深度卷积网络:实例探究
实例探究(Case studies)
为什么要进行实例探究(Why look at case studies?)
从中获得灵感,借鉴一些效果很好的网络来完成自己的任务。
一、经典网络(Classic Networks)
1、LeNet-5
Input >> Conv >> Pool >> Conv >> Pool >> FC >> FC >> FC(softmax)
输入是单通道图片。随着网络加深,图像的大小在缩小,但通道的数量在增加。大约有60K的参数。
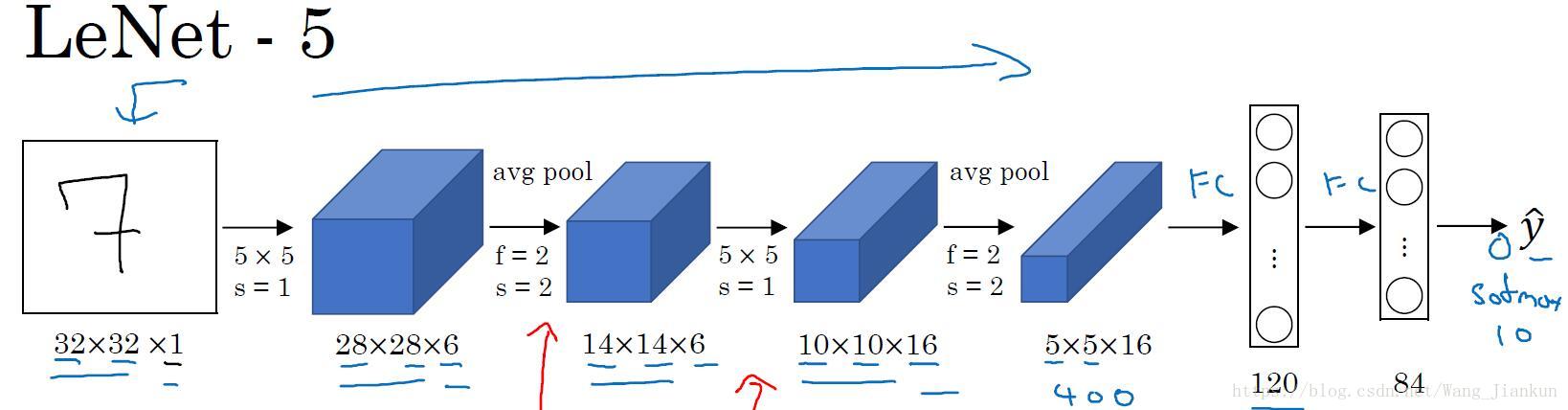
node: 该网络使用的是 average pool 和sigmoid,是因为提出的时间较早。现在基本上是用 max pool 和 ReLU。
2、AlexNet
论文作者提出的原网络有另一种类型的层(LRN),类似归一化的操作,后来被证明并没有太大的作用,所以就不用了。
