目标检测(Object detection)
一、目标定位(Object Localization)
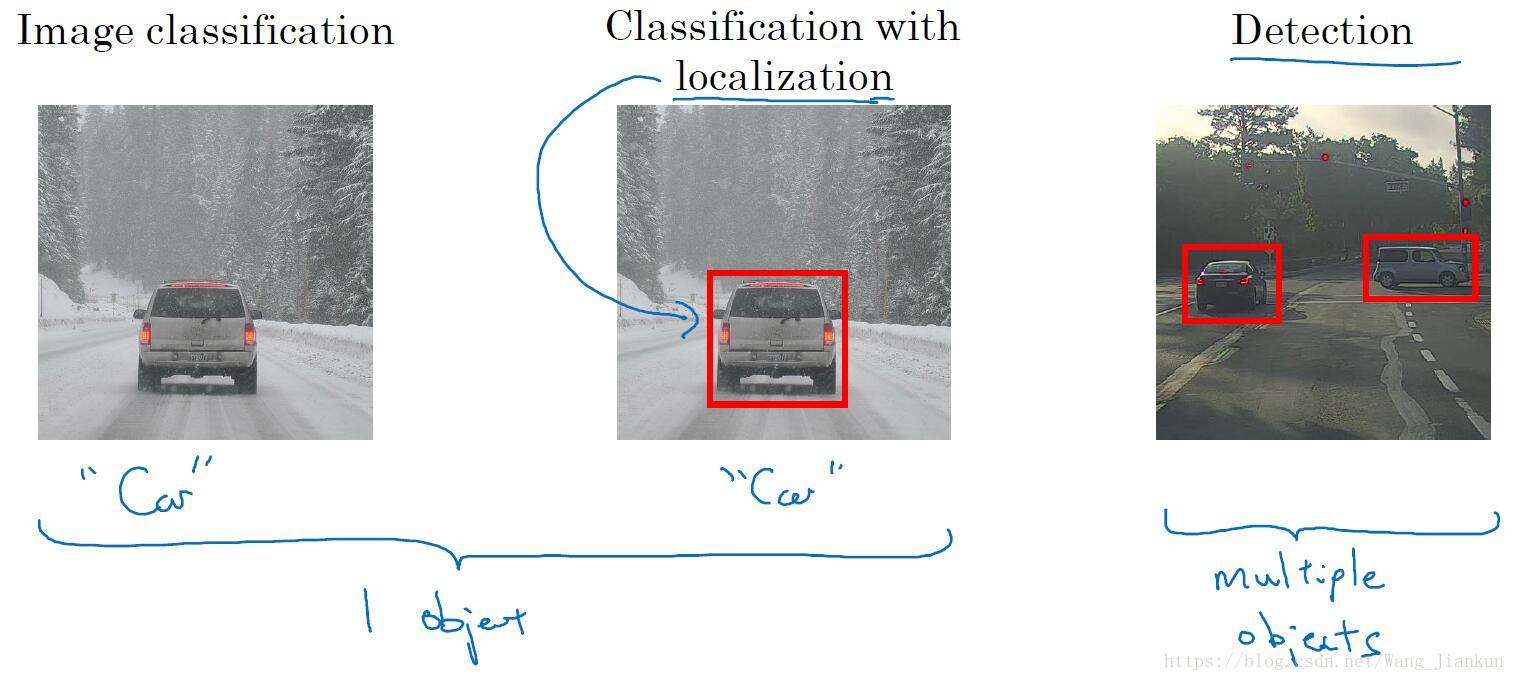
图像识别的三个层次:
- 图像分类:判断图像中是否包含某一类物体,并且假定每张图像只有一个目标。
- 目标定位:既要图像分类,还要输出这个目标位置。
- 目标检测:检测出图像包含的所有感兴趣的目标,并定位。
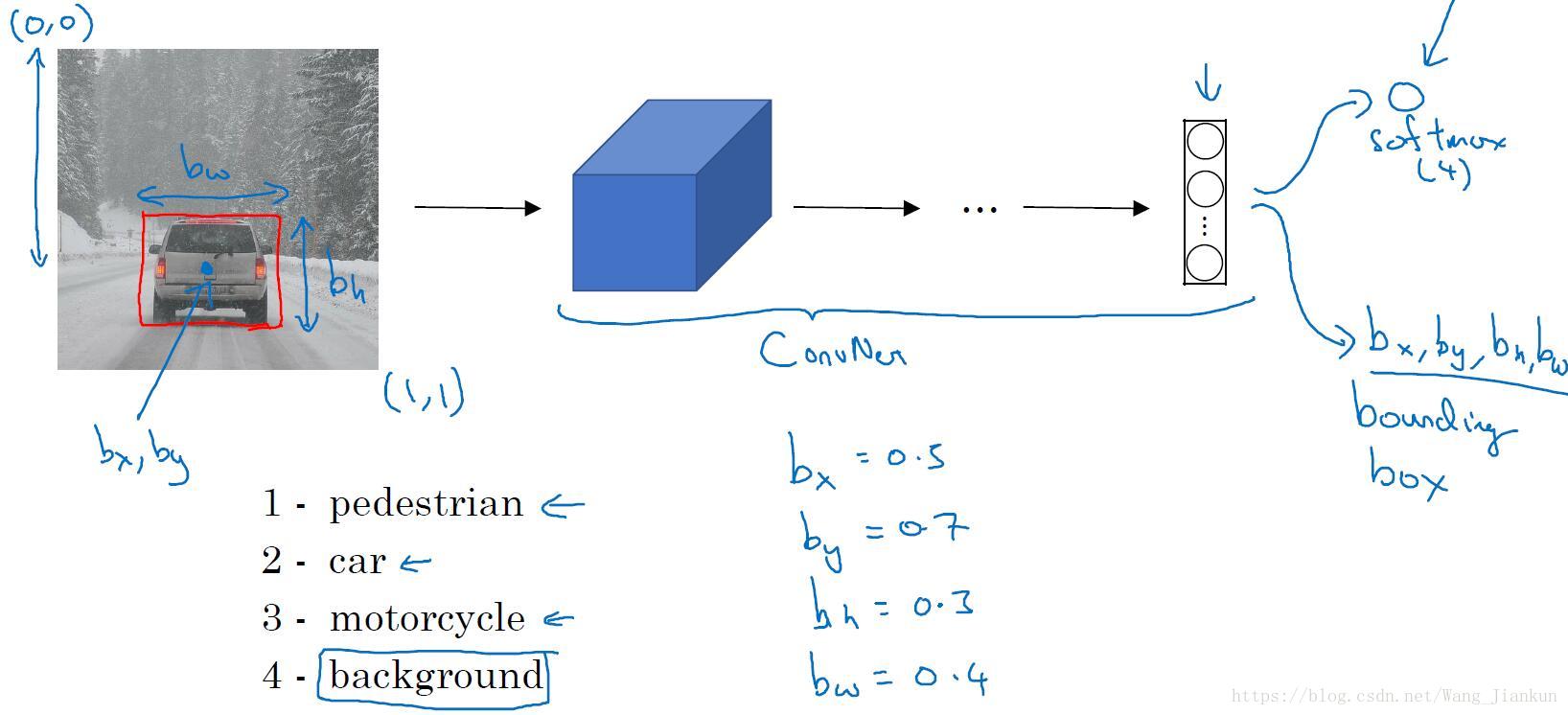
目标定位:
需要修改输出层的结构,和数据集的标签。输出层不仅要输出各类别的概率,还要输出目标的位置坐标。
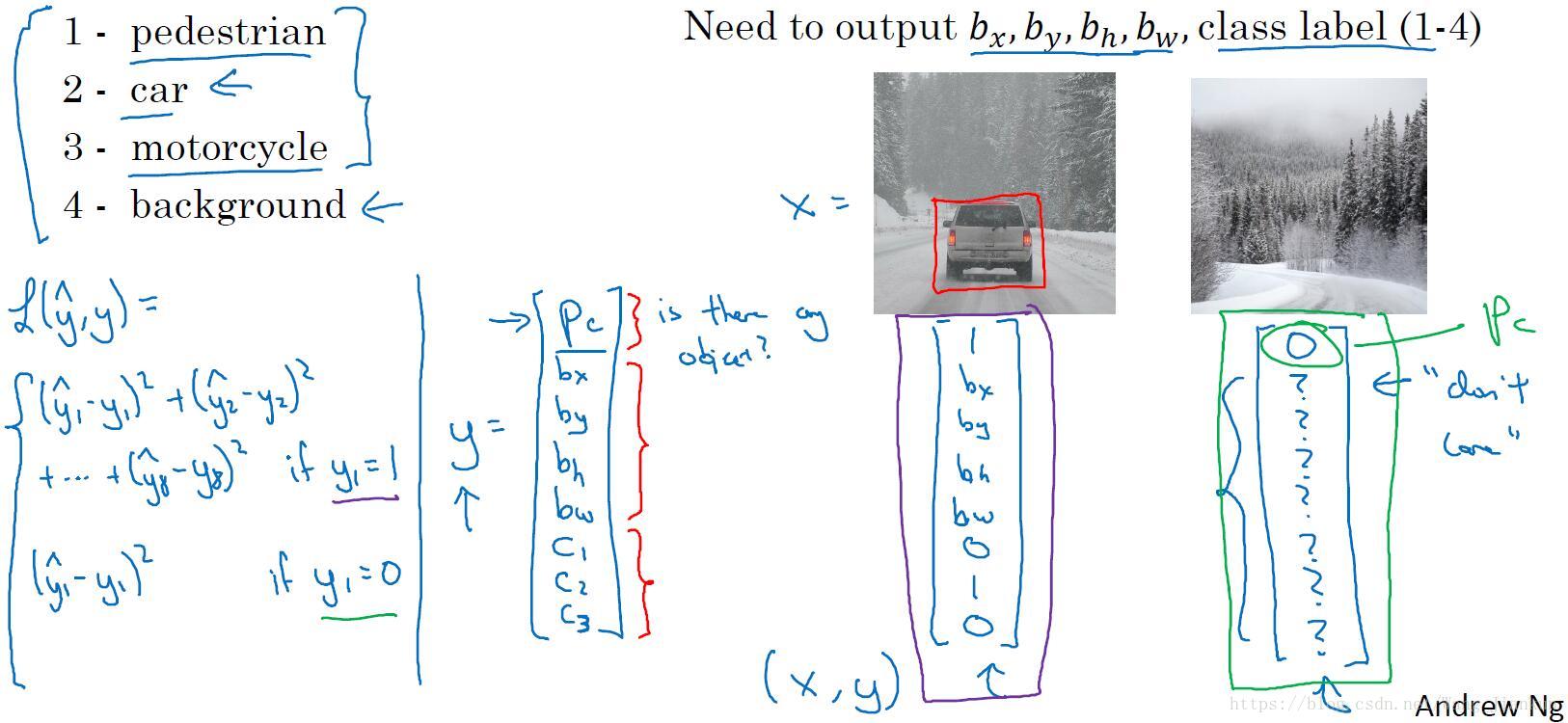
损失函数和标签:
- Pc:表示是否包含要检测目标。如果不包含为0,其它的输出没有意义。
- 根据情况,可以对不同的输出元素使用不同的损失函数,如:对多类别概率使用交叉熵损失函数;对边界框值使用平方误差; 对Pc使用 logistic regression 损失函数。
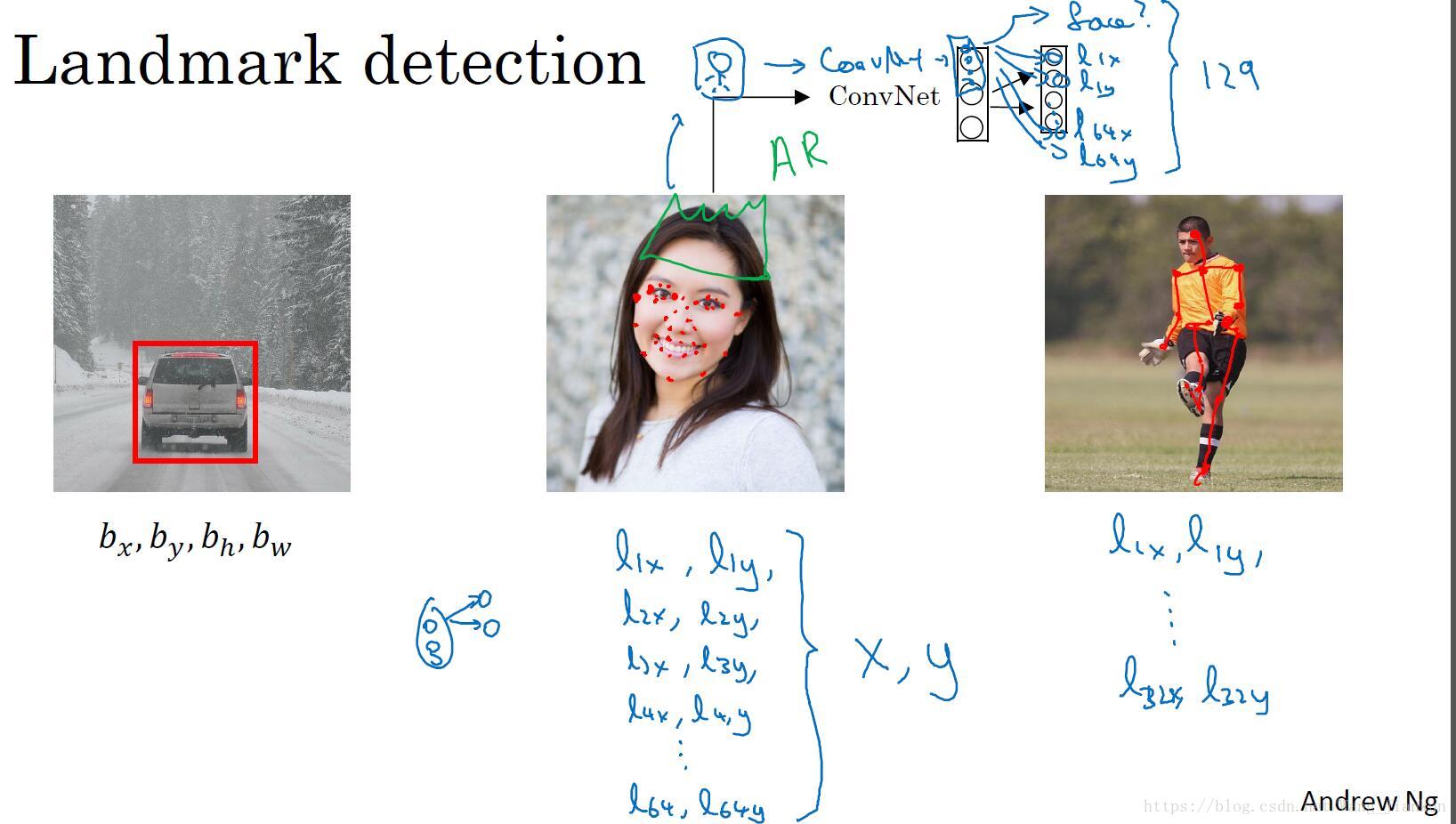
二、特征点检测(Landmark Detection)
在训练标签中添加特征点,并修改模型的输出层使其输出特征点坐标值,从而实现特征点检测。
两个例子:
- 人脸表情识别:通过标定数据集中特征点的位置信息,来对人脸进行不同位置不同特征的定位和标记。AR的应用就是基于人脸表情识别来设计的,如脸部扭曲、增加头部配饰等。
