所占的权重的方法——熵权法。
昨天的模糊综合分析里有提到用熵权法确定了每个指标各自的权重,这里来详细写写过程。
之前的博客有介绍过一种方法是优劣解距离法(Topsis模型),熵权法是基于这个模型来延伸的。
熵权法…用白话讲,就是根据已知评价对象 指标的数值来确定每个指标所占的权重。(这里要注意,必须要有数值才可以用熵权法,如果没有数值是不可以用这种方法的)
熵权法的应用场景…简单的讲,就是在评价对象时,往往每个对象会有几个指标。那这几个指标哪个指标所占的权重最大呢?(当然可以自己去捏造一个,但是这样子好像主观性有点强。)
如果你觉得自己捏造有点拿捏不准的感觉,那不妨来耐心读读这里的熵权法的使用。
这里主要是介绍,当拿到几个指标的数值(一个矩阵)时,如何用MATLAB确定它的权重。
把昨天模糊综合评价中的数据拿过来。(如果你不知道这数据是指啥,请翻看我上一篇博客《数学建模评价类模型——模糊综合分析法》)
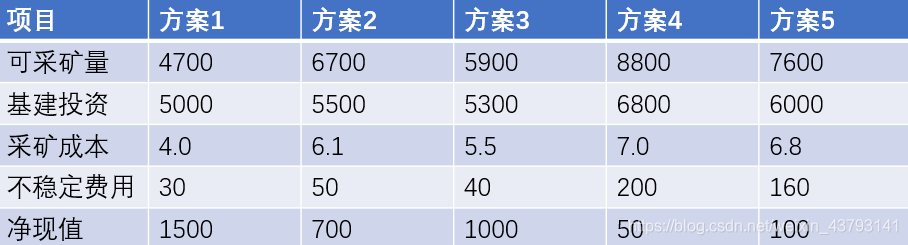
① 判断指标的类型
之前优劣解距离法(Topsis模型)有讲,指标一般分为极大型、极小型、中间型和区间型。那我们这里的第一步就是判断上述5个指标分别是什么类型的。
很明显,可采矿量、净现值是一个个极大型;基建投资、采矿成本、不稳定费用是极小型。
② 将指标正向化
这里出现了一个新词儿叫正向化(其实我之前在Topsis模型里有写到)。这里再来简单介绍一下,正向化就是将极小型、区间型、中间型这些指标转化为极大型。
将极小型转化为极大型的方法就是:max - x(中间型和区间型在之前的Topsis有介绍)
将这里的三个极小型指标(基建投资、采矿成本、不稳定费用)转化一下
转化结果如下:
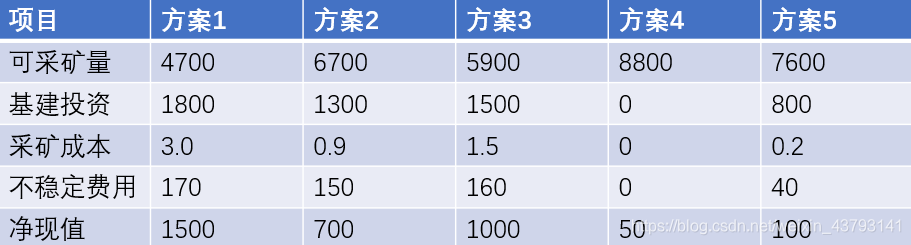
③ 对正向化后的矩阵进行标准化
这是正向化后的矩阵(matlab表示):
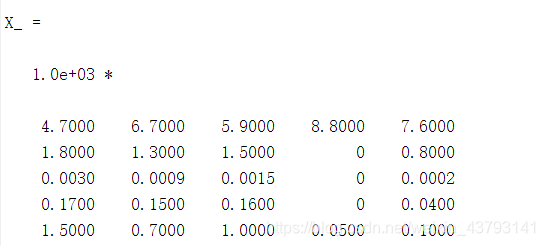
标准化方法如下:(z(ij)是标准化矩阵中的每个元素,x(ij)是正向化矩阵中的每个元素)
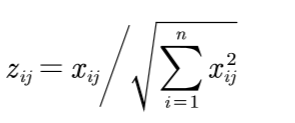
标准化后的矩阵(Z_)如下:

注意:这里得到的标准化中的矩阵不能有负数,也就是数值都必须大于等于0,如果有负数,需要按照下面这种方法重新进行标准化。
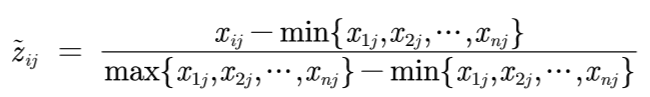
④ 计算概率矩阵P
计算方法如下:(这里的Z~(ij)就是前面的Z(ij))
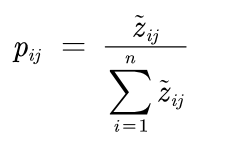
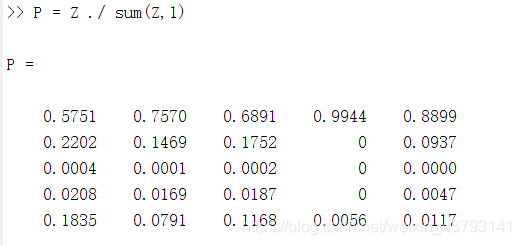
计算结果如下:
⑤ 计算每个指标的信息熵
计算方法如下:
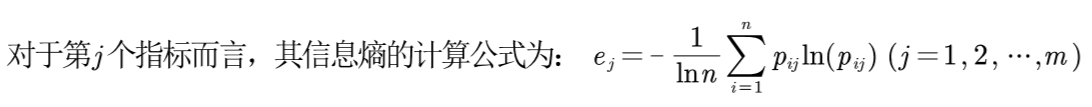
计算结果:(这里mylog是自定义函数,因为matlab log(0)是负无穷,我们这里的要求是log(0)= 0)

⑥ 计算信息效用值
计算方法如下:
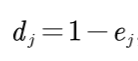
计算结果如下:

⑦ 计算熵权
计算方法如下:
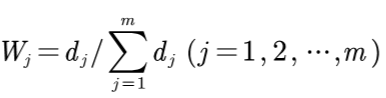
计算结果如下:
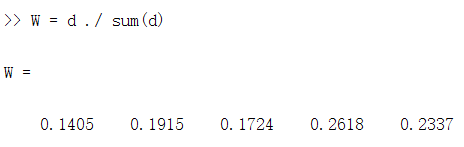
这个结果和前一篇博客(模糊综合评价)提到的是相同的
注:以上内容参考清风老师的数学建模视频
https://www.bilibili.com/video/BV1DW411s7wi?p=6
上一篇模糊综合评价博客地址:
https://editor.csdn.net/md/?articleId=105326566
Topsis模型地址:
https://editor.csdn.net/md/?articleId=105117447