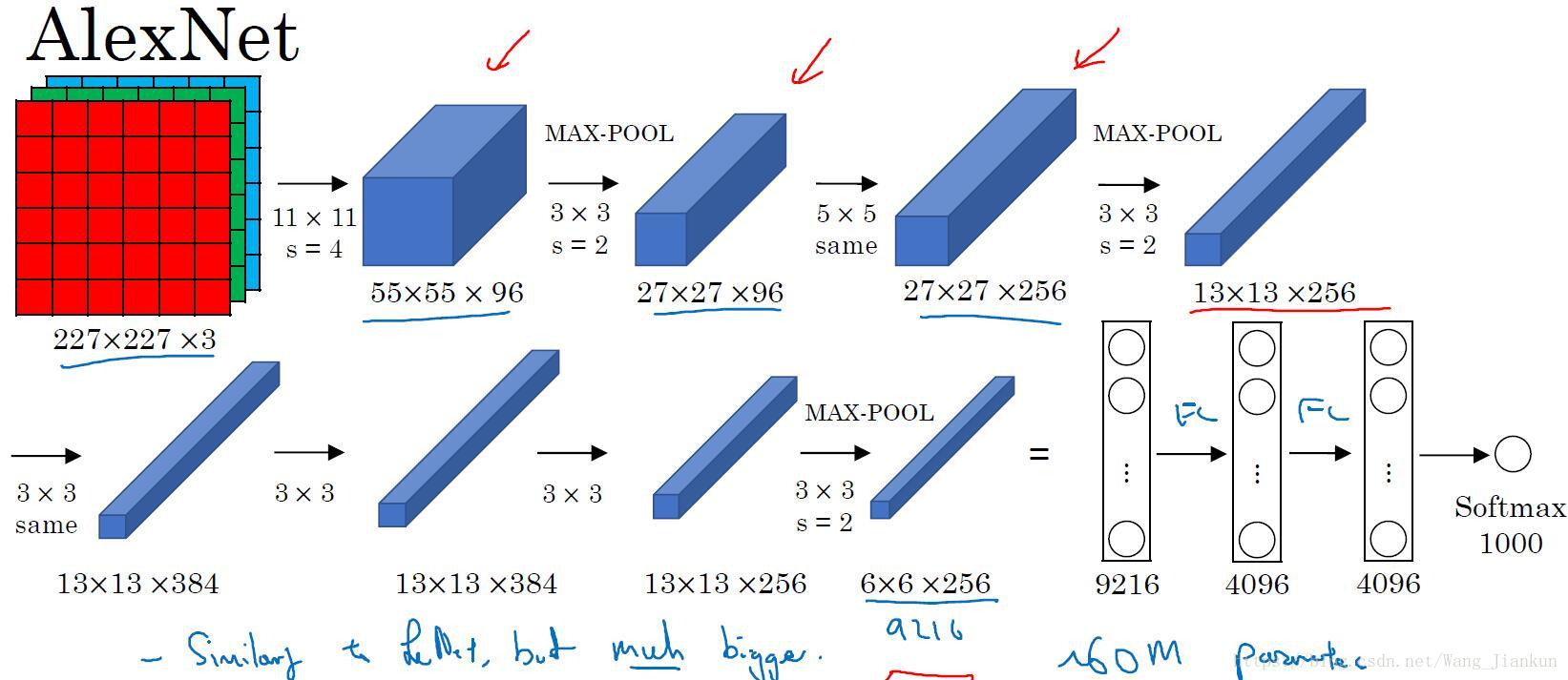
比LeNet-5的参数更多,效果也更好。
3、VGG-16
该网络所用的卷积和最大池化层操作都是一样的。网络更深,参数也更多,且图像尺寸缩小和信道数增加是有规律的。

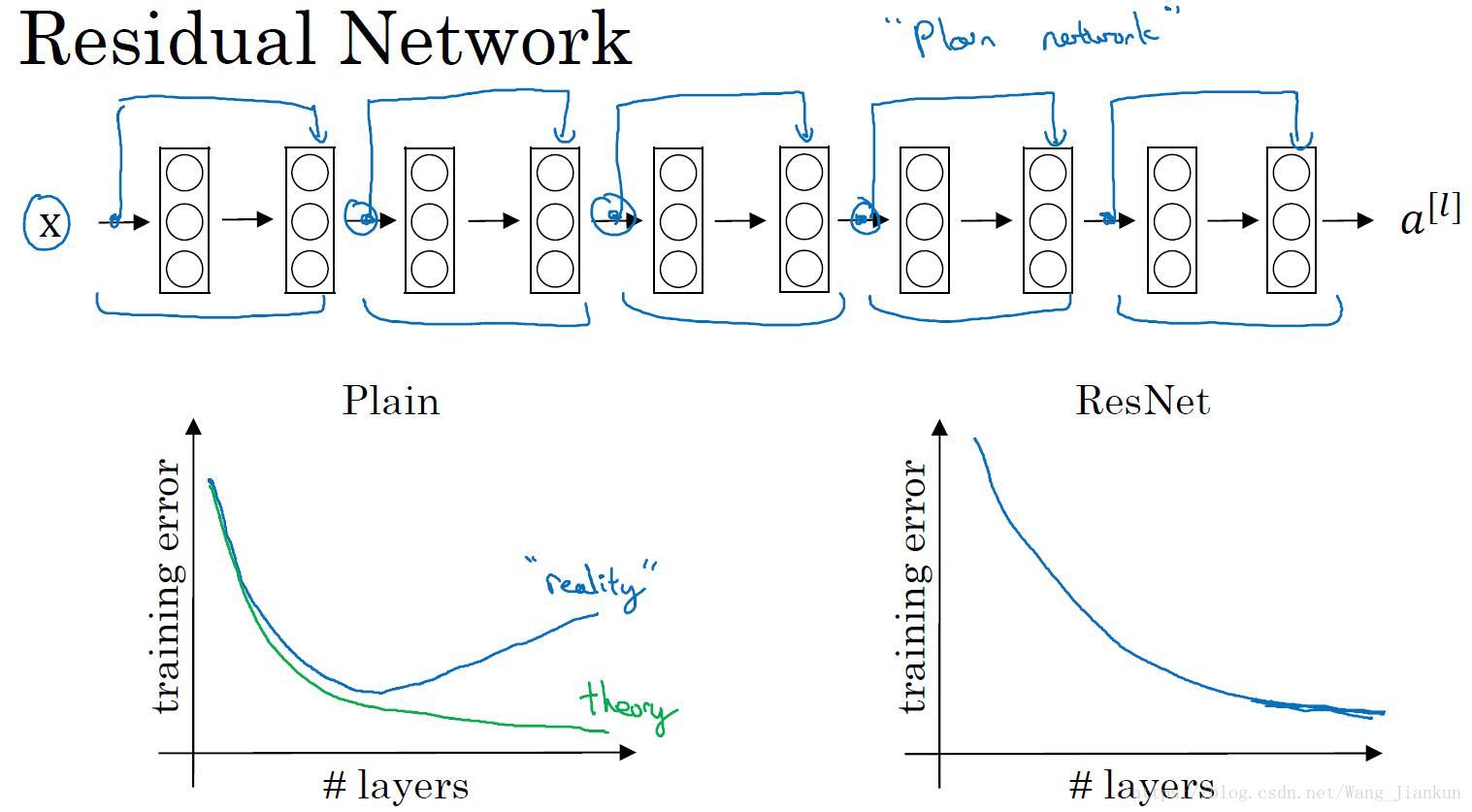
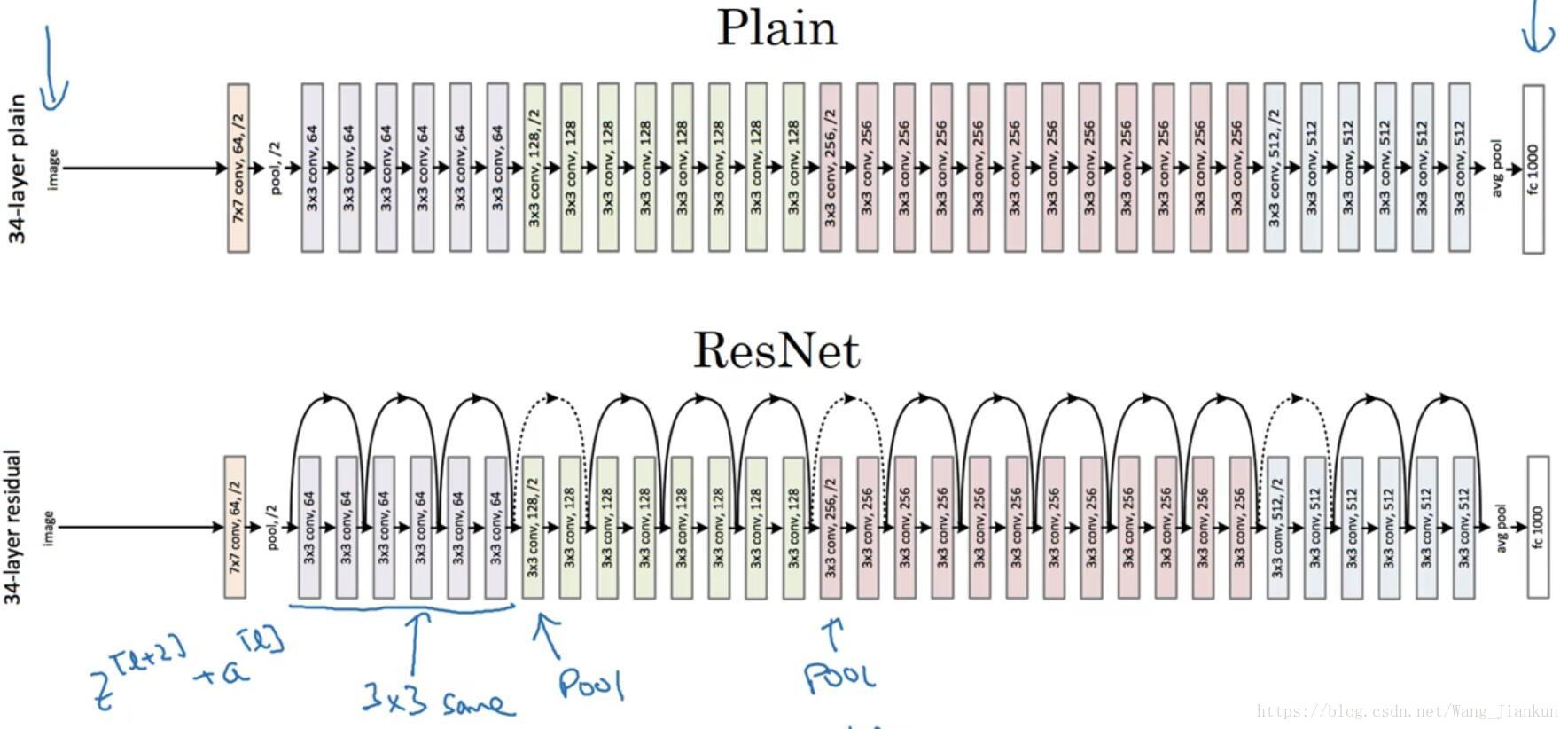
二、残差网络(ResNets)
残差块:
增加了一个从a[l]直接到z[l+2]的连接,称为“short cut”或“skip connection”。

残差网络和普通网络对比:
随着网络的加深,可能出现梯度消失和梯度爆炸的问题。所以在没有残差块的普通神经网络中,训练的误差实际上是随着网络层数的加深,先减小再增加。但在有残差的ResNet中,即使网络再深,训练误差也是随着网络层数的加深逐渐减小。