- 人体姿态检测:通过对人体不同的特征位置关键点的标注,来检测人体的姿态。
三、目标检测(Object Detection)
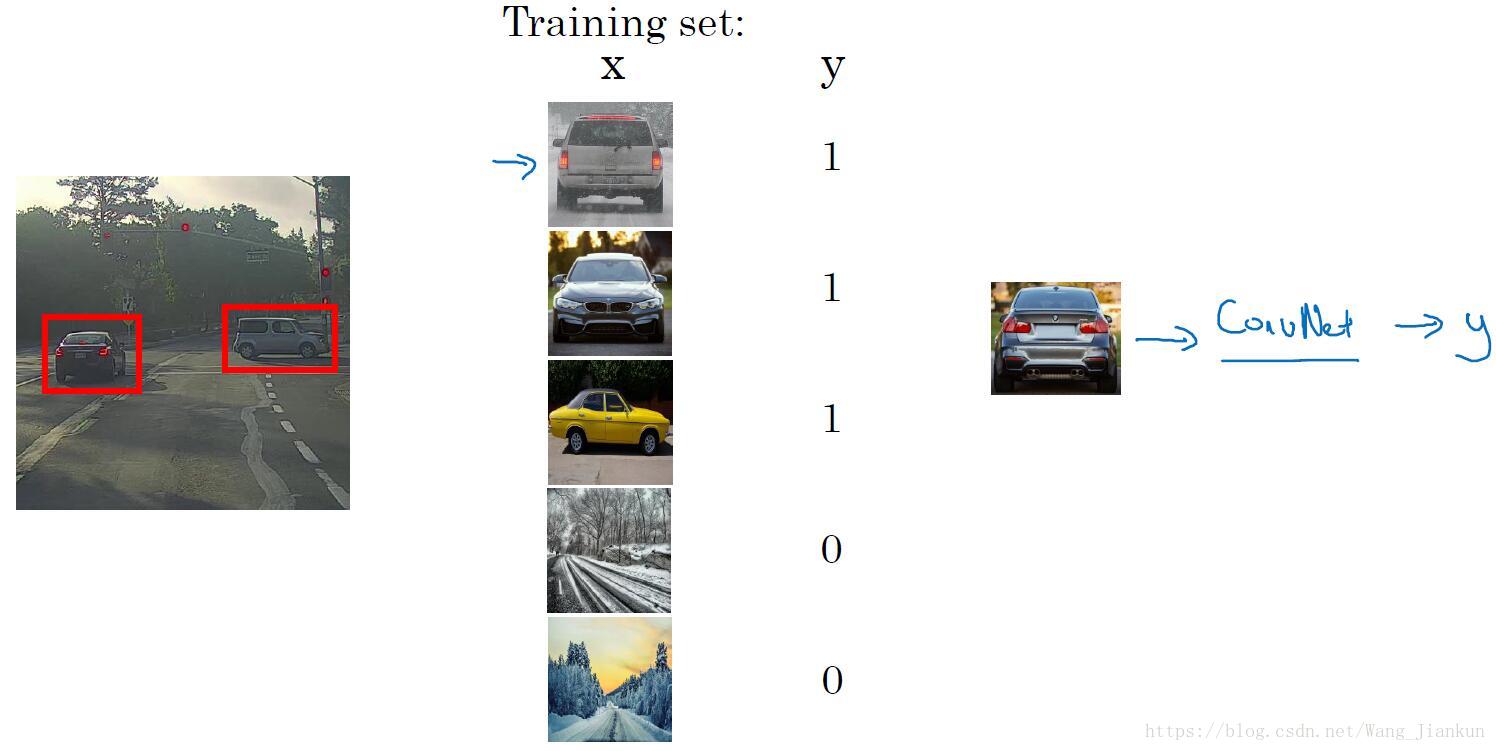
训练了一个分类模型。
- 输入X:将有目标的图片进行适当的剪切,使图像刚好只包括目标,训练集中也应包含没有目标的图像。
- 标签Y:有目标为1,没目标为0。
实现目标检测:把图像裁剪成任意大小(可用滑动窗口实现),输入分类器,即可判别出是否包含目标同时也知道了目标的位置。
四、卷积的滑动窗口实现(Convolutional Implementation of Sliding Windows)
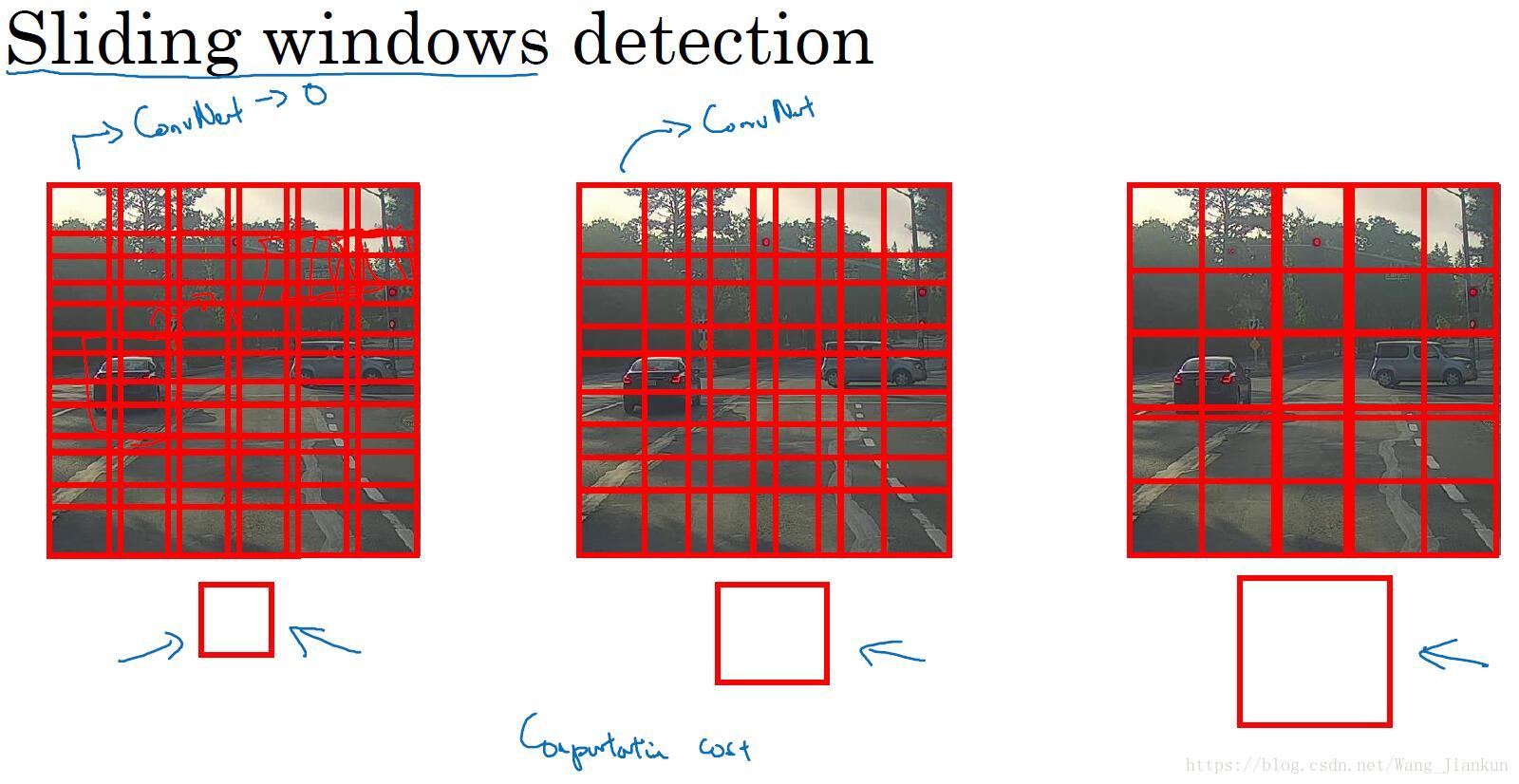
滑动窗口检测:
设置一系列尺寸不同的方框,每一种方框都从左向右、从上往下有规律的遍历图像,把每一个方框包含的图片区域输入不同的分类器,进行分类判别。即可实现目标检测。
缺点是计算成本太大,方框尺寸的细分程度对定位的精度(粗粒度)影响很大。
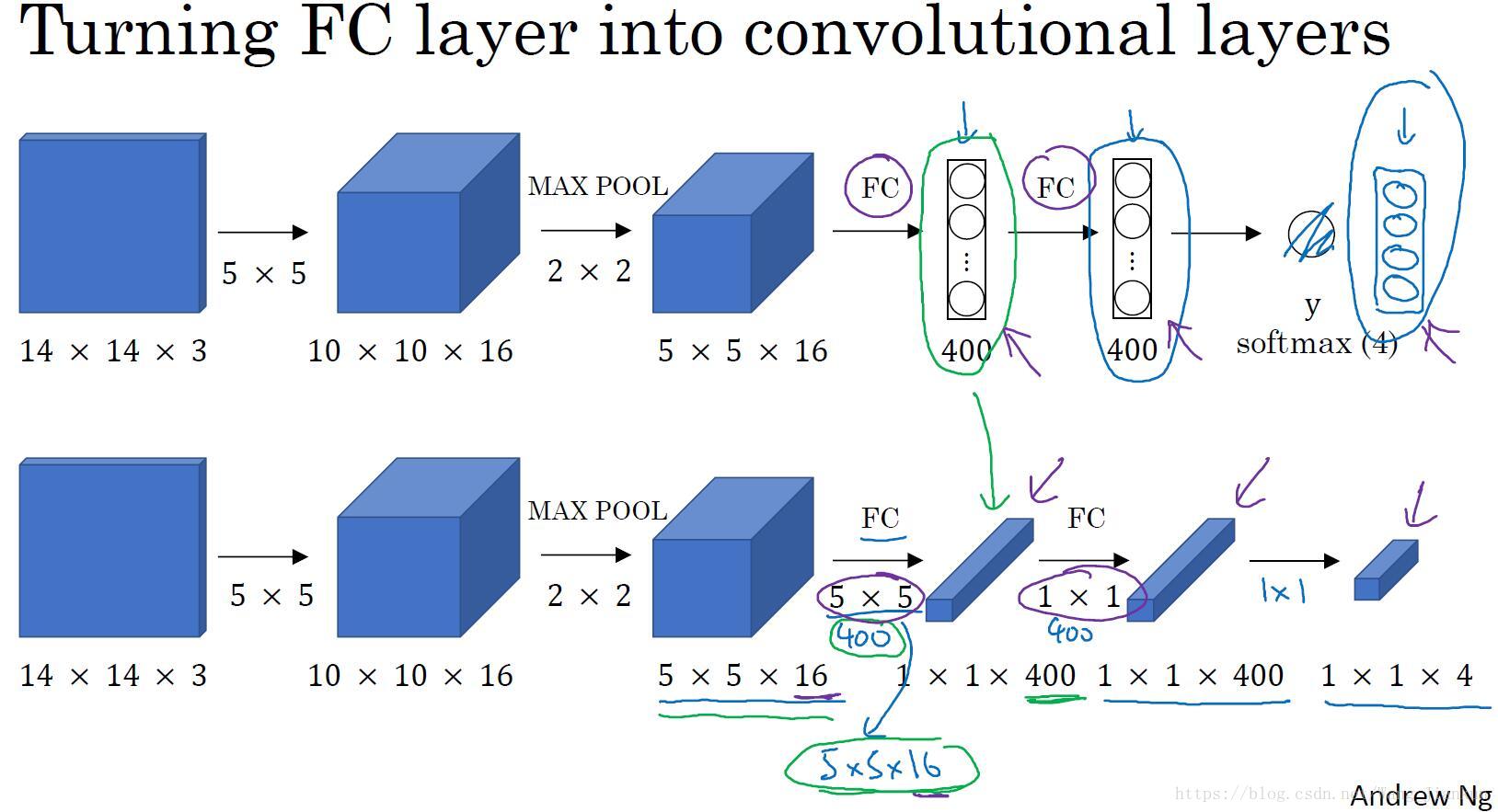
卷积层替代全连接层:
利用1×1的卷积替代全连接层。
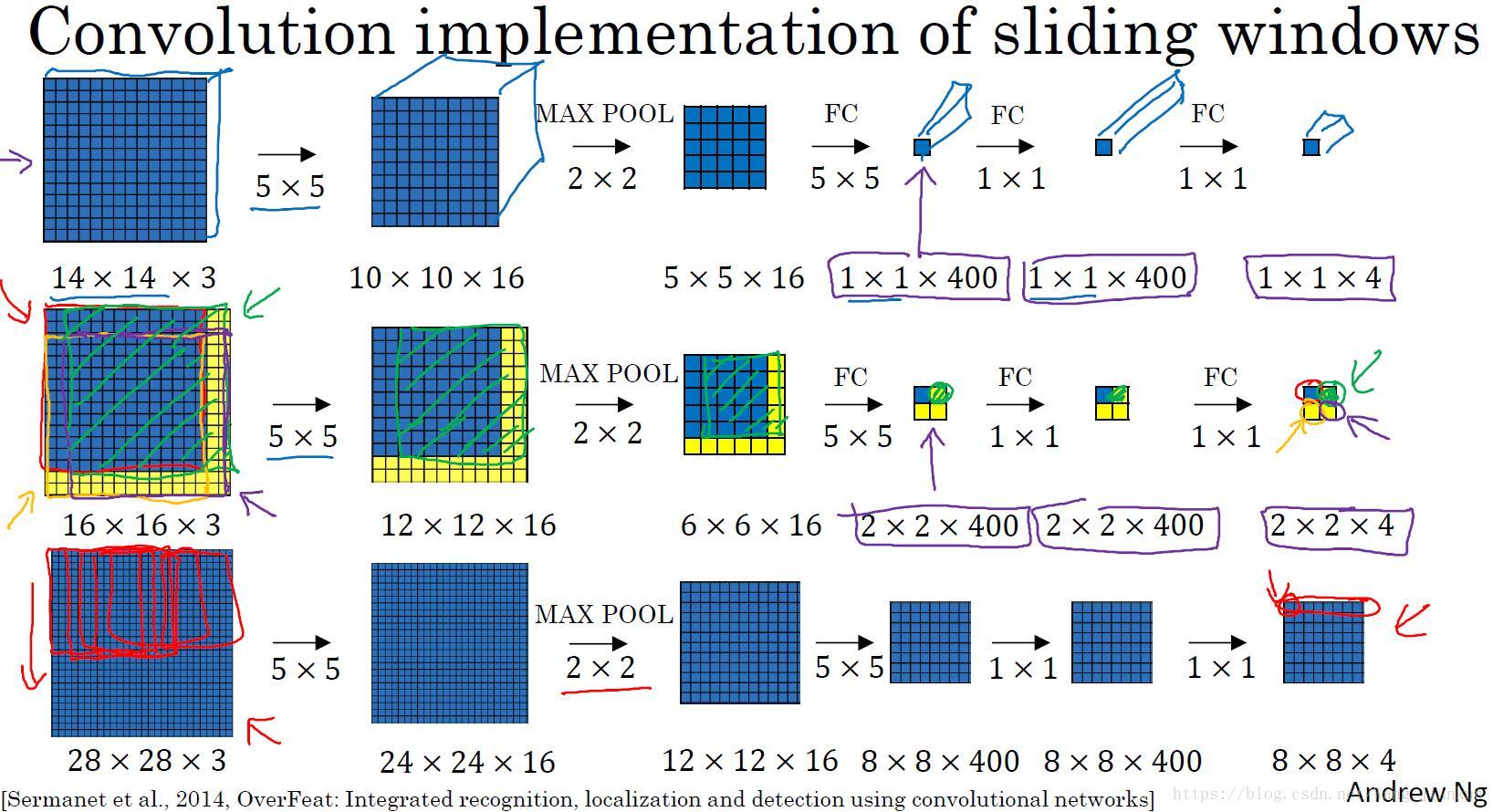
卷积实现滑动窗口:
不用把图片进行分割后输入模型,而是把这张图片输入到卷积神经网络中进行计算,因为各子图重叠部分可以共享大量的计算。只需一次前向传播,就可以同时得到所有子图的预测值。
输出层尺寸为 :横向子图数 x 纵向子图数 x 类别数
五、预测边界框(Bounding Box Predictions)
受边界框尺寸的细分程度的影响,预测结果和实际目标边框可能会有偏离。

YOLO 算法很好的解决边界框不准确的问题,下面会讲。
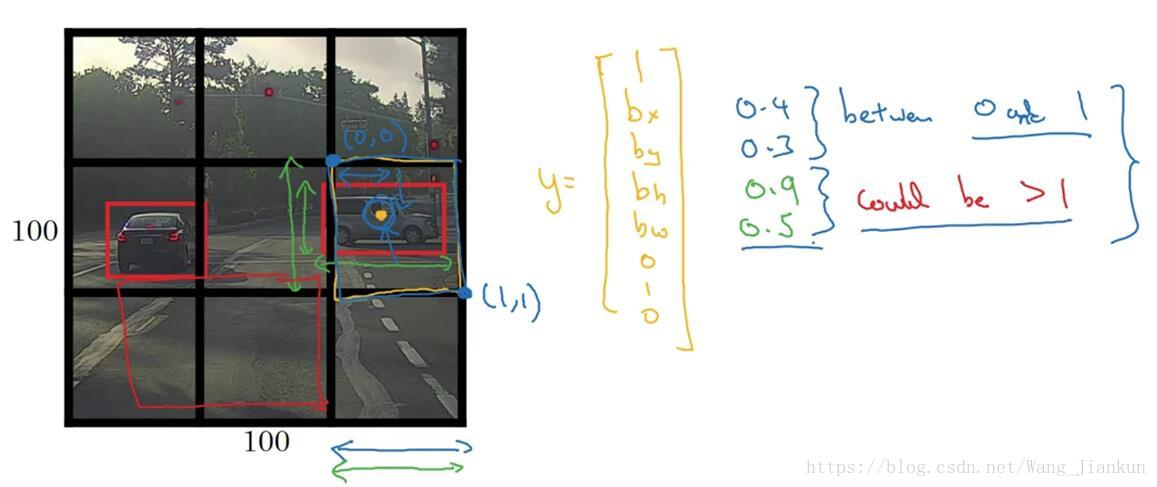
边界框值的意义:
- bx by bh bw :目标的中心点 x、y 坐标和高、宽值。值的大小都是相比于格子尺寸的比例值。
六、交并比(Intersection Over Union)
两个边框:实际边框和预测边框。
IoU = 边框交集 / 边框并集

七、非极大值抑制(Non-max Suppression)
一个目标可能检测出多个边界框,用非极大值抑制解决。

以某一个分类类别为例:
- 丢弃Pc小于一定值的预测结果,通常取0.5。
- 选取Pc最大的边界框,作为一个正确的预测输出。丢弃与该边界框有高交并比(通常取大于0.5)的预测结果。
- 重复上一个步骤,直到所有边界框都被遍历了。

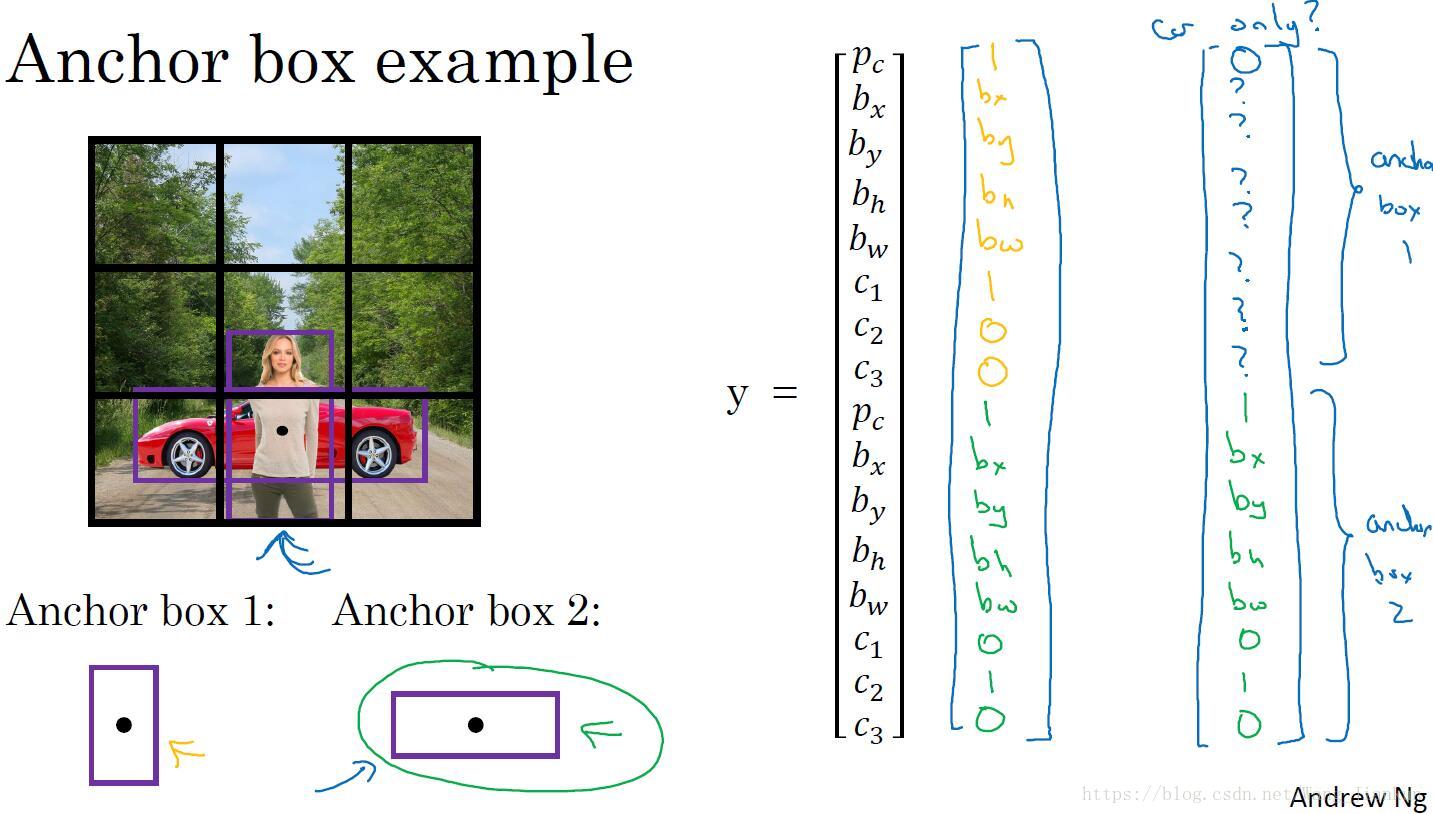
八、Anchor Boxes
解决一个格子只能预测一个目标的不足。
- 人工定义 Anchor Boxes 的形状。标签中对应于 Anchor Boxes 数量设置几个预测标签组合成一个大标签。
- 把目标分配到其边框与某个Anchor Boxe有最大IoU的所属格子的这个Anchor Boxe对应的那一组预测标签中。

九、YOLO Algorithm
训练:
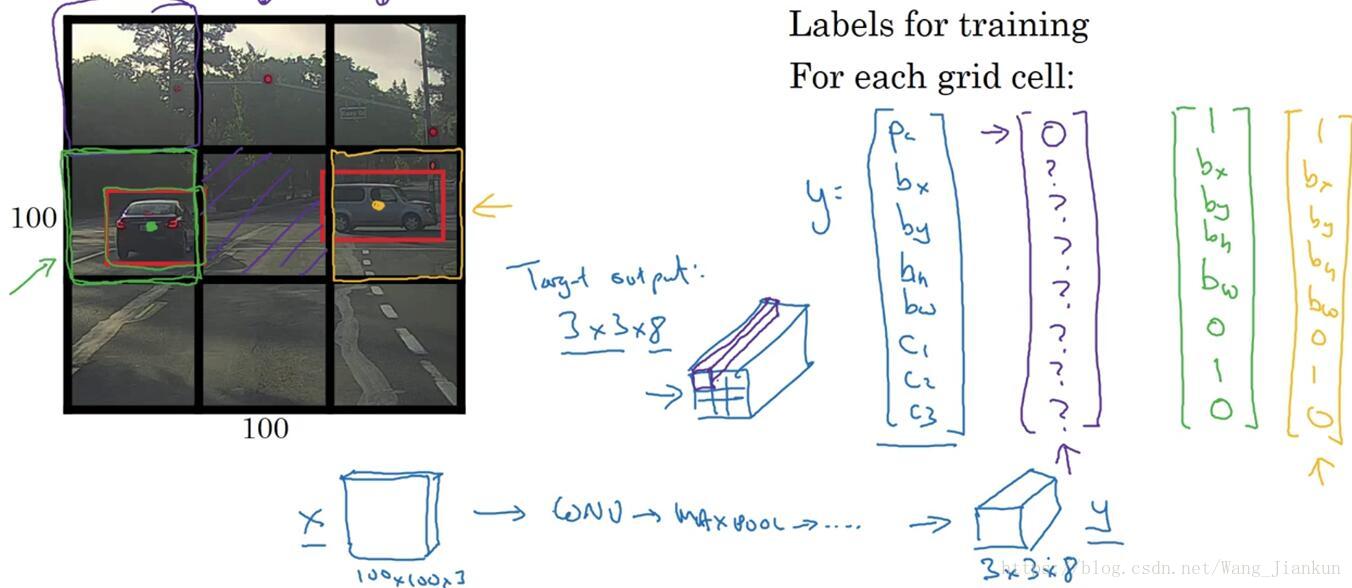
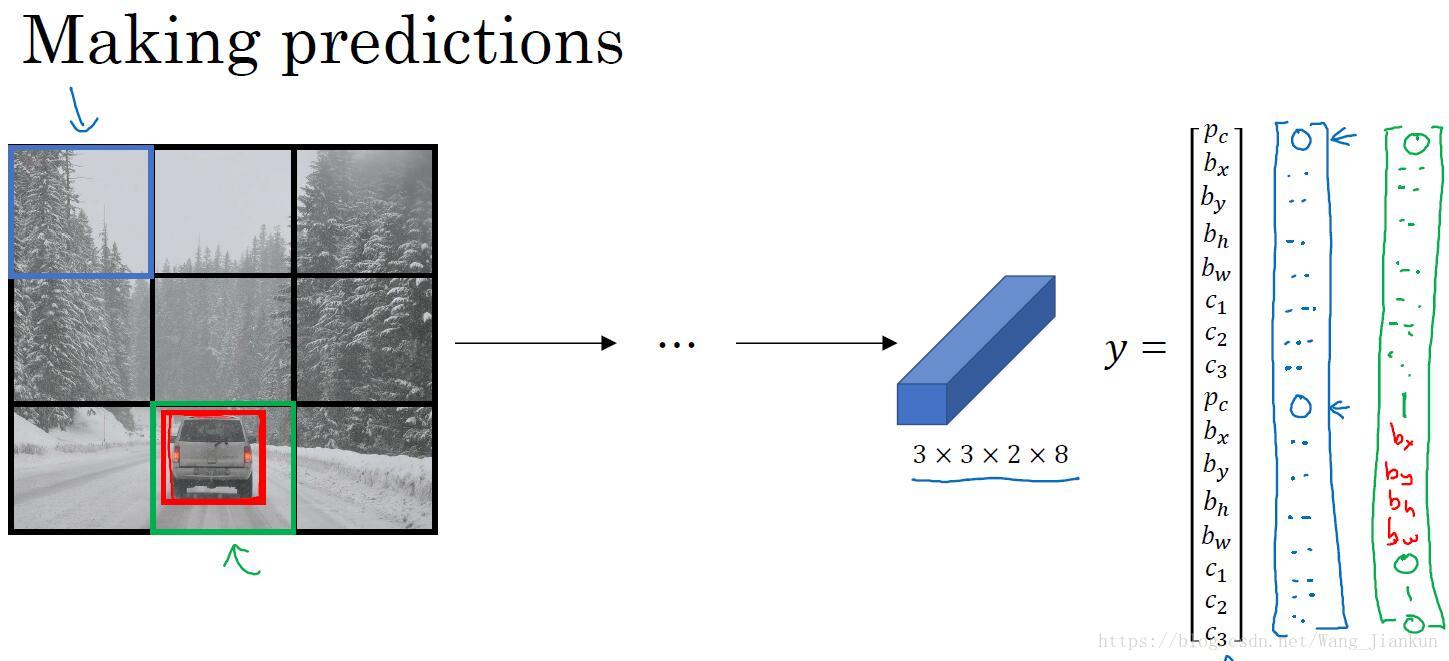
- 划分网格:将图片分割成n×n个小的图片。
- 根据目标的中心点,为每个目标分配一个grid cell :中点在哪个grid cell ,就将该对象分配这个格子中,每个目标只分配给一个格子。
数据标签:对于每个 grid cell 都有一个包含分类和位置的标签yi=[Pc bx by bh bw c1 c2 c3],因为标签的位置值的大小可以是任意值,相比于滑动窗口宽高比不再固定,因此能得到更精确的边框。
node: 这里的yi标签是没有Anchor Boxes的,如果有Anchor Boxes应相应增加值。
- 将 n×n 个格子的标签合并起来,得到 n×n×8 的矩阵标签。
训练模型。
没有Anchor Boxes:
有Anchor Boxes:
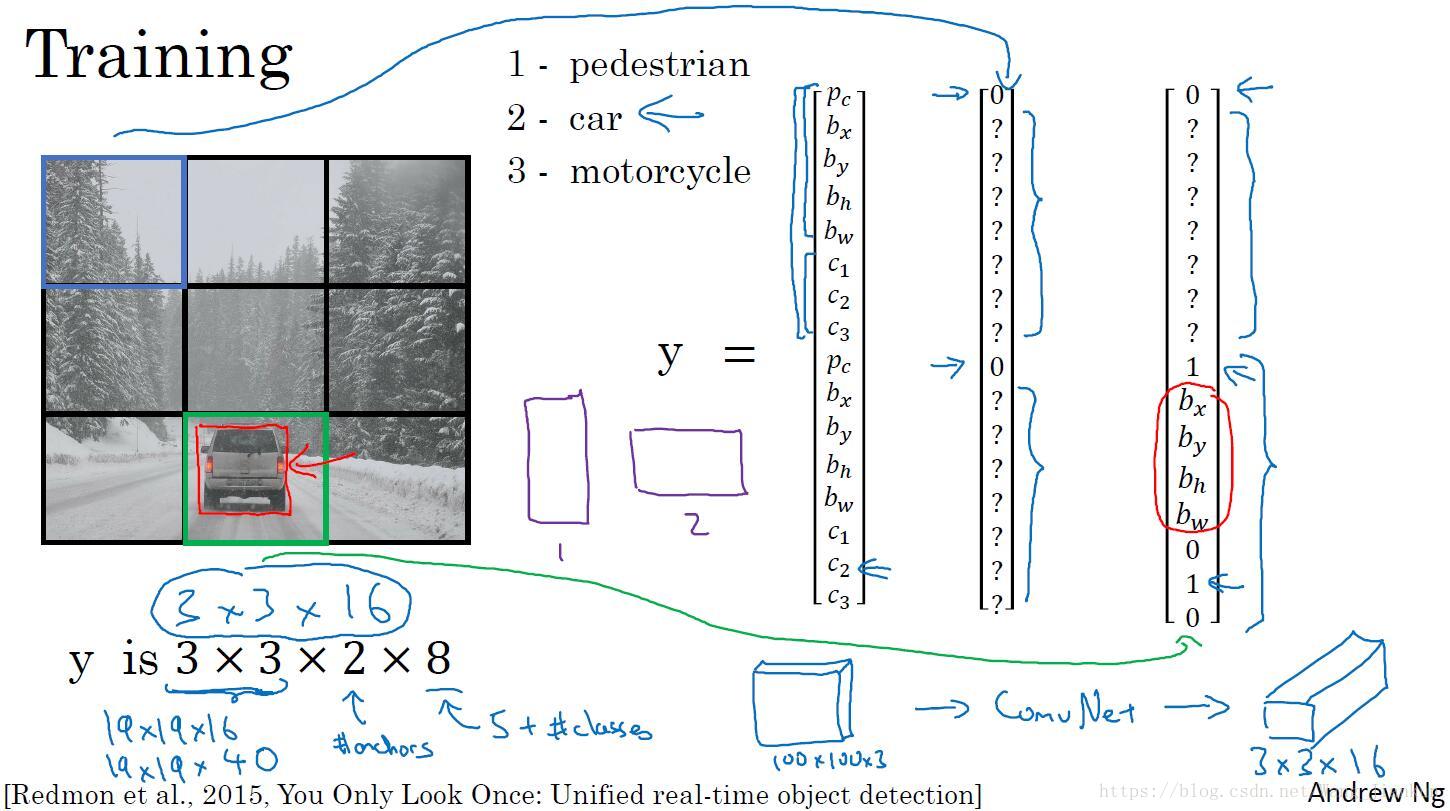
预测:
- 将图片缩放成大小和模型要求一致后输入模型得到大小为n×n×8的预测输出。即可得到分类类别和边框位置。
- YOLO算法对于每张图只进行一次前向传播,算法运行速度快,基本达到实时应用的要求。
非极大值抑制:
- 对每种类别单独进行极大值抑制,输出预测结果。

十、候选区域(Region Proposals)—— R-CNN
- 把图片分割成不同色块,数量要远远小于窗口滑动的子图数。
- 把不同色块的原图输入模型进行预测。并不信任输入色块的位置值,同样要输出边界框的预测值。