残差网络的理解:
在普通CNN后加一个残差块。如果这两层没有学到东西,增加了残差块后性能也并不逊色于没有增加残差块简单的网络,因为对于残差块来学习a[l+2]= g(a[l]) = relu(a[l]) = a[l] 这个恒等函数是很容易的。如果增加的网络结构能够学习到一些有用的信息,那么就会提升网络的性能。
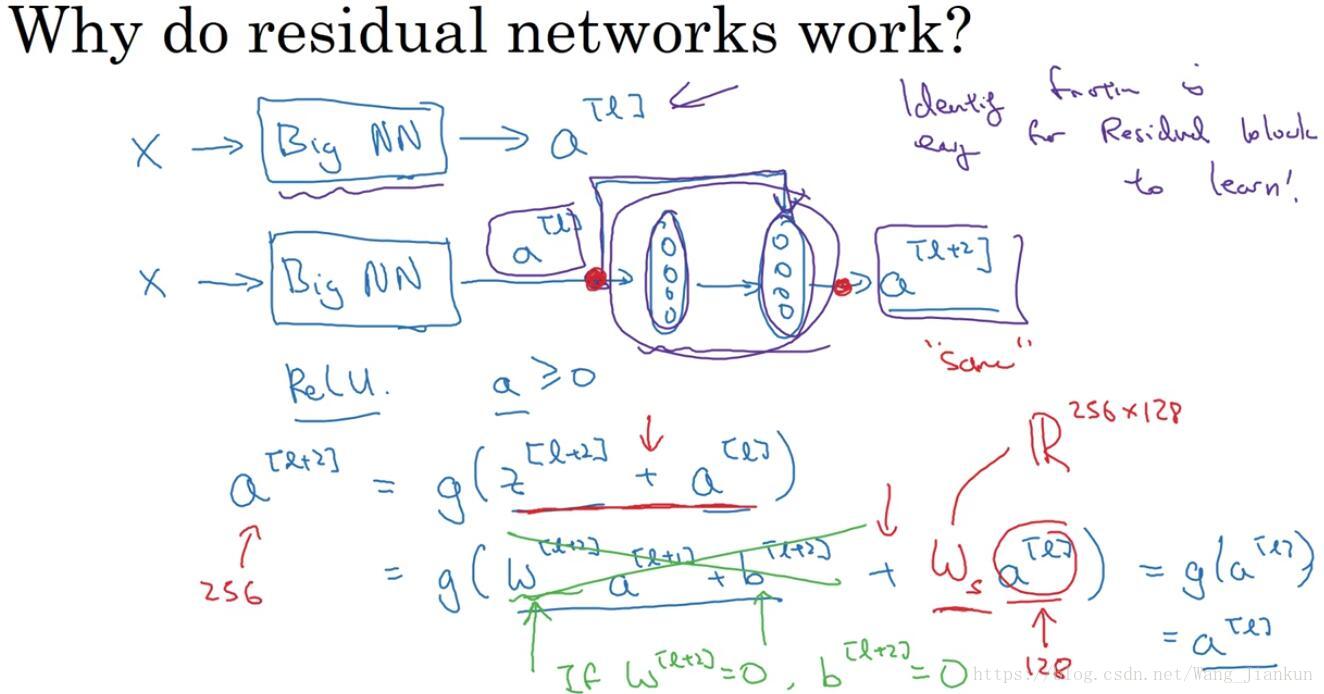
因为a[l+2]=g(z[l+2]+a[l]),所以z[l+2]和a[l]的维度要一样。因此ResNet在设计中使用了很多相同的卷积。如果在池化层上或者维度不匹配可以添加系数矩阵来修正。
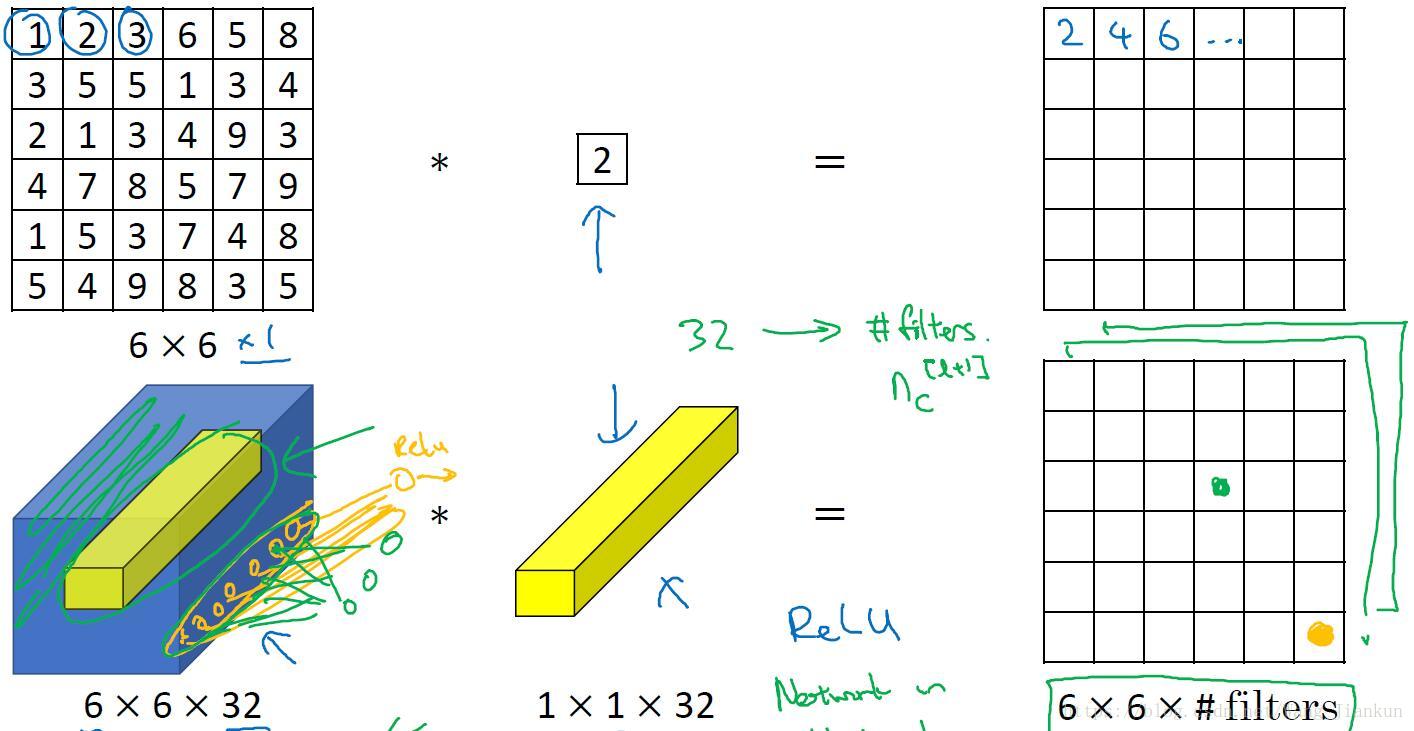
三、1x1卷积核(1x1 Convolutions)
1x1卷积核:
- 在二维上,进行1x1的卷积就是把图片的每个元素和一个这个1x1卷积核数字相乘。
- 在三维上,与1×1×nC卷积核进行卷积,相当于三维图像上的1×1×nC的切片,也就是nC个点乘以卷积数值权重,通过Relu函数后,输出对应的结果。其实可以看作是对一个nC切片和一个神经元的全连接神经网络。而不同的卷积核则相当于不同的隐层神经元。
作用:
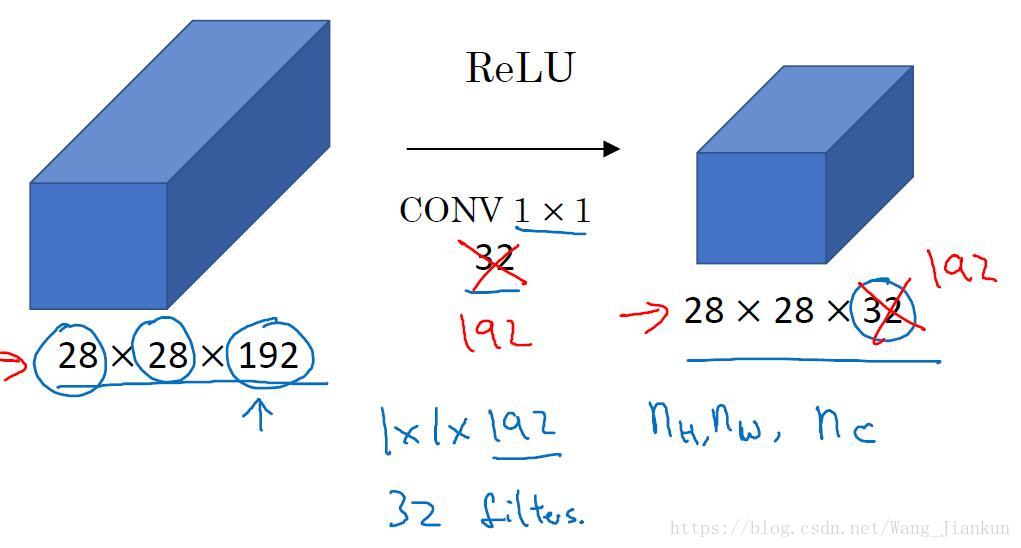
在不改变图像尺寸的同时改变通道数。
四、Inception 网络(Inception Network)
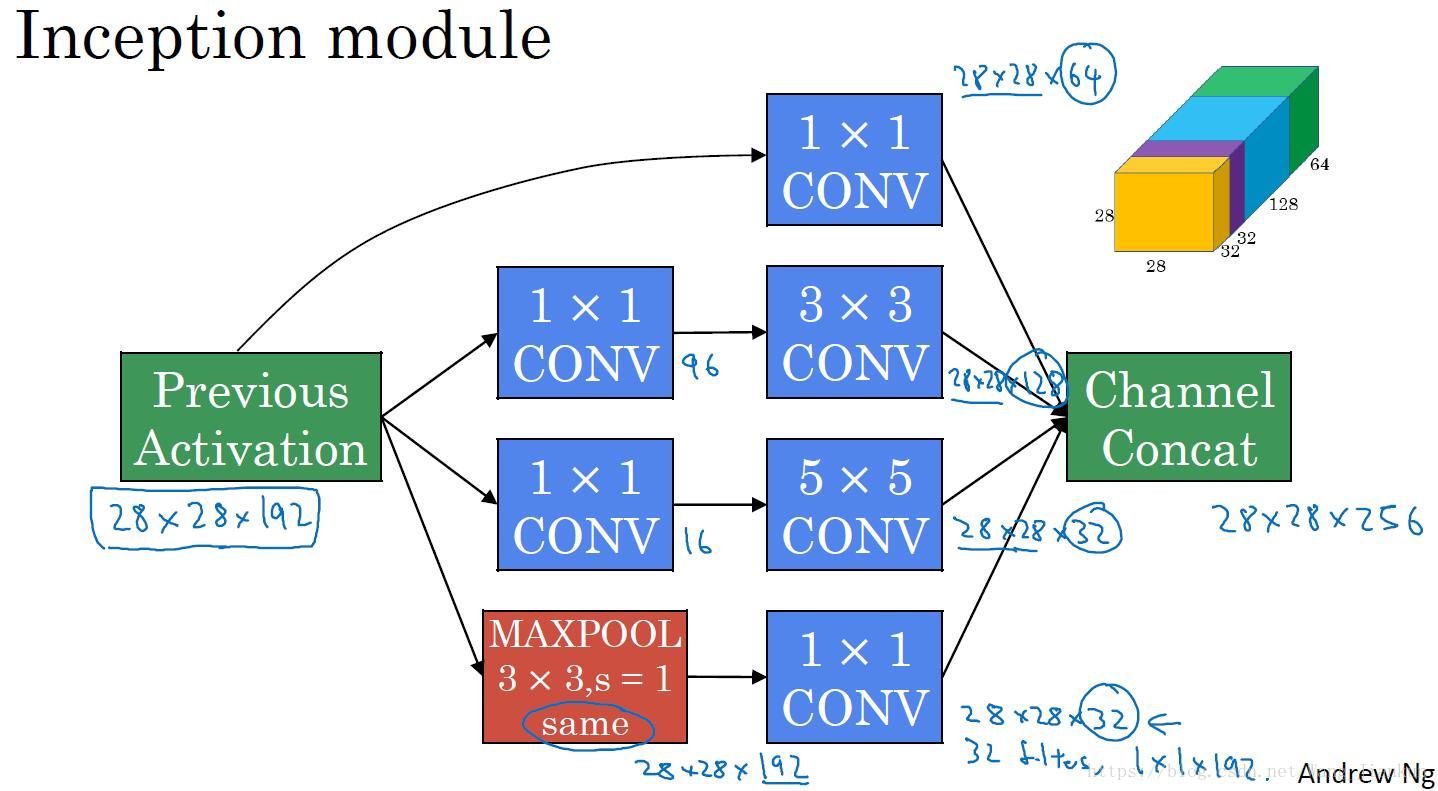
Inception 网络的作用(Motivation for inception network):
- 使用Inception Network 我们无需去考虑在构建深度卷积神经网络时,到底该用多大的卷积核及是否添加池化层。在每一个Inception block中包含了1x1、3x3、5x5的卷积核和 same padding的MAX-POOL,让模型自己学习需要用哪个。
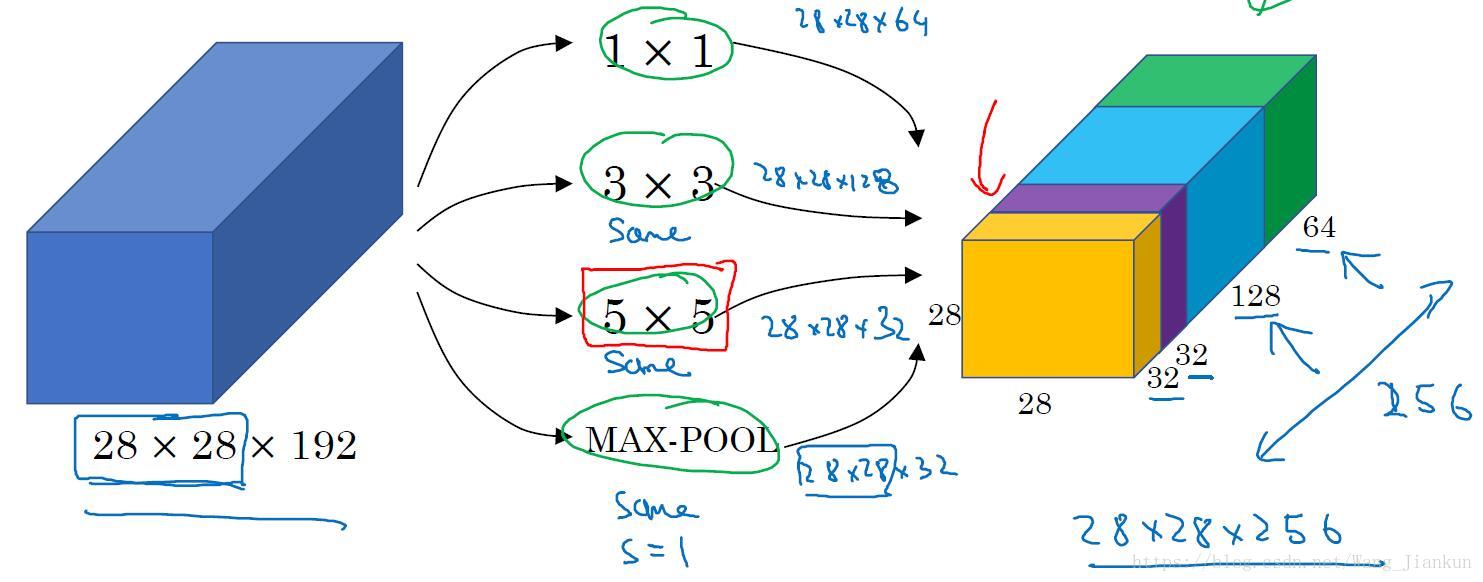
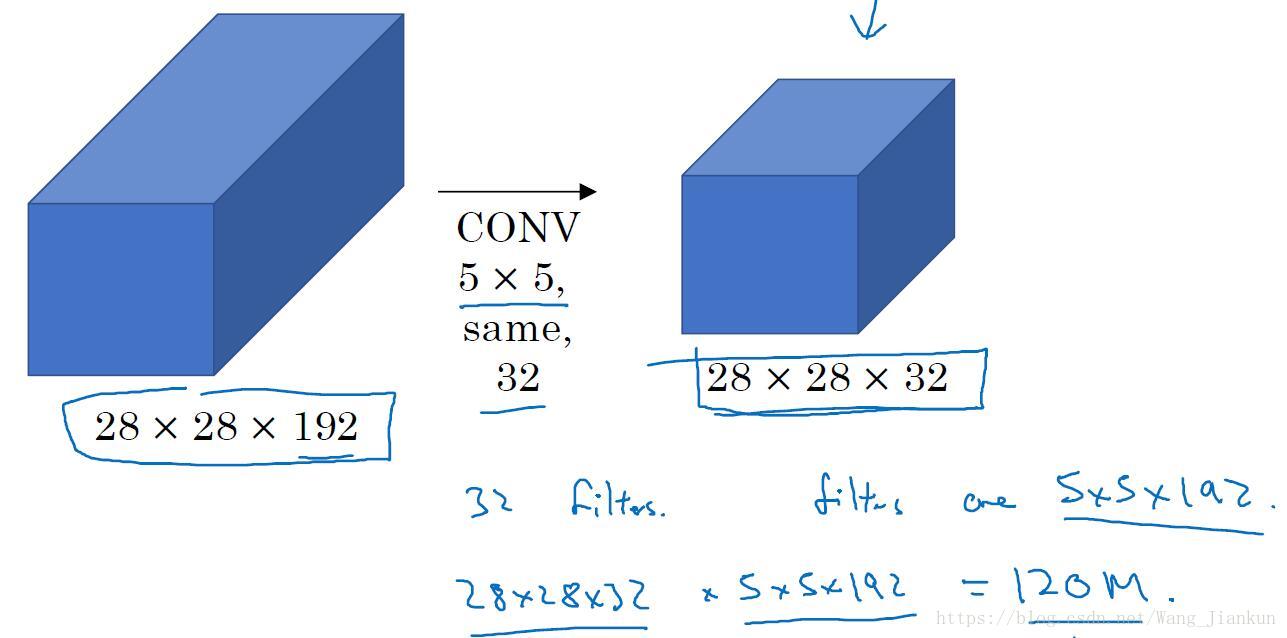
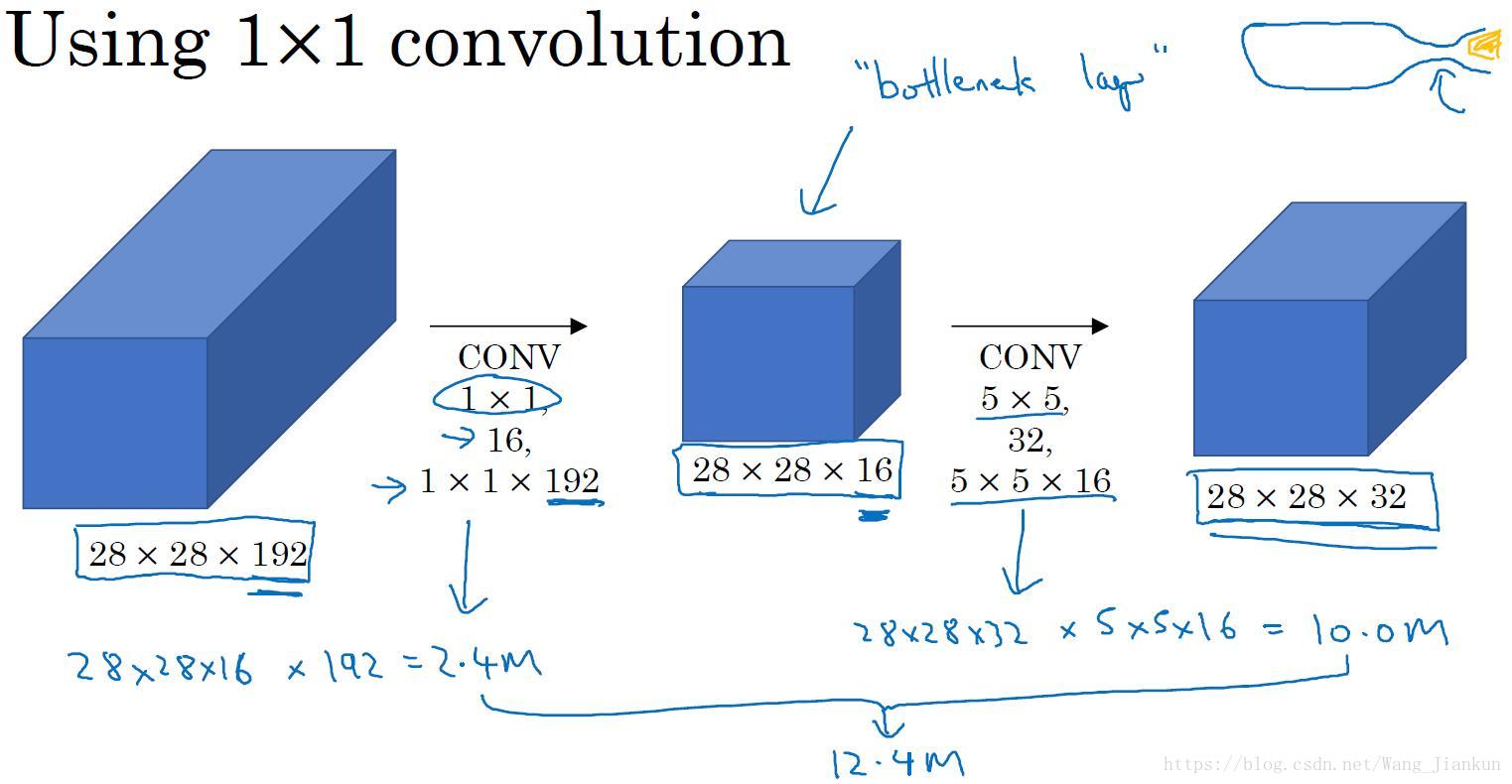
计算成本:
- 下面是不加和加1x1卷积层的计算成本(只所需乘法运算的次数,因为加法计算成本比较低)。可以看出加了1x1卷积层可以很大程度的减小计算成本,而且如果选择得当的话,对模型的效果不会产生很大的影响。
完整的Inception 模块:
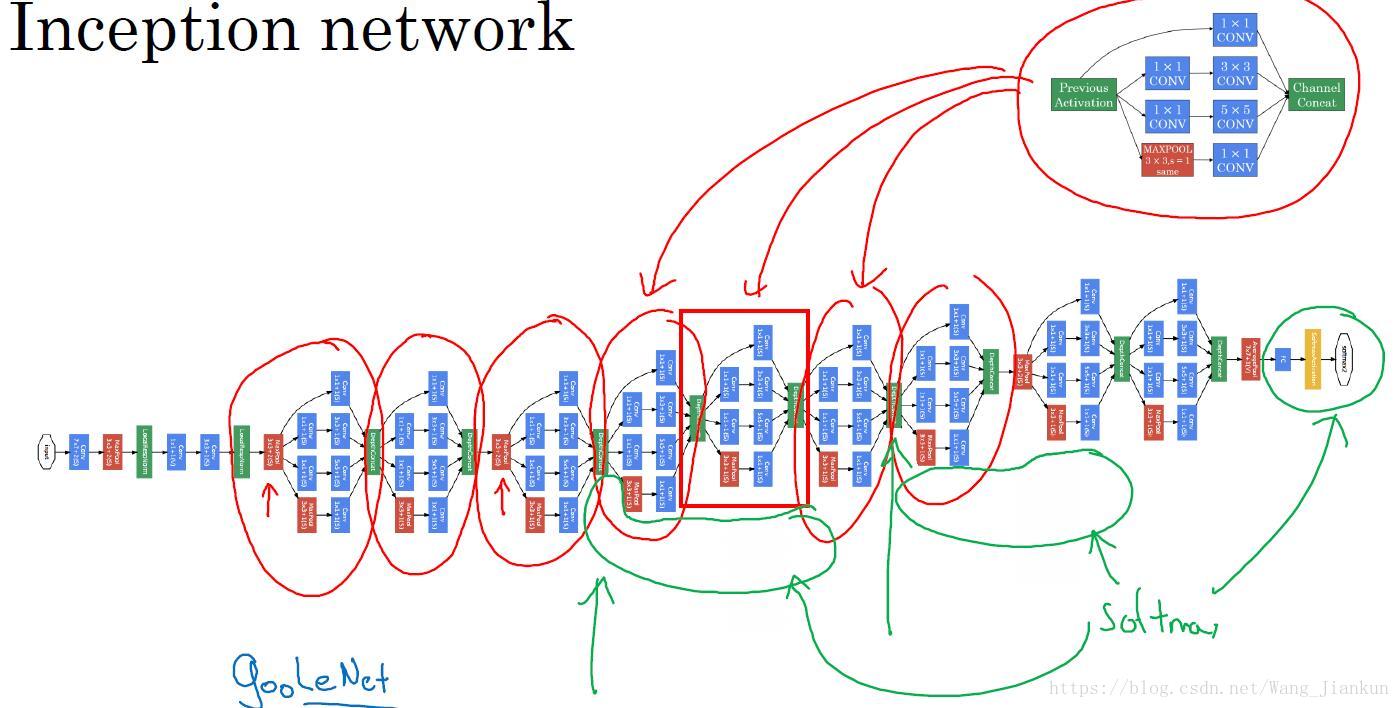
Inception Network:
- 重复Inception 模块,中间适当添加的pool层,构成了Inception Network,也称为GoogLeNet。其中有多个softmax层,用来检查是不是过拟合了。
- Inception 名称即盗梦空间的电影名,意为 we need to go deeper 即我们希望搭建更深的网络。
使用CNN的实用建议(Practical advices for using ConvNets)
五、使用开源的实现方案(Using Open-Source Implementation)
当在论文中发现感兴趣的模型,与其从零开始搭建,不如看看其有没有开源的实现。如果有可以从网上下载,然后进行修改和应用。
最出名的开源社区:GitHub
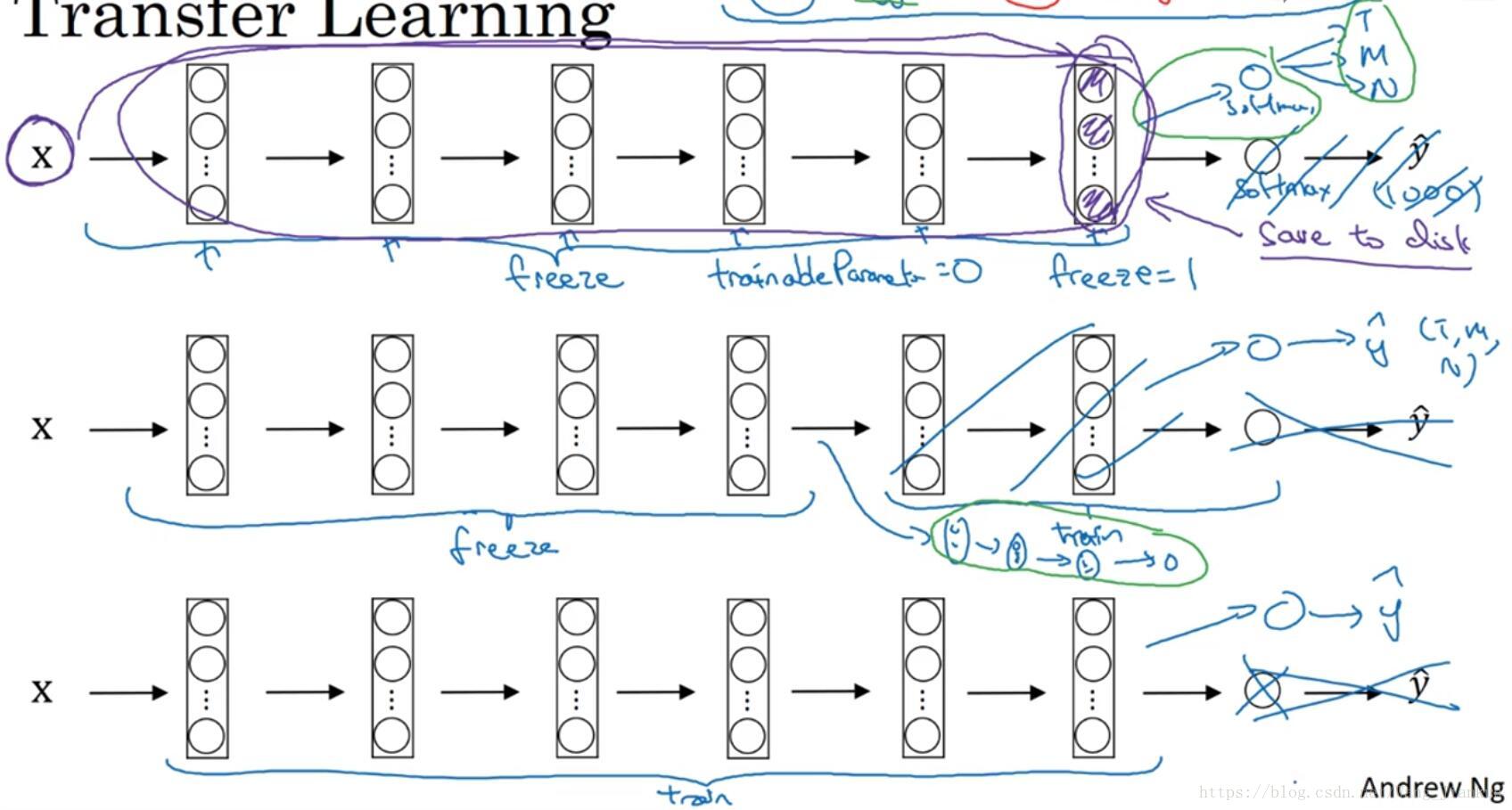
六、迁移学习(Transfer Learning)
开发应用的时候,我们通常只有少量的数据集,对于从头开始训练一个深层网络结构是远远不够的。但是我们可以应用迁移学习,应用其他研究者建立的模型和预训练的权重,来初始化我们的模型。可以根据我们拥有的数据量大小来决定要冻结(freeze)多少层,即在我们的模型中不再训练这几层的权重。然后用我们的数据只训练最后的某几层,也可以修改最后这几层的网络结构。
- 小数据集:除了softmax层其它层全部冻结。把softmax层修改成自己想要的。
- 中数据集:根据情况不冻结后面的几层,可以根据需要修改这几层的网络结构。
- 大数据集:把预训练的权重当做初始化权重,训练所有权重。
加速训练的方法:把冻结的那几层看成一个固定函数,让我们的数据集先计算这个固定函数的结果,然后存起来。训练时直接用这个结果作为我们需要训练的哪几层网络的输入,然后进行训练,避免重复计算固定函数的结果。
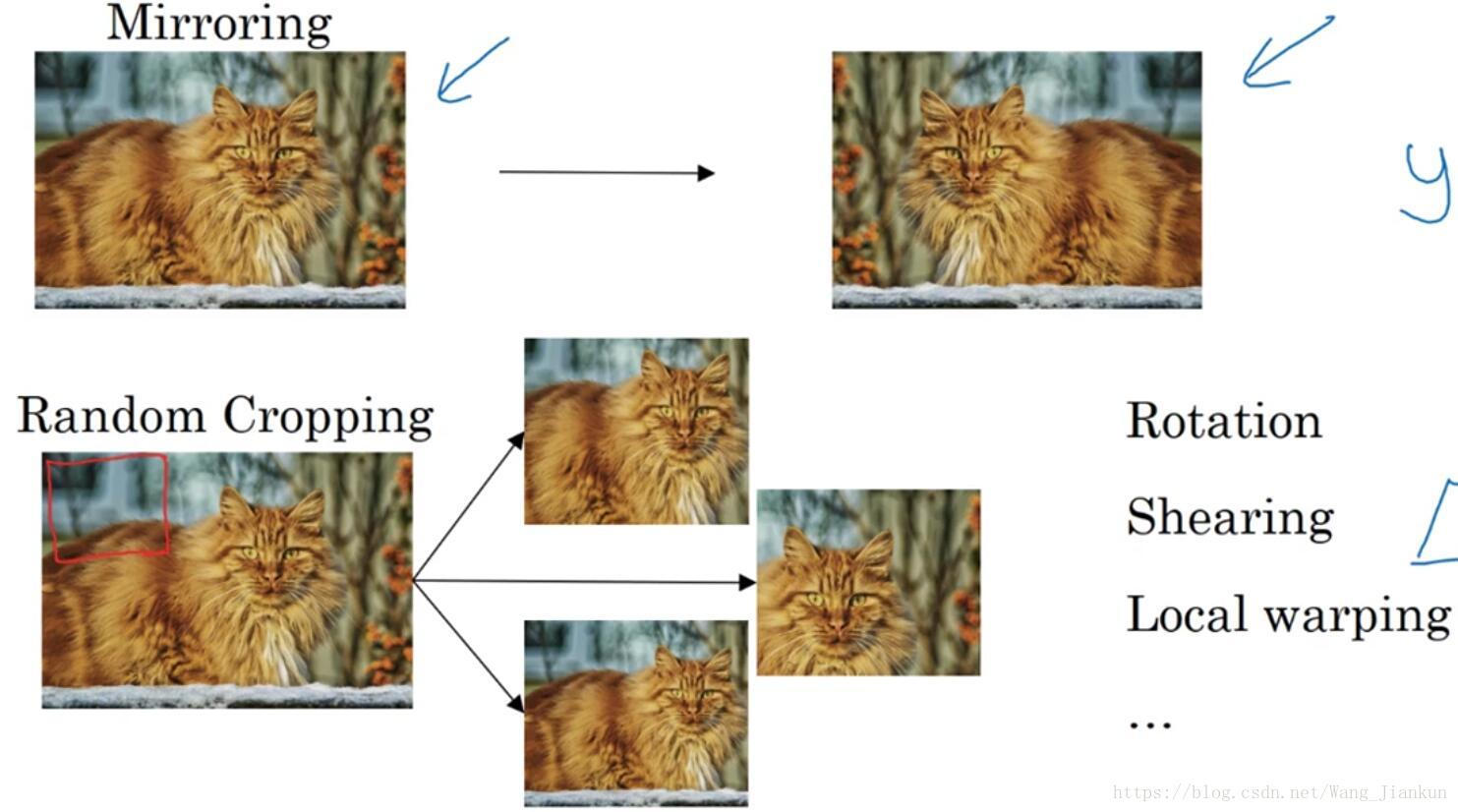
七、数据扩充(Data Augmentation)
目前而言对于计算机视觉,数据量总是不够的,所以可以用数据扩充的方法来增加我们的数据量。
常用的几种图像的变换:
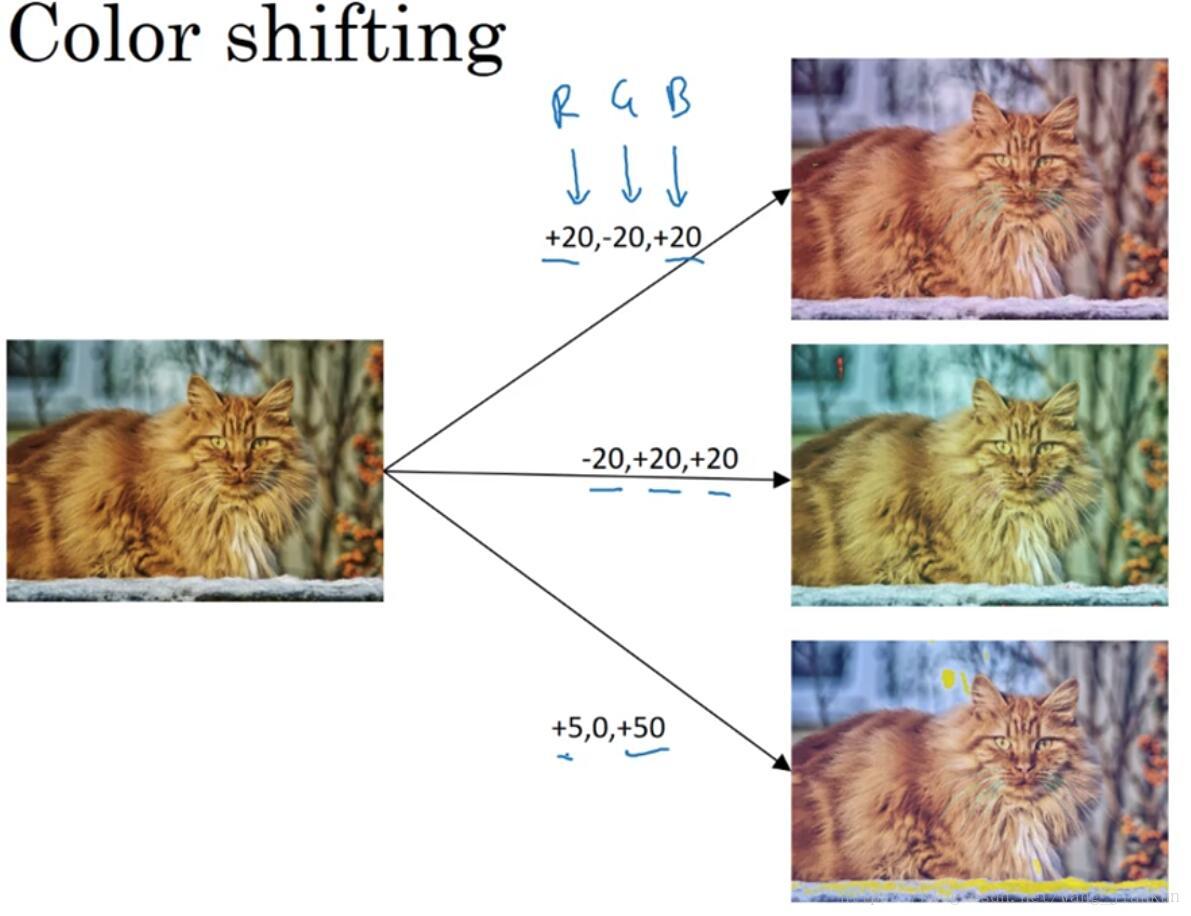
可以通过修改图像的颜色来增加数据。常用的方法:PCA(主成分分析)。
可以利用CPU/GPU的多线程或多核,使图像加载、变换和训练同时进行。

八、计算机视觉的现状(State of Computer Vision)
现状:
数据量不够,需要手工工程。
- 大量数据的时候,简单的算法和更少的手工工程。
- 少量数据的时候,更多的是手工工程。因为数据量太少,较大的网络结构或者模型很难从这些少量的数据中获取足够的特征。
在比赛中或在一个开源的数据集上取得更好效果的减小技巧
很难在实际的应用中使用,因为需要更多的计算成本。
Ensembling:独立训练多个网络模型,平均结果作为输出。
Multi-crop at test time:对测试图片的进行多种变换,然后在分类器中运行,输出平均结果。

建议:
