Part 1:Keras tutorial - the Happy House
Welcome to the first assignment of week 2. In this assignment, you will:
- Learn to use Keras, a high-level neural networks API (programming framework), written in Python and capable of running on top of several lower-level frameworks including TensorFlow and CNTK.
- See how you can in a couple of hours build a deep learning algorithm.
Why are we using Keras? Keras was developed to enable deep learning engineers to build and experiment with different models very quickly. Just as TensorFlow is a higher-level framework than Python, Keras is an even higher-level framework and provides additional abstractions. Being able to go from idea to result with the least possible delay is key to finding good models. However, Keras is more restrictive than the lower-level frameworks, so there are some very complex models that you can implement in TensorFlow but not (without more difficulty) in Keras. That being said, Keras will work fine for many common models.
In this exercise, you’ll work on the “Happy House” problem, which we’ll explain below. Let’s load the required packages and solve the problem of the Happy House!
<span style="color:#000000"><code class="language-python"><span style="color:#000088">import</span> numpy <span style="color:#000088">as</span> np
<span style="color:#000088">from</span> keras <span style="color:#000088">import</span> layers
<span style="color:#000088">from</span> keras.layers <span style="color:#000088">import</span> Input, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D
<span style="color:#000088">from</span> keras.layers <span style="color:#000088">import</span> AveragePooling2D, MaxPooling2D, Dropout, GlobalMaxPooling2D, GlobalAveragePooling2D
<span style="color:#000088">from</span> keras.models <span style="color:#000088">import</span> Model
<span style="color:#000088">from</span> keras.preprocessing <span style="color:#000088">import</span> image
<span style="color:#000088">from</span> keras.utils <span style="color:#000088">import</span> layer_utils
<span style="color:#000088">from</span> keras.utils.data_utils <span style="color:#000088">import</span> get_file
<span style="color:#000088">from</span> keras.applications.imagenet_utils <span style="color:#000088">import</span> preprocess_input
<span style="color:#000088">import</span> pydot
<span style="color:#000088">from</span> IPython.display <span style="color:#000088">import</span> SVG
<span style="color:#000088">from</span> keras.utils.vis_utils <span style="color:#000088">import</span> model_to_dot
<span style="color:#000088">from</span> keras.utils <span style="color:#000088">import</span> plot_model
<span style="color:#000088">from</span> kt_utils <span style="color:#000088">import</span> *
<span style="color:#000088">import</span> keras.backend <span style="color:#000088">as</span> K
K.set_image_data_format(<span style="color:#009900">'channels_last'</span>)
<span style="color:#000088">import</span> matplotlib.pyplot <span style="color:#000088">as</span> plt
<span style="color:#000088">from</span> matplotlib.pyplot <span style="color:#000088">import</span> imshow
%matplotlib inline</code></span>You can get the support code and dataset from here.
Note: As you can see, we’ve imported a lot of functions from Keras. You can use them easily just by calling them directly in the notebook. Ex: X = Input(...) or X = ZeroPadding2D(...).
1 - The Happy House
For your next vacation, you decided to spend a week with five of your friends from school. It is a very convenient house with many things to do nearby. But the most important benefit is that everybody has commited to be happy when they are in the house. So anyone wanting to enter the house must prove their current state of happiness.

Figure 1 : the Happy House
As a deep learning expert, to make sure the “Happy” rule is strictly applied, you are going to build an algorithm which that uses pictures from the front door camera to check if the person is happy or not. The door should open only if the person is happy.
You have gathered pictures of your friends and yourself, taken by the front-door camera. The dataset is labbeled.

Run the following code to normalize the dataset and learn about its shapes.
<span style="color:#000000"><code class="language-python">X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
<span style="color:#880000"># Normalize image vectors</span>
X_train = X_train_orig/<span style="color:#006666">255.</span>
X_test = X_test_orig/<span style="color:#006666">255.</span>
<span style="color:#880000"># Reshape</span>
Y_train = Y_train_orig.T
Y_test = Y_test_orig.T
<span style="color:#000088">print</span> (<span style="color:#009900">"number of training examples = "</span> + str(X_train.shape[<span style="color:#006666">0</span>]))
<span style="color:#000088">print</span> (<span style="color:#009900">"number of test examples = "</span> + str(X_test.shape[<span style="color:#006666">0</span>]))
<span style="color:#000088">print</span> (<span style="color:#009900">"X_train shape: "</span> + str(X_train.shape))
<span style="color:#000088">print</span> (<span style="color:#009900">"Y_train shape: "</span> + str(Y_train.shape))
<span style="color:#000088">print</span> (<span style="color:#009900">"X_test shape: "</span> + str(X_test.shape))
<span style="color:#000088">print</span> (<span style="color:#009900">"Y_test shape: "</span> + str(Y_test.shape))</code></span><span style="color:#000000"><code>number of training examples = 600
number of test examples = 150
X_train shape: (600, 64, 64, 3)
Y_train shape: (600, 1)
X_test shape: (150, 64, 64, 3)
Y_test shape: (150, 1)
</code></span>Details of the “Happy” dataset:
- Images are of shape (64,64,3)
- Training: 600 pictures
- Test: 150 pictures
It is now time to solve the “Happy” Challenge.
2 - Building a model in Keras
Keras is very good for rapid prototyping. In just a short time you will be able to build a model that achieves outstanding results.
Here is an example of a model in Keras:
<span style="color:#000000"><code class="language-python"><span style="color:#000088">def</span> <span style="color:#009900">model</span><span style="color:#4f4f4f">(input_shape)</span>:
<span style="color:#880000"># Define the input placeholder as a tensor with shape input_shape. Think of this as your input image!</span>
X_input = Input(input_shape)
<span style="color:#880000"># Zero-Padding: pads the border of X_input with zeroes</span>
X = ZeroPadding2D((<span style="color:#006666">3</span>, <span style="color:#006666">3</span>))(X_input)
<span style="color:#880000"># CONV -> BN -> RELU Block applied to X</span>
X = Conv2D(<span style="color:#006666">32</span>, (<span style="color:#006666">7</span>, <span style="color:#006666">7</span>), strides = (<span style="color:#006666">1</span>, <span style="color:#006666">1</span>), name = <span style="color:#009900">'conv0'</span>)(X)
X = BatchNormalization(axis = <span style="color:#006666">3</span>, name = <span style="color:#009900">'bn0'</span>)(X)
X = Activation(<span style="color:#009900">'relu'</span>)(X)
<span style="color:#880000"># MAXPOOL</span>
X = MaxPooling2D((<span style="color:#006666">2</span>, <span style="color:#006666">2</span>), name=<span style="color:#009900">'max_pool'</span>)(X)
<span style="color:#880000"># FLATTEN X (means convert it to a vector) + FULLYCONNECTED</span>
X = Flatten()(X)
X = Dense(<span style="color:#006666">1</span>, activation=<span style="color:#009900">'sigmoid'</span>, name=<span style="color:#009900">'fc'</span>)(X)
<span style="color:#880000"># Create model. This creates your Keras model instance, you'll use this instance to train/test the model.</span>
model = Model(inputs = X_input, outputs = X, name=<span style="color:#009900">'HappyModel'</span>)
<span style="color:#000088">return</span> model</code></span>Note that Keras uses a different convention with variable names than we’ve previously used with numpy and TensorFlow. In particular, rather than creating and assigning a new variable on each step of forward propagation such as X, Z1, A1, Z2, A2, etc. for the computations for the different layers, in Keras code each line above just reassigns X to a new value using X = .... In other words, during each step of forward propagation, we are just writing the latest value in the commputation into the same variable X. The only exception was X_input, which we kept separate and did not overwrite, since we needed it at the end to create the Keras model instance (model = Model(inputs = X_input, ...) above).
Exercise: Implement a HappyModel(). This assignment is more open-ended than most. We suggest that you start by implementing a model using the architecture we suggest, and run through the rest of this assignment using that as your initial model. But after that, come back and take initiative to try out other model architectures. For example, you might take inspiration from the model above, but then vary the network architecture and hyperparameters however you wish. You can also use other functions such as AveragePooling2D(), GlobalMaxPooling2D(), Dropout().
Note: You have to be careful with your data’s shapes. Use what you’ve learned in the videos to make sure your convolutional, pooling and fully-connected layers are adapted to the volumes you’re applying it to.
<span style="color:#000000"><code class="language-python"><span style="color:#880000"># GRADED FUNCTION: HappyModel</span>
<span style="color:#000088">def</span> <span style="color:#009900">HappyModel</span><span style="color:#4f4f4f">(input_shape)</span>:
<span style="color:#009900">"""
Implementation of the HappyModel.
Arguments:
input_shape -- shape of the images of the dataset
Returns:
model -- a Model() instance in Keras
"""</span>
<span style="color:#880000">### START CODE HERE ###</span>
<span style="color:#880000"># Feel free to use the suggested outline in the text above to get started, and run through the whole</span>
<span style="color:#880000"># exercise (including the later portions of this notebook) once. The come back also try out other</span>
<span style="color:#880000"># network architectures as well. </span>
<span style="color:#880000"># Define the input placeholder as a tensor with shape input_shape. Think of this as your input image!</span>
X_input = Input(input_shape)
<span style="color:#880000"># Zero-Padding: pads the border of X_input with zeroes</span>
X = ZeroPadding2D((<span style="color:#006666">3</span>, <span style="color:#006666">3</span>))(X_input)
<span style="color:#880000"># CONV -> BN -> RELU Block applied to X</span>
X = Conv2D(<span style="color:#006666">32</span>, (<span style="color:#006666">7</span>, <span style="color:#006666">7</span>), strides = (<span style="color:#006666">1</span>, <span style="color:#006666">1</span>), name = <span style="color:#009900">'conv0'</span>)(X)
X = BatchNormalization(axis = <span style="color:#006666">3</span>, name = <span style="color:#009900">'bn0'</span>)(X)
X = Activation(<span style="color:#009900">'relu'</span>)(X)
<span style="color:#880000"># MAXPOOL</span>
X = MaxPooling2D((<span style="color:#006666">2</span>, <span style="color:#006666">2</span>), name=<span style="color:#009900">'max_pool'</span>)(X)
<span style="color:#880000"># FLATTEN X (means convert it to a vector) + FULLYCONNECTED</span>
X = Flatten()(X)
X = Dense(<span style="color:#006666">1</span>, activation=<span style="color:#009900">'sigmoid'</span>, name=<span style="color:#009900">'fc'</span>)(X)
<span style="color:#880000"># Create model. This creates your Keras model instance, you'll use this instance to train/test the model.</span>
model = Model(inputs = X_input, outputs = X, name=<span style="color:#009900">'HappyModel'</span>)
<span style="color:#880000">### END CODE HERE ###</span>
<span style="color:#000088">return</span> model</code></span>You have now built a function to describe your model. To train and test this model, there are four steps in Keras:
1. Create the model by calling the function above
2. Compile the model by calling model.compile(optimizer = "...", loss = "...", metrics = ["accuracy"])
3. Train the model on train data by calling model.fit(x = ..., y = ..., epochs = ..., batch_size = ...)
4. Test the model on test data by calling model.evaluate(x = ..., y = ...)
If you want to know more about model.compile(), model.fit(), model.evaluate() and their arguments, refer to the official Keras documentation.
Exercise: Implement step 1, i.e. create the model.
<span style="color:#000000"><code class="language-python"><span style="color:#880000">### START CODE HERE ### (1 line)</span>
happyModel = HappyModel(X_train.shape[<span style="color:#006666">1</span>:])
<span style="color:#880000">### END CODE HERE ###</span></code></span>Exercise: Implement step 2, i.e. compile the model to configure the learning process. Choose the 3 arguments of compile() wisely. Hint: the Happy Challenge is a binary classification problem.
<span style="color:#000000"><code class="language-python"><span style="color:#880000">### START CODE HERE ### (1 line)</span>
happyModel.compile(optimizer = <span style="color:#009900">"Adam"</span>, loss = <span style="color:#009900">"binary_crossentropy"</span>, metrics = [<span style="color:#009900">"accuracy"</span>])
<span style="color:#880000">### END CODE HERE ###</span></code></span>Exercise: Implement step 3, i.e. train the model. Choose the number of epochs and the batch size.
<span style="color:#000000"><code class="language-python"><span style="color:#880000">### START CODE HERE ### (1 line)</span>
happyModel.fit(x = X_train, y = Y_train, epochs = <span style="color:#006666">10</span>, batch_size = <span style="color:#006666">32</span>)
<span style="color:#880000">### END CODE HERE ###</span></code></span><span style="color:#000000"><code>Epoch 1/10
600/600 [==============================] - 12s - loss: 2.3311 - acc: 0.5567
Epoch 2/10
600/600 [==============================] - 12s - loss: 0.6309 - acc: 0.7733
Epoch 3/10
600/600 [==============================] - 13s - loss: 0.2546 - acc: 0.8883
Epoch 4/10
600/600 [==============================] - 14s - loss: 0.1593 - acc: 0.9467
Epoch 5/10
600/600 [==============================] - 14s - loss: 0.1358 - acc: 0.9517
Epoch 6/10
600/600 [==============================] - 14s - loss: 0.1558 - acc: 0.9367
Epoch 7/10
600/600 [==============================] - 14s - loss: 0.1704 - acc: 0.9367
Epoch 8/10
600/600 [==============================] - 14s - loss: 0.0987 - acc: 0.9667
Epoch 9/10
600/600 [==============================] - 14s - loss: 0.0860 - acc: 0.9767
Epoch 10/10
600/600 [==============================] - 14s - loss: 0.0726 - acc: 0.9767
<keras.callbacks.History at 0x7f48536bb4e0>
</code></span>Note that if you run fit() again, the model will continue to train with the parameters it has already learnt instead of reinitializing them.
Exercise: Implement step 4, i.e. test/evaluate the model.
<span style="color:#000000"><code class="language-python"><span style="color:#880000">### START CODE HERE ### (1 line)</span>
preds = happyModel.evaluate(X_test, Y_test)
<span style="color:#880000">### END CODE HERE ###</span>
print()
<span style="color:#000088">print</span> (<span style="color:#009900">"Loss = "</span> + str(preds[<span style="color:#006666">0</span>]))
<span style="color:#000088">print</span> (<span style="color:#009900">"Test Accuracy = "</span> + str(preds[<span style="color:#006666">1</span>]))</code></span><span style="color:#000000"><code>150/150 [==============================] - 1s
Loss = 0.254035257101
Test Accuracy = 0.933333337307
</code></span>If your happyModel() function worked, you should have observed much better than random-guessing (50%) accuracy on the train and test sets.
To give you a point of comparison, our model gets around 95% test accuracy in 40 epochs (and 99% train accuracy) with a mini batch size of 16 and “adam” optimizer. But our model gets decent accuracy after just 2-5 epochs, so if you’re comparing different models you can also train a variety of models on just a few epochs and see how they compare.
If you have not yet achieved a very good accuracy (let’s say more than 80%), here’re some things you can play around with to try to achieve it:
- Try using blocks of CONV->BATCHNORM->RELU such as:
<span style="color:#000000"><code class="language-python">X = Conv2D(<span style="color:#006666">32</span>, (<span style="color:#006666">3</span>, <span style="color:#006666">3</span>), strides = (<span style="color:#006666">1</span>, <span style="color:#006666">1</span>), name = <span style="color:#009900">'conv0'</span>)(X)
X = BatchNormalization(axis = <span style="color:#006666">3</span>, name = <span style="color:#009900">'bn0'</span>)(X)
X = Activation(<span style="color:#009900">'relu'</span>)(X)</code></span>until your height and width dimensions are quite low and your number of channels quite large (≈32 for example). You are encoding useful information in a volume with a lot of channels. You can then flatten the volume and use a fully-connected layer.
- You can use MAXPOOL after such blocks. It will help you lower the dimension in height and width.
- Change your optimizer. We find Adam works well.
- If the model is struggling to run and you get memory issues, lower your batch_size (12 is usually a good compromise)
- Run on more epochs, until you see the train accuracy plateauing.
Even if you have achieved a good accuracy, please feel free to keep playing with your model to try to get even better results.
Note: If you perform hyperparameter tuning on your model, the test set actually becomes a dev set, and your model might end up overfitting to the test (dev) set. But just for the purpose of this assignment, we won’t worry about that here.
3 - Conclusion
Congratulations, you have solved the Happy House challenge!
Now, you just need to link this model to the front-door camera of your house. We unfortunately won’t go into the details of how to do that here.
What we would like you to remember from this assignment:
- Keras is a tool we recommend for rapid prototyping. It allows you to quickly try out different model architectures. Are there any applications of deep learning to your daily life that you’d like to implement using Keras?
- Remember how to code a model in Keras and the four steps leading to the evaluation of your model on the test set. Create->Compile->Fit/Train->Evaluate/Test.
4 - Test with your own image (Optional)
Congratulations on finishing this assignment. You can now take a picture of your face and see if you could enter the Happy House. To do that:
1. Click on “File” in the upper bar of this notebook, then click “Open” to go on your Coursera Hub.
2. Add your image to this Jupyter Notebook’s directory, in the “images” folder
3. Write your image’s name in the following code
4. Run the code and check if the algorithm is right (0 is unhappy, 1 is happy)!
The training/test sets were quite similar; for example, all the pictures were taken against the same background (since a front door camera is always mounted in the same position). This makes the problem easier, but a model trained on this data may or may not work on your own data. But feel free to give it a try!
<span style="color:#000000"><code class="language-python"><span style="color:#880000">### START CODE HERE ###</span>
img_path = <span style="color:#009900">'images/my_image.jpg'</span>
<span style="color:#880000">### END CODE HERE ###</span>
img = image.load_img(img_path, target_size=(<span style="color:#006666">64</span>, <span style="color:#006666">64</span>))
imshow(img)
x = image.img_to_array(img)
x = np.expand_dims(x, axis=<span style="color:#006666">0</span>)
x = preprocess_input(x)
print(happyModel.predict(x))</code></span><span style="color:#000000"><code>[[ 0.]]
</code></span>

5 - Other useful functions in Keras (Optional)
Two other basic features of Keras that you’ll find useful are:
- model.summary(): prints the details of your layers in a table with the sizes of its inputs/outputs
- plot_model(): plots your graph in a nice layout. You can even save it as “.png” using SVG() if you’d like to share it on social media ;). It is saved in “File” then “Open…” in the upper bar of the notebook.
Run the following code.
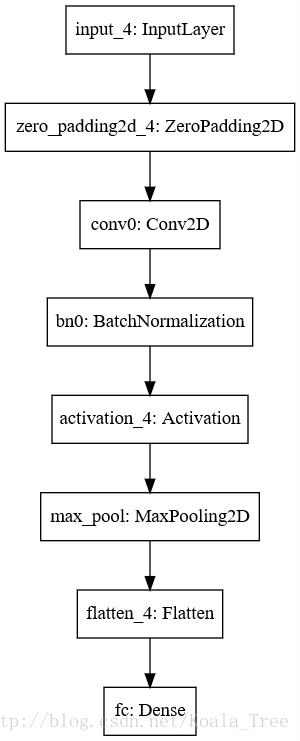
<span style="color:#000000"><code class="language-python">happyModel.summary()</code></span><span style="color:#000000"><code>_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) (None, 64, 64, 3) 0
_________________________________________________________________
zero_padding2d_4 (ZeroPaddin (None, 70, 70, 3) 0
_________________________________________________________________
conv0 (Conv2D) (None, 64, 64, 32) 4736
_________________________________________________________________
bn0 (BatchNormalization) (None, 64, 64, 32) 128
_________________________________________________________________
activation_4 (Activation) (None, 64, 64, 32) 0
_________________________________________________________________
max_pool (MaxPooling2D) (None, 32, 32, 32) 0
_________________________________________________________________
flatten_4 (Flatten) (None, 32768) 0
_________________________________________________________________
fc (Dense) (None, 1) 32769
=================================================================
Total params: 37,633
Trainable params: 37,569
Non-trainable params: 64
_________________________________________________________________
</code></span><span style="color:#000000"><code class="language-python">plot_model(happyModel, to_file=<span style="color:#009900">'HappyModel.png'</span>)
SVG(model_to_dot(happyModel).create(prog=<span style="color:#009900">'dot'</span>, format=<span style="color:#009900">'svg'</span>))</code></span>
Part 2:Residual Networks
Welcome to the second assignment of this week! You will learn how to build very deep convolutional networks, using Residual Networks (ResNets). In theory, very deep networks can represent very complex functions; but in practice, they are hard to train. Residual Networks, introduced by He et al., allow you to train much deeper networks than were previously practically feasible.
In this assignment, you will:
- Implement the basic building blocks of ResNets.
- Put together these building blocks to implement and train a state-of-the-art neural network for image classification.
This assignment will be done in Keras.
Before jumping into the problem, let’s run the cell below to load the required packages.
<span style="color:#000000"><code class="language-python"><span style="color:#000088">import</span> numpy <span style="color:#000088">as</span> np
<span style="color:#000088">from</span> keras <span style="color:#000088">import</span> layers
<span style="color:#000088">from</span> keras.layers <span style="color:#000088">import</span> Input, Add, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D, GlobalMaxPooling2D
<span style="color:#000088">from</span> keras.models <span style="color:#000088">import</span> Model, load_model
<span style="color:#000088">from</span> keras.preprocessing <span style="color:#000088">import</span> image
<span style="color:#000088">from</span> keras.utils <span style="color:#000088">import</span> layer_utils
<span style="color:#000088">from</span> keras.utils.data_utils <span style="color:#000088">import</span> get_file
<span style="color:#000088">from</span> keras.applications.imagenet_utils <span style="color:#000088">import</span> preprocess_input
<span style="color:#000088">import</span> pydot
<span style="color:#000088">from</span> IPython.display <span style="color:#000088">import</span> SVG
<span style="color:#000088">from</span> keras.utils.vis_utils <span style="color:#000088">import</span> model_to_dot
<span style="color:#000088">from</span> keras.utils <span style="color:#000088">import</span> plot_model
<span style="color:#000088">from</span> resnets_utils <span style="color:#000088">import</span> *
<span style="color:#000088">from</span> keras.initializers <span style="color:#000088">import</span> glorot_uniform
<span style="color:#000088">import</span> scipy.misc
<span style="color:#000088">from</span> matplotlib.pyplot <span style="color:#000088">import</span> imshow
%matplotlib inline
<span style="color:#000088">import</span> keras.backend <span style="color:#000088">as</span> K
K.set_image_data_format(<span style="color:#009900">'channels_last'</span>)
K.set_learning_phase(<span style="color:#006666">1</span>)</code></span>You can get the support code and dataset from here.
1 - The problem of very deep neural networks
Last week, you built your first convolutional neural network. In recent years, neural networks have become deeper, with state-of-the-art networks going from just a few layers (e.g., AlexNet) to over a hundred layers.
The main benefit of a very deep network is that it can represent very complex functions. It can also learn features at many different levels of abstraction, from edges (at the lower layers) to very complex features (at the deeper layers). However, using a deeper network doesn’t always help. A huge barrier to training them is vanishing gradients: very deep networks often have a gradient signal that goes to zero quickly, thus making gradient descent unbearably slow. More specifically, during gradient descent, as you backprop from the final layer back to the first layer, you are multiplying by the weight matrix on each step, and thus the gradient can decrease exponentially quickly to zero (or, in rare cases, grow exponentially quickly and “explode” to take very large values).
During training, you might therefore see the magnitude (or norm) of the gradient for the earlier layers descrease to zero very rapidly as training proceeds:
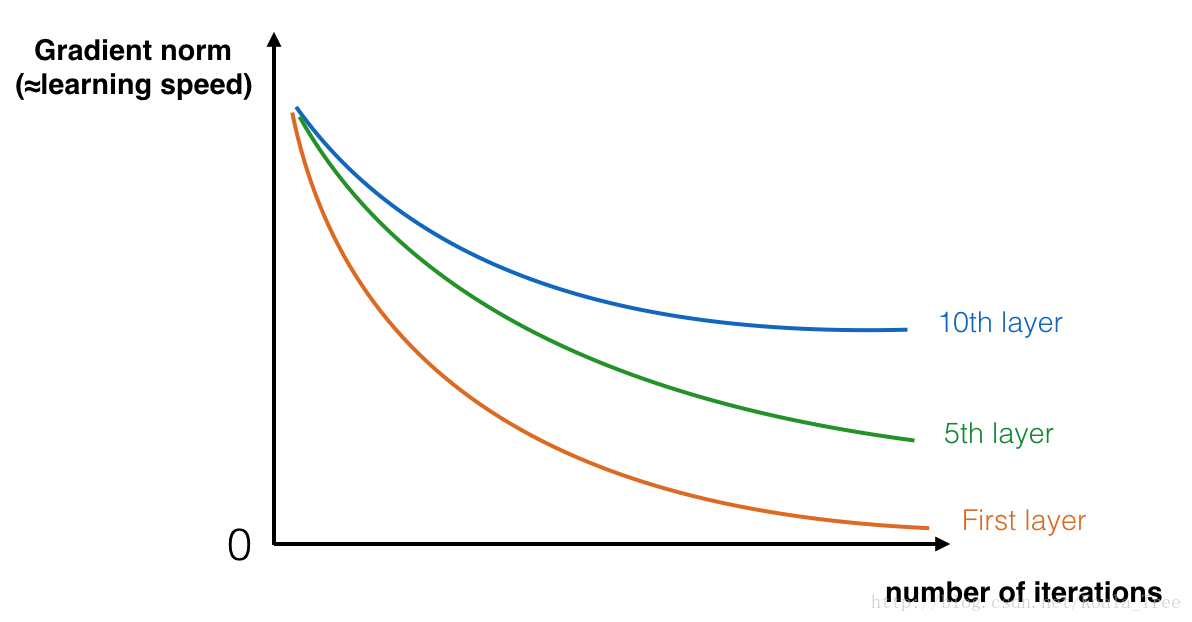
Figure 1 : Vanishing gradient
The speed of learning decreases very rapidly for the early layers as the network trains
You are now going to solve this problem by building a Residual Network!
2 - Building a Residual Network
In ResNets, a “shortcut” or a “skip connection” allows the gradient to be directly backpropagated to earlier layers:

Figure 2 : A ResNet block showing a skip-connection
The image on the left shows the “main path” through the network. The image on the right adds a shortcut to the main path. By stacking these ResNet blocks on top of each other, you can form a very deep network.
We also saw in lecture that having ResNet blocks with the shortcut also makes it very easy for one of the blocks to learn an identity function. This means that you can stack on additional ResNet blocks with little risk of harming training set performance. (There is also some evidence that the ease of learning an identity function–even more than skip connections helping with vanishing gradients–accounts for ResNets’ remarkable performance.)
Two main types of blocks are used in a ResNet, depending mainly on whether the input/output dimensions are same or different. You are going to implement both of them.
2.1 - The identity block
The identity block is the standard block used in ResNets, and corresponds to the case where the input activation (say a[l]a[l]) has the same dimension as the output activation (say a[l+2]a[l+2]). To flesh out the different steps of what happens in a ResNet’s identity block, here is an alternative diagram showing the individual steps:
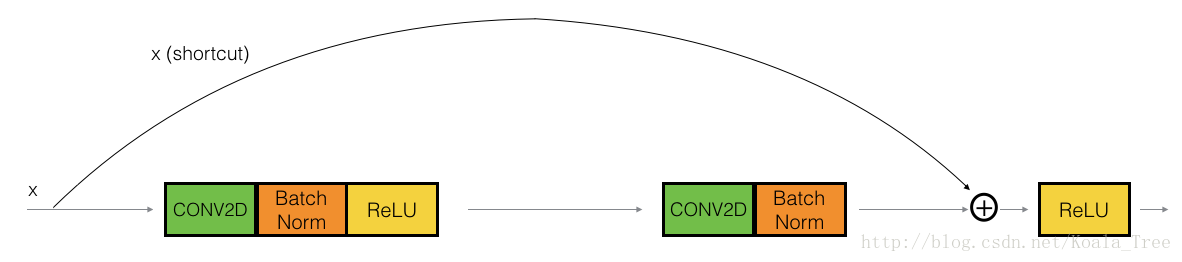
Figure 3 : Identity block. Skip connection “skips over” 2 layers.
The upper path is the “shortcut path.” The lower path is the “main path.” In this diagram, we have also made explicit the CONV2D and ReLU steps in each layer. To speed up training we have also added a BatchNorm step. Don’t worry about this being complicated to implement–you’ll see that BatchNorm is just one line of code in Keras!
In this exercise, you’ll actually implement a slightly more powerful version of this identity block, in which the skip connection “skips over” 3 hidden layers rather than 2 layers. It looks like this:
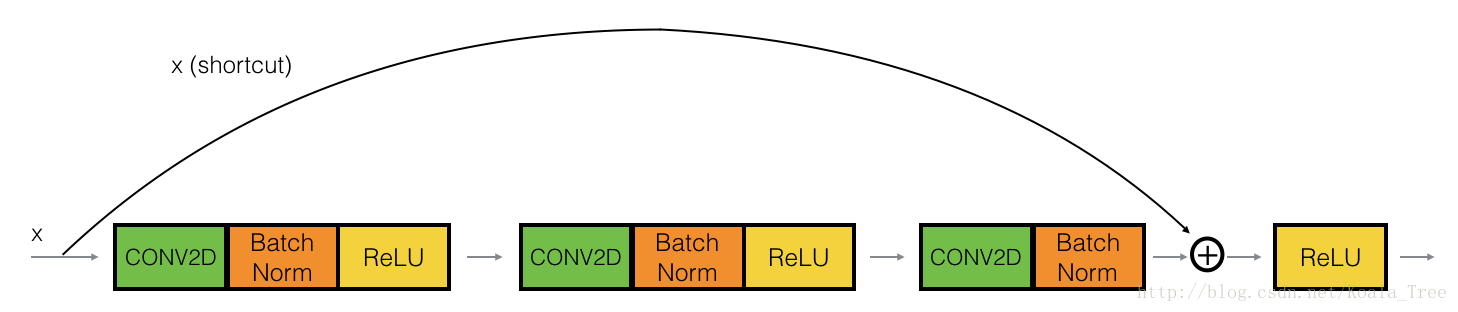
Figure 4 : Identity block. Skip connection “skips over” 3 layers.
Here’re the individual steps.
First component of main path:
- The first CONV2D has F1F1 filters of shape (1,1) and a stride of (1,1). Its padding is “valid” and its name should be conv_name_base + '2a'. Use 0 as the seed for the random initialization.
- The first BatchNorm is normalizing the channels axis. Its name should be bn_name_base + '2a'.
- Then apply the ReLU activation function. This has no name and no hyperparameters.
Second component of main path:
- The second CONV2D has F2F2 filters of shape (f,f)(f,f) and a stride of (1,1). Its padding is “same” and its name should be conv_name_base + '2b'. Use 0 as the seed for the random initialization.
- The second BatchNorm is normalizing the channels axis. Its name should be bn_name_base + '2b'.
- Then apply the ReLU activation function. This has no name and no hyperparameters.
Third component of main path:
- The third CONV2D has F3F3 filters of shape (1,1) and a stride of (1,1). Its padding is “valid” and its name should be conv_name_base + '2c'. Use 0 as the seed for the random initialization.
- The third BatchNorm is normalizing the channels axis. Its name should be bn_name_base + '2c'. Note that there is no ReLU activation function in this component.
Final step:
- The shortcut and the input are added together.
- Then apply the ReLU activation function. This has no name and no hyperparameters.
Exercise: Implement the ResNet identity block. We have implemented the first component of the main path. Please read over this carefully to make sure you understand what it is doing. You should implement the rest.
- To implement the Conv2D step: See reference
- To implement BatchNorm: See reference (axis: Integer, the axis that should be normalized (typically the channels axis))
- For the activation, use: Activation('relu')(X)
- To add the value passed forward by the shortcut: See reference
<span style="color:#000000"><code class="language-python"><span style="color:#880000"># GRADED FUNCTION: identity_block</span>
<span style="color:#000088">def</span> <span style="color:#009900">identity_block</span><span style="color:#4f4f4f">(X, f, filters, stage, block)</span>:
<span style="color:#009900">"""
Implementation of the identity block as defined in Figure 3
Arguments:
X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev)
f -- integer, specifying the shape of the middle CONV's window for the main path
filters -- python list of integers, defining the number of filters in the CONV layers of the main path
stage -- integer, used to name the layers, depending on their position in the network
block -- string/character, used to name the layers, depending on their position in the network
Returns:
X -- output of the identity block, tensor of shape (n_H, n_W, n_C)
"""</span>
<span style="color:#880000"># defining name basis</span>
conv_name_base = <span style="color:#009900">'res'</span> + str(stage) + block + <span style="color:#009900">'_branch'</span>
bn_name_base = <span style="color:#009900">'bn'</span> + str(stage) + block + <span style="color:#009900">'_branch'</span>
<span style="color:#880000"># Retrieve Filters</span>
F1, F2, F3 = filters
<span style="color:#880000"># Save the input value. You'll need this later to add back to the main path. </span>
X_shortcut = X
<span style="color:#880000"># First component of main path</span>
X = Conv2D(filters = F1, kernel_size = (<span style="color:#006666">1</span>, <span style="color:#006666">1</span>), strides = (<span style="color:#006666">1</span>,<span style="color:#006666">1</span>), padding = <span style="color:#009900">'valid'</span>, name = conv_name_base + <span style="color:#009900">'2a'</span>, kernel_initializer = glorot_uniform(seed=<span style="color:#006666">0</span>))(X)
X = BatchNormalization(axis = <span style="color:#006666">3</span>, name = bn_name_base + <span style="color:#009900">'2a'</span>)(X)
X = Activation(<span style="color:#009900">'relu'</span>)(X)
<span style="color:#880000">### START CODE HERE ###</span>
<span style="color:#880000"># Second component of main path (≈3 lines)</span>
X = Conv2D(filters = F2, kernel_size = (f, f), strides = (<span style="color:#006666">1</span>,<span style="color:#006666">1</span>), padding = <span style="color:#009900">'same'</span>, name = conv_name_base + <span style="color:#009900">'2b'</span>, kernel_initializer = glorot_uniform(seed=<span style="color:#006666">0</span>))(X)
X = BatchNormalization(axis = <span style="color:#006666">3</span>, name = bn_name_base + <span style="color:#009900">'2b'</span>)(X)
X = Activation(<span style="color:#009900">'relu'</span>)(X)
<span style="color:#880000"># Third component of main path (≈2 lines)</span>
X = Conv2D(filters = F3, kernel_size = (<span style="color:#006666">1</span>, <span style="color:#006666">1</span>), strides = (<span style="color:#006666">1</span>,<span style="color:#006666">1</span>), padding = <span style="color:#009900">'valid'</span>, name = conv_name_base + <span style="color:#009900">'2c'</span>, kernel_initializer = glorot_uniform(seed=<span style="color:#006666">0</span>))(X)
X = BatchNormalization(axis = <span style="color:#006666">3</span>, name = bn_name_base + <span style="color:#009900">'2c'</span>)(X)
<span style="color:#880000"># Final step: Add shortcut value to main path, and pass it through a RELU activation (≈2 lines)</span>
X = Add()([X, X_shortcut])
X = Activation(<span style="color:#009900">'relu'</span>)(X)
<span style="color:#880000">### END CODE HERE ###</span>
<span style="color:#000088">return</span> X</code></span><span style="color:#000000"><code class="language-python">tf.reset_default_graph()
<span style="color:#000088">with</span> tf.Session() <span style="color:#000088">as</span> test:
np.random.seed(<span style="color:#006666">1</span>)
A_prev = tf.placeholder(<span style="color:#009900">"float"</span>, [<span style="color:#006666">3</span>, <span style="color:#006666">4</span>, <span style="color:#006666">4</span>, <span style="color:#006666">6</span>])
X = np.random.randn(<span style="color:#006666">3</span>, <span style="color:#006666">4</span>, <span style="color:#006666">4</span>, <span style="color:#006666">6</span>)
A = identity_block(A_prev, f = <span style="color:#006666">2</span>, filters = [<span style="color:#006666">2</span>, <span style="color:#006666">4</span>, <span style="color:#006666">6</span>], stage = <span style="color:#006666">1</span>, block = <span style="color:#009900">'a'</span>)
test.run(tf.global_variables_initializer())
out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): <span style="color:#006666">0</span>})
print(<span style="color:#009900">"out = "</span> + str(out[<span style="color:#006666">0</span>][<span style="color:#006666">1</span>][<span style="color:#006666">1</span>][<span style="color:#006666">0</span>]))</code></span><span style="color:#000000"><code>out = [ 0.94822985 0. 1.16101444 2.747859 0. 1.36677003]
</code></span>2.2 - The convolutional block
You’ve implemented the ResNet identity block. Next, the ResNet “convolutional block” is the other type of block. You can use this type of block when the input and output dimensions don’t match up. The difference with the identity block is that there is a CONV2D layer in the shortcut path:
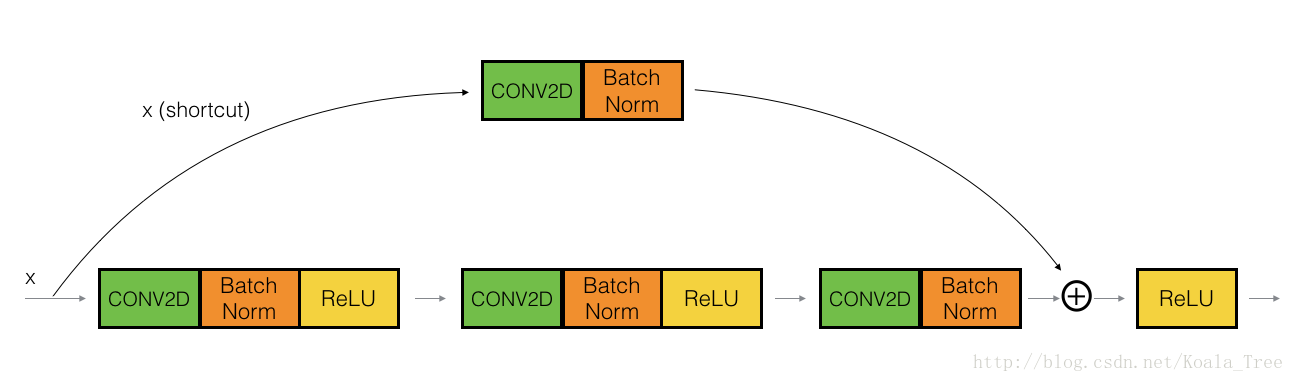
Figure 4 : Convolutional block
The CONV2D layer in the shortcut path is used to resize the input xx to a different dimension, so that the dimensions match up in the final addition needed to add the shortcut value back to the main path. (This plays a similar role as the matrix WsWs discussed in lecture.) For example, to reduce the activation dimensions’s height and width by a factor of 2, you can use a 1x1 convolution with a stride of 2. The CONV2D layer on the shortcut path does not use any non-linear activation function. Its main role is to just apply a (learned) linear function that reduces the dimension of the input, so that the dimensions match up for the later addition step.
The details of the convolutional block are as follows.
First component of main path:
- The first CONV2D has F1F1 filters of shape (1,1) and a stride of (s,s). Its padding is “valid” and its name should be conv_name_base + '2a'.
- The first BatchNorm is normalizing the channels axis. Its name should be bn_name_base + '2a'.
- Then apply the ReLU activation function. This has no name and no hyperparameters.
Second component of main path:
- The second CONV2D has F2F2 filters of (f,f) and a stride of (1,1). Its padding is “same” and it’s name should be conv_name_base + '2b'.
- The second BatchNorm is normalizing the channels axis. Its name should be bn_name_base + '2b'.
- Then apply the ReLU activation function. This has no name and no hyperparameters.
Third component of main path:
- The third CONV2D has F3F3 filters of (1,1) and a stride of (1,1). Its padding is “valid” and it’s name should be conv_name_base + '2c'.
- The third BatchNorm is normalizing the channels axis. Its name should be bn_name_base + '2c'. Note that there is no ReLU activation function in this component.
Shortcut path:
- The CONV2D has F3F3 filters of shape (1,1) and a stride of (s,s). Its padding is “valid” and its name should be conv_name_base + '1'.
- The BatchNorm is normalizing the channels axis. Its name should be bn_name_base + '1'.
Final step:
- The shortcut and the main path values are added together.
- Then apply the ReLU activation function. This has no name and no hyperparameters.
Exercise: Implement the convolutional block. We have implemented the first component of the main path; you should implement the rest. As before, always use 0 as the seed for the random initialization, to ensure consistency with our grader.
- Conv Hint
- BatchNorm Hint (axis: Integer, the axis that should be normalized (typically the features axis))
- For the activation, use: Activation('relu')(X)
- Addition Hint
<span style="color:#000000"><code class="language-python"><span style="color:#880000"># GRADED FUNCTION: convolutional_block</span>
<span style="color:#000088">def</span> <span style="color:#009900">convolutional_block</span><span style="color:#4f4f4f">(X, f, filters, stage, block, s = <span style="color:#006666">2</span>)</span>:
<span style="color:#009900">"""
Implementation of the convolutional block as defined in Figure 4
Arguments:
X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev)
f -- integer, specifying the shape of the middle CONV's window for the main path
filters -- python list of integers, defining the number of filters in the CONV layers of the main path
stage -- integer, used to name the layers, depending on their position in the network
block -- string/character, used to name the layers, depending on their position in the network
s -- Integer, specifying the stride to be used
Returns:
X -- output of the convolutional block, tensor of shape (n_H, n_W, n_C)
"""</span>
<span style="color:#880000"># defining name basis</span>
conv_name_base = <span style="color:#009900">'res'</span> + str(stage) + block + <span style="color:#009900">'_branch'</span>
bn_name_base = <span style="color:#009900">'bn'</span> + str(stage) + block + <span style="color:#009900">'_branch'</span>
<span style="color:#880000"># Retrieve Filters</span>
F1, F2, F3 = filters
<span style="color:#880000"># Save the input value</span>
X_shortcut = X
<span style="color:#880000">##### MAIN PATH #####</span>
<span style="color:#880000"># First component of main path </span>
X = Conv2D(F1, (<span style="color:#006666">1</span>, <span style="color:#006666">1</span>), strides = (s,s), name = conv_name_base + <span style="color:#009900">'2a'</span>, kernel_initializer = glorot_uniform(seed=<span style="color:#006666">0</span>))(X)
X = BatchNormalization(axis = <span style="color:#006666">3</span>, name = bn_name_base + <span style="color:#009900">'2a'</span>)(X)
X = Activation(<span style="color:#009900">'relu'</span>)(X)
<span style="color:#880000">### START CODE HERE ###</span>
<span style="color:#880000"># Second component of main path (≈3 lines)</span>
X = Conv2D(F2, (f, f), strides = (<span style="color:#006666">1</span>,<span style="color:#006666">1</span>), name = conv_name_base + <span style="color:#009900">'2b'</span>, padding = <span style="color:#009900">'same'</span>, kernel_initializer = glorot_uniform(seed=<span style="color:#006666">0</span>))(X)
X = BatchNormalization(axis = <span style="color:#006666">3</span>, name = bn_name_base + <span style="color:#009900">'2b'</span>)(X)
X = Activation(<span style="color:#009900">'relu'</span>)(X)
<span style="color:#880000"># Third component of main path (≈2 lines)</span>
X = Conv2D(F3, (<span style="color:#006666">1</span>, <span style="color:#006666">1</span>), strides = (<span style="color:#006666">1</span>,<span style="color:#006666">1</span>), name = conv_name_base + <span style="color:#009900">'2c'</span>, kernel_initializer = glorot_uniform(seed=<span style="color:#006666">0</span>))(X)
X = BatchNormalization(axis = <span style="color:#006666">3</span>, name = bn_name_base + <span style="color:#009900">'2c'</span>)(X)
<span style="color:#880000">##### SHORTCUT PATH #### (≈2 lines)</span>
X_shortcut = Conv2D(F3, (<span style="color:#006666">1</span>, <span style="color:#006666">1</span>), strides = (s,s), name = conv_name_base + <span style="color:#009900">'1'</span>, kernel_initializer = glorot_uniform(seed=<span style="color:#006666">0</span>))(X_shortcut)
X_shortcut = BatchNormalization(axis = <span style="color:#006666">3</span>, name = bn_name_base + <span style="color:#009900">'1'</span>)(X_shortcut)
<span style="color:#880000"># Final step: Add shortcut value to main path, and pass it through a RELU activation (≈2 lines)</span>
X = Add()([X, X_shortcut])
X = Activation(<span style="color:#009900">'relu'</span>)(X)
<span style="color:#880000">### END CODE HERE ###</span>
<span style="color:#000088">return</span> X</code></span><span style="color:#000000"><code class="language-python">tf.reset_default_graph()
<span style="color:#000088">with</span> tf.Session() <span style="color:#000088">as</span> test:
np.random.seed(<span style="color:#006666">1</span>)
A_prev = tf.placeholder(<span style="color:#009900">"float"</span>, [<span style="color:#006666">3</span>, <span style="color:#006666">4</span>, <span style="color:#006666">4</span>, <span style="color:#006666">6</span>])
X = np.random.randn(<span style="color:#006666">3</span>, <span style="color:#006666">4</span>, <span style="color:#006666">4</span>, <span style="color:#006666">6</span>)
A = convolutional_block(A_prev, f = <span style="color:#006666">2</span>, filters = [<span style="color:#006666">2</span>, <span style="color:#006666">4</span>, <span style="color:#006666">6</span>], stage = <span style="color:#006666">1</span>, block = <span style="color:#009900">'a'</span>)
test.run(tf.global_variables_initializer())
out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): <span style="color:#006666">0</span>})
print(<span style="color:#009900">"out = "</span> + str(out[<span style="color:#006666">0</span>][<span style="color:#006666">1</span>][<span style="color:#006666">1</span>][<span style="color:#006666">0</span>]))</code></span><span style="color:#000000"><code>out = [ 0.09018463 1.23489773 0.46822017 0.0367176 0. 0.65516603]
</code></span>3 - Building your first ResNet model (50 layers)
You now have the necessary blocks to build a very deep ResNet. The following figure describes in detail the architecture of this neural network. “ID BLOCK” in the diagram stands for “Identity block,” and “ID BLOCK x3” means you should stack 3 identity blocks together.
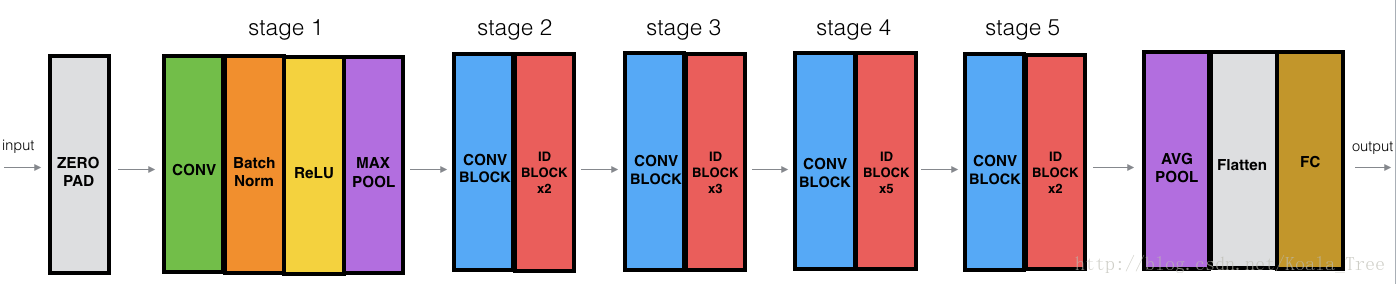
Figure 5 : ResNet-50 model
The details of this ResNet-50 model are:
- Zero-padding pads the input with a pad of (3,3)
- Stage 1:
- The 2D Convolution has 64 filters of shape (7,7) and uses a stride of (2,2). Its name is “conv1”.
- BatchNorm is applied to the channels axis of the input.
- MaxPooling uses a (3,3) window and a (2,2) stride.
- Stage 2:
- The convolutional block uses three set of filters of size [64,64,256], “f” is 3, “s” is 1 and the block is “a”.
- The 2 identity blocks use three set of filters of size [64,64,256], “f” is 3 and the blocks are “b” and “c”.
- Stage 3:
- The convolutional block uses three set of filters of size [128,128,512], “f” is 3, “s” is 2 and the block is “a”.
- The 3 identity blocks use three set of filters of size [128,128,512], “f” is 3 and the blocks are “b”, “c” and “d”.
- Stage 4:
- The convolutional block uses three set of filters of size [256, 256, 1024], “f” is 3, “s” is 2 and the block is “a”.
- The 5 identity blocks use three set of filters of size [256, 256, 1024], “f” is 3 and the blocks are “b”, “c”, “d”, “e” and “f”.
- Stage 5:
- The convolutional block uses three set of filters of size [512, 512, 2048], “f” is 3, “s” is 2 and the block is “a”.
- The 2 identity blocks use three set of filters of size [512, 512, 2048], “f” is 3 and the blocks are “b” and “c”.
- The 2D Average Pooling uses a window of shape (2,2) and its name is “avg_pool”.
- The flatten doesn’t have any hyperparameters or name.
- The Fully Connected (Dense) layer reduces its input to the number of classes using a softmax activation. Its name should be 'fc' + str(classes).
Exercise: Implement the ResNet with 50 layers described in the figure above. We have implemented Stages 1 and 2. Please implement the rest. (The syntax for implementing Stages 3-5 should be quite similar to that of Stage 2.) Make sure you follow the naming convention in the text above.
You’ll need to use this function:
- Average pooling see reference
Here’re some other functions we used in the code below:
- Conv2D: See reference
- BatchNorm: See reference (axis: Integer, the axis that should be normalized (typically the features axis))
- Zero padding: See reference
- Max pooling: See reference
- Fully conected layer: See reference
- Addition: See reference
<span style="color:#000000"><code class="language-python"><span style="color:#880000"># GRADED FUNCTION: ResNet50</span>
<span style="color:#000088">def</span> <span style="color:#009900">ResNet50</span><span style="color:#4f4f4f">(input_shape = <span style="color:#4f4f4f">(<span style="color:#006666">64</span>, <span style="color:#006666">64</span>, <span style="color:#006666">3</span>)</span>, classes = <span style="color:#006666">6</span>)</span>:
<span style="color:#009900">"""
Implementation of the popular ResNet50 the following architecture:
CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3
-> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER
Arguments:
input_shape -- shape of the images of the dataset
classes -- integer, number of classes
Returns:
model -- a Model() instance in Keras
"""</span>
<span style="color:#880000"># Define the input as a tensor with shape input_shape</span>
X_input = Input(input_shape)
<span style="color:#880000"># Zero-Padding</span>
X = ZeroPadding2D((<span style="color:#006666">3</span>, <span style="color:#006666">3</span>))(X_input)
<span style="color:#880000"># Stage 1</span>
X = Conv2D(<span style="color:#006666">64</span>, (<span style="color:#006666">7</span>, <span style="color:#006666">7</span>), strides = (<span style="color:#006666">2</span>, <span style="color:#006666">2</span>), name = <span style="color:#009900">'conv1'</span>, kernel_initializer = glorot_uniform(seed=<span style="color:#006666">0</span>))(X)
X = BatchNormalization(axis = <span style="color:#006666">3</span>, name = <span style="color:#009900">'bn_conv1'</span>)(X)
X = Activation(<span style="color:#009900">'relu'</span>)(X)
X = MaxPooling2D((<span style="color:#006666">3</span>, <span style="color:#006666">3</span>), strides=(<span style="color:#006666">2</span>, <span style="color:#006666">2</span>))(X)
<span style="color:#880000"># Stage 2</span>
X = convolutional_block(X, f = <span style="color:#006666">3</span>, filters = [<span style="color:#006666">64</span>, <span style="color:#006666">64</span>, <span style="color:#006666">256</span>], stage = <span style="color:#006666">2</span>, block=<span style="color:#009900">'a'</span>, s = <span style="color:#006666">1</span>)
X = identity_block(X, <span style="color:#006666">3</span>, [<span style="color:#006666">64</span>, <span style="color:#006666">64</span>, <span style="color:#006666">256</span>], stage=<span style="color:#006666">2</span>, block=<span style="color:#009900">'b'</span>)
X = identity_block(X, <span style="color:#006666">3</span>, [<span style="color:#006666">64</span>, <span style="color:#006666">64</span>, <span style="color:#006666">256</span>], stage=<span style="color:#006666">2</span>, block=<span style="color:#009900">'c'</span>)
<span style="color:#880000">### START CODE HERE ###</span>
<span style="color:#880000"># Stage 3 (≈4 lines)</span>
X = convolutional_block(X, f = <span style="color:#006666">3</span>, filters = [<span style="color:#006666">128</span>, <span style="color:#006666">128</span>, <span style="color:#006666">512</span>], stage = <span style="color:#006666">3</span>, block=<span style="color:#009900">'a'</span>, s = <span style="color:#006666">2</span>)
X = identity_block(X, <span style="color:#006666">3</span>, [<span style="color:#006666">128</span>, <span style="color:#006666">128</span>, <span style="color:#006666">512</span>], stage=<span style="color:#006666">3</span>, block=<span style="color:#009900">'b'</span>)
X = identity_block(X, <span style="color:#006666">3</span>, [<span style="color:#006666">128</span>, <span style="color:#006666">128</span>, <span style="color:#006666">512</span>], stage=<span style="color:#006666">3</span>, block=<span style="color:#009900">'c'</span>)
X = identity_block(X, <span style="color:#006666">3</span>, [<span style="color:#006666">128</span>, <span style="color:#006666">128</span>, <span style="color:#006666">512</span>], stage=<span style="color:#006666">3</span>, block=<span style="color:#009900">'d'</span>)
<span style="color:#880000"># Stage 4 (≈6 lines)</span>
X = convolutional_block(X, f = <span style="color:#006666">3</span>, filters = [<span style="color:#006666">256</span>, <span style="color:#006666">256</span>, <span style="color:#006666">1024</span>], stage = <span style="color:#006666">4</span>, block=<span style="color:#009900">'a'</span>, s = <span style="color:#006666">2</span>)
X = identity_block(X, <span style="color:#006666">3</span>, [<span style="color:#006666">256</span>, <span style="color:#006666">256</span>, <span style="color:#006666">1024</span>], stage=<span style="color:#006666">4</span>, block=<span style="color:#009900">'b'</span>)
X = identity_block(X, <span style="color:#006666">3</span>, [<span style="color:#006666">256</span>, <span style="color:#006666">256</span>, <span style="color:#006666">1024</span>], stage=<span style="color:#006666">4</span>, block=<span style="color:#009900">'c'</span>)
X = identity_block(X, <span style="color:#006666">3</span>, [<span style="color:#006666">256</span>, <span style="color:#006666">256</span>, <span style="color:#006666">1024</span>], stage=<span style="color:#006666">4</span>, block=<span style="color:#009900">'d'</span>)
X = identity_block(X, <span style="color:#006666">3</span>, [<span style="color:#006666">256</span>, <span style="color:#006666">256</span>, <span style="color:#006666">1024</span>], stage=<span style="color:#006666">4</span>, block=<span style="color:#009900">'e'</span>)
X = identity_block(X, <span style="color:#006666">3</span>, [<span style="color:#006666">256</span>, <span style="color:#006666">256</span>, <span style="color:#006666">1024</span>], stage=<span style="color:#006666">4</span>, block=<span style="color:#009900">'f'</span>)
<span style="color:#880000"># Stage 5 (≈3 lines)</span>
X = convolutional_block(X, f = <span style="color:#006666">3</span>, filters = [<span style="color:#006666">512</span>, <span style="color:#006666">512</span>, <span style="color:#006666">2048</span>], stage = <span style="color:#006666">5</span>, block=<span style="color:#009900">'a'</span>, s = <span style="color:#006666">2</span>)
X = identity_block(X, <span style="color:#006666">3</span>, [<span style="color:#006666">512</span>, <span style="color:#006666">512</span>, <span style="color:#006666">2048</span>], stage=<span style="color:#006666">5</span>, block=<span style="color:#009900">'b'</span>)
X = identity_block(X, <span style="color:#006666">3</span>, [<span style="color:#006666">512</span>, <span style="color:#006666">512</span>, <span style="color:#006666">2048</span>], stage=<span style="color:#006666">5</span>, block=<span style="color:#009900">'c'</span>)
<span style="color:#880000"># AVGPOOL (≈1 line). Use "X = AveragePooling2D(...)(X)"</span>
X = AveragePooling2D((<span style="color:#006666">2</span>, <span style="color:#006666">2</span>), name=<span style="color:#009900">'avg_pool'</span>)(X)
<span style="color:#880000">### END CODE HERE ###</span>
<span style="color:#880000"># output layer</span>
X = Flatten()(X)
X = Dense(classes, activation=<span style="color:#009900">'softmax'</span>, name=<span style="color:#009900">'fc'</span> + str(classes), kernel_initializer = glorot_uniform(seed=<span style="color:#006666">0</span>))(X)
<span style="color:#880000"># Create model</span>
model = Model(inputs = X_input, outputs = X, name=<span style="color:#009900">'ResNet50'</span>)
<span style="color:#000088">return</span> model</code></span>Run the following code to build the model’s graph. If your implementation is not correct you will know it by checking your accuracy when running model.fit(...) below.
<span style="color:#000000"><code class="language-python">model = ResNet50(input_shape = (<span style="color:#006666">64</span>, <span style="color:#006666">64</span>, <span style="color:#006666">3</span>), classes = <span style="color:#006666">6</span>)</code></span>As seen in the Keras Tutorial Notebook, prior training a model, you need to configure the learning process by compiling the model.
<span style="color:#000000"><code class="language-python">model.compile(optimizer=<span style="color:#009900">'adam'</span>, loss=<span style="color:#009900">'categorical_crossentropy'</span>, metrics=[<span style="color:#009900">'accuracy'</span>])</code></span>The model is now ready to be trained. The only thing you need is a dataset.
Let’s load the SIGNS Dataset.

Figure 6 : SIGNS dataset
<span style="color:#000000"><code class="language-python">X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
<span style="color:#880000"># Normalize image vectors</span>
X_train = X_train_orig/<span style="color:#006666">255.</span>
X_test = X_test_orig/<span style="color:#006666">255.</span>
<span style="color:#880000"># Convert training and test labels to one hot matrices</span>
Y_train = convert_to_one_hot(Y_train_orig, <span style="color:#006666">6</span>).T
Y_test = convert_to_one_hot(Y_test_orig, <span style="color:#006666">6</span>).T
<span style="color:#000088">print</span> (<span style="color:#009900">"number of training examples = "</span> + str(X_train.shape[<span style="color:#006666">0</span>]))
<span style="color:#000088">print</span> (<span style="color:#009900">"number of test examples = "</span> + str(X_test.shape[<span style="color:#006666">0</span>]))
<span style="color:#000088">print</span> (<span style="color:#009900">"X_train shape: "</span> + str(X_train.shape))
<span style="color:#000088">print</span> (<span style="color:#009900">"Y_train shape: "</span> + str(Y_train.shape))
<span style="color:#000088">print</span> (<span style="color:#009900">"X_test shape: "</span> + str(X_test.shape))
<span style="color:#000088">print</span> (<span style="color:#009900">"Y_test shape: "</span> + str(Y_test.shape))</code></span><span style="color:#000000"><code>number of training examples = 1080
number of test examples = 120
X_train shape: (1080, 64, 64, 3)
Y_train shape: (1080, 6)
X_test shape: (120, 64, 64, 3)
Y_test shape: (120, 6)
</code></span>Run the following cell to train your model on 2 epochs with a batch size of 32. On a CPU it should take you around 5min per epoch.
<span style="color:#000000"><code class="language-python">model.fit(X_train, Y_train, epochs = <span style="color:#006666">2</span>, batch_size = <span style="color:#006666">32</span>)</code></span><span style="color:#000000"><code>Epoch 1/2
1080/1080 [==============================] - 260s - loss: 2.9406 - acc: 0.2713
Epoch 2/2
1080/1080 [==============================] - 239s - loss: 2.4578 - acc: 0.3083
<keras.callbacks.History at 0x7fc9ac1c1cc0>
</code></span>Expected Output:
| ** Epoch 1/2 ** | loss: between 1 and 5, acc: between 0.2 and 0.5, although your results can be different from ours. |
| ** Epoch 2/2** | loss: between 1 and 5, acc: between 0.2 and 0.5, you should see your loss decreasing and the accuracy increasing. |
Let’s see how this model (trained on only two epochs) performs on the test set.
<span style="color:#000000"><code class="language-python">preds = model.evaluate(X_test, Y_test)
<span style="color:#000088">print</span> (<span style="color:#009900">"Loss = "</span> + str(preds[<span style="color:#006666">0</span>]))
<span style="color:#000088">print</span> (<span style="color:#009900">"Test Accuracy = "</span> + str(preds[<span style="color:#006666">1</span>]))</code></span><span style="color:#000000"><code>120/120 [==============================] - 9s
Loss = 2.14532471498
Test Accuracy = 0.166666666667
</code></span>Expected Output:
| **Test Accuracy** | between 0.16 and 0.25 |
For the purpose of this assignment, we’ve asked you to train the model only for two epochs. You can see that it achieves poor performances. Please go ahead and submit your assignment; to check correctness, the online grader will run your code only for a small number of epochs as well.
After you have finished this official (graded) part of this assignment, you can also optionally train the ResNet for more iterations, if you want. We get a lot better performance when we train for ~20 epochs, but this will take more than an hour when training on a CPU.
Using a GPU, we’ve trained our own ResNet50 model’s weights on the SIGNS dataset. You can load and run our trained model on the test set in the cells below. It may take ≈1min to load the model.
<span style="color:#000000"><code class="language-python">model = load_model(<span style="color:#009900">'ResNet50.h5'</span>) </code></span><span style="color:#000000"><code class="language-python">preds = model.evaluate(X_test, Y_test)
<span style="color:#000088">print</span> (<span style="color:#009900">"Loss = "</span> + str(preds[<span style="color:#006666">0</span>]))
<span style="color:#000088">print</span> (<span style="color:#009900">"Test Accuracy = "</span> + str(preds[<span style="color:#006666">1</span>]))</code></span><span style="color:#000000"><code>120/120 [==============================] - 9s
Loss = 0.530178320408
Test Accuracy = 0.866666662693
</code></span>ResNet50 is a powerful model for image classification when it is trained for an adequate number of iterations. We hope you can use what you’ve learnt and apply it to your own classification problem to perform state-of-the-art accuracy.
Congratulations on finishing this assignment! You’ve now implemented a state-of-the-art image classification system!
4 - Test on your own image (Optional/Ungraded)
If you wish, you can also take a picture of your own hand and see the output of the model. To do this:
1. Click on “File” in the upper bar of this notebook, then click “Open” to go on your Coursera Hub.
2. Add your image to this Jupyter Notebook’s directory, in the “images” folder
3. Write your image’s name in the following code
4. Run the code and check if the algorithm is right!
<span style="color:#000000"><code class="language-python">img_path = <span style="color:#009900">'images/my_image.jpg'</span>
img = image.load_img(img_path, target_size=(<span style="color:#006666">64</span>, <span style="color:#006666">64</span>))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=<span style="color:#006666">0</span>)
x = preprocess_input(x)
print(<span style="color:#009900">'Input image shape:'</span>, x.shape)
my_image = scipy.misc.imread(img_path)
imshow(my_image)
print(<span style="color:#009900">"class prediction vector [p(0), p(1), p(2), p(3), p(4), p(5)] = "</span>)
print(model.predict(x))</code></span><span style="color:#000000"><code>Input image shape: (1, 64, 64, 3)
class prediction vector [p(0), p(1), p(2), p(3), p(4), p(5)] =
[[ 1. 0. 0. 0. 0. 0.]]
</code></span>

You can also print a summary of your model by running the following code.
<span style="color:#000000"><code class="language-python">model.summary()</code></span>- 1
<span style="color:#000000"><code>____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
input_1 (InputLayer) (None, 64, 64, 3) 0
____________________________________________________________________________________________________
zero_padding2d_1 (ZeroPadding2D) (None, 70, 70, 3) 0 input_1[0][0]
____________________________________________________________________________________________________
conv1 (Conv2D) (None, 32, 32, 64) 9472 zero_padding2d_1[0][0]
____________________________________________________________________________________________________
bn_conv1 (BatchNormalization) (None, 32, 32, 64) 256 conv1[0][0]
____________________________________________________________________________________________________
activation_4 (Activation) (None, 32, 32, 64) 0 bn_conv1[0][0]
____________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 15, 15, 64) 0 activation_4[0][0]
____________________________________________________________________________________________________
res2a_branch2a (Conv2D) (None, 15, 15, 64) 4160 max_pooling2d_1[0][0]
____________________________________________________________________________________________________
bn2a_branch2a (BatchNormalizatio (None, 15, 15, 64) 256 res2a_branch2a[0][0]
____________________________________________________________________________________________________
activation_5 (Activation) (None, 15, 15, 64) 0 bn2a_branch2a[0][0]
____________________________________________________________________________________________________
res2a_branch2b (Conv2D) (None, 15, 15, 64) 36928 activation_5[0][0]
____________________________________________________________________________________________________
bn2a_branch2b (BatchNormalizatio (None, 15, 15, 64) 256 res2a_branch2b[0][0]
____________________________________________________________________________________________________
activation_6 (Activation) (None, 15, 15, 64) 0 bn2a_branch2b[0][0]
____________________________________________________________________________________________________
res2a_branch2c (Conv2D) (None, 15, 15, 256) 16640 activation_6[0][0]
____________________________________________________________________________________________________
res2a_branch1 (Conv2D) (None, 15, 15, 256) 16640 max_pooling2d_1[0][0]
____________________________________________________________________________________________________
bn2a_branch2c (BatchNormalizatio (None, 15, 15, 256) 1024 res2a_branch2c[0][0]
____________________________________________________________________________________________________
bn2a_branch1 (BatchNormalization (None, 15, 15, 256) 1024 res2a_branch1[0][0]
____________________________________________________________________________________________________
add_2 (Add) (None, 15, 15, 256) 0 bn2a_branch2c[0][0]
bn2a_branch1[0][0]
____________________________________________________________________________________________________
activation_7 (Activation) (None, 15, 15, 256) 0 add_2[0][0]
____________________________________________________________________________________________________
res2b_branch2a (Conv2D) (None, 15, 15, 64) 16448 activation_7[0][0]
____________________________________________________________________________________________________
bn2b_branch2a (BatchNormalizatio (None, 15, 15, 64) 256 res2b_branch2a[0][0]
____________________________________________________________________________________________________
activation_8 (Activation) (None, 15, 15, 64) 0 bn2b_branch2a[0][0]
____________________________________________________________________________________________________
res2b_branch2b (Conv2D) (None, 15, 15, 64) 36928 activation_8[0][0]
____________________________________________________________________________________________________
bn2b_branch2b (BatchNormalizatio (None, 15, 15, 64) 256 res2b_branch2b[0][0]
____________________________________________________________________________________________________
activation_9 (Activation) (None, 15, 15, 64) 0 bn2b_branch2b[0][0]
____________________________________________________________________________________________________
res2b_branch2c (Conv2D) (None, 15, 15, 256) 16640 activation_9[0][0]
____________________________________________________________________________________________________
bn2b_branch2c (BatchNormalizatio (None, 15, 15, 256) 1024 res2b_branch2c[0][0]
____________________________________________________________________________________________________
add_3 (Add) (None, 15, 15, 256) 0 bn2b_branch2c[0][0]
activation_7[0][0]
____________________________________________________________________________________________________
activation_10 (Activation) (None, 15, 15, 256) 0 add_3[0][0]
____________________________________________________________________________________________________
res2c_branch2a (Conv2D) (None, 15, 15, 64) 16448 activation_10[0][0]
____________________________________________________________________________________________________
bn2c_branch2a (BatchNormalizatio (None, 15, 15, 64) 256 res2c_branch2a[0][0]
____________________________________________________________________________________________________
activation_11 (Activation) (None, 15, 15, 64) 0 bn2c_branch2a[0][0]
____________________________________________________________________________________________________
res2c_branch2b (Conv2D) (None, 15, 15, 64) 36928 activation_11[0][0]
____________________________________________________________________________________________________
bn2c_branch2b (BatchNormalizatio (None, 15, 15, 64) 256 res2c_branch2b[0][0]
____________________________________________________________________________________________________
activation_12 (Activation) (None, 15, 15, 64) 0 bn2c_branch2b[0][0]
____________________________________________________________________________________________________
res2c_branch2c (Conv2D) (None, 15, 15, 256) 16640 activation_12[0][0]
____________________________________________________________________________________________________
bn2c_branch2c (BatchNormalizatio (None, 15, 15, 256) 1024 res2c_branch2c[0][0]
____________________________________________________________________________________________________
add_4 (Add) (None, 15, 15, 256) 0 bn2c_branch2c[0][0]
activation_10[0][0]
____________________________________________________________________________________________________
activation_13 (Activation) (None, 15, 15, 256) 0 add_4[0][0]
____________________________________________________________________________________________________
res3a_branch2a (Conv2D) (None, 8, 8, 128) 32896 activation_13[0][0]
____________________________________________________________________________________________________
bn3a_branch2a (BatchNormalizatio (None, 8, 8, 128) 512 res3a_branch2a[0][0]
____________________________________________________________________________________________________
activation_14 (Activation) (None, 8, 8, 128) 0 bn3a_branch2a[0][0]
____________________________________________________________________________________________________
res3a_branch2b (Conv2D) (None, 8, 8, 128) 147584 activation_14[0][0]
____________________________________________________________________________________________________
bn3a_branch2b (BatchNormalizatio (None, 8, 8, 128) 512 res3a_branch2b[0][0]
____________________________________________________________________________________________________
activation_15 (Activation) (None, 8, 8, 128) 0 bn3a_branch2b[0][0]
____________________________________________________________________________________________________
res3a_branch2c (Conv2D) (None, 8, 8, 512) 66048 activation_15[0][0]
____________________________________________________________________________________________________
res3a_branch1 (Conv2D) (None, 8, 8, 512) 131584 activation_13[0][0]
____________________________________________________________________________________________________
bn3a_branch2c (BatchNormalizatio (None, 8, 8, 512) 2048 res3a_branch2c[0][0]
____________________________________________________________________________________________________
bn3a_branch1 (BatchNormalization (None, 8, 8, 512) 2048 res3a_branch1[0][0]
____________________________________________________________________________________________________
add_5 (Add) (None, 8, 8, 512) 0 bn3a_branch2c[0][0]
bn3a_branch1[0][0]
____________________________________________________________________________________________________
activation_16 (Activation) (None, 8, 8, 512) 0 add_5[0][0]
____________________________________________________________________________________________________
res3b_branch2a (Conv2D) (None, 8, 8, 128) 65664 activation_16[0][0]
____________________________________________________________________________________________________
bn3b_branch2a (BatchNormalizatio (None, 8, 8, 128) 512 res3b_branch2a[0][0]
____________________________________________________________________________________________________
activation_17 (Activation) (None, 8, 8, 128) 0 bn3b_branch2a[0][0]
____________________________________________________________________________________________________
res3b_branch2b (Conv2D) (None, 8, 8, 128) 147584 activation_17[0][0]
____________________________________________________________________________________________________
bn3b_branch2b (BatchNormalizatio (None, 8, 8, 128) 512 res3b_branch2b[0][0]
____________________________________________________________________________________________________
activation_18 (Activation) (None, 8, 8, 128) 0 bn3b_branch2b[0][0]
____________________________________________________________________________________________________
res3b_branch2c (Conv2D) (None, 8, 8, 512) 66048 activation_18[0][0]
____________________________________________________________________________________________________
bn3b_branch2c (BatchNormalizatio (None, 8, 8, 512) 2048 res3b_branch2c[0][0]
____________________________________________________________________________________________________
add_6 (Add) (None, 8, 8, 512) 0 bn3b_branch2c[0][0]
activation_16[0][0]
____________________________________________________________________________________________________
activation_19 (Activation) (None, 8, 8, 512) 0 add_6[0][0]
____________________________________________________________________________________________________
res3c_branch2a (Conv2D) (None, 8, 8, 128) 65664 activation_19[0][0]
____________________________________________________________________________________________________
bn3c_branch2a (BatchNormalizatio (None, 8, 8, 128) 512 res3c_branch2a[0][0]
____________________________________________________________________________________________________
activation_20 (Activation) (None, 8, 8, 128) 0 bn3c_branch2a[0][0]
____________________________________________________________________________________________________
res3c_branch2b (Conv2D) (None, 8, 8, 128) 147584 activation_20[0][0]
____________________________________________________________________________________________________
bn3c_branch2b (BatchNormalizatio (None, 8, 8, 128) 512 res3c_branch2b[0][0]
____________________________________________________________________________________________________
activation_21 (Activation) (None, 8, 8, 128) 0 bn3c_branch2b[0][0]
____________________________________________________________________________________________________
res3c_branch2c (Conv2D) (None, 8, 8, 512) 66048 activation_21[0][0]
____________________________________________________________________________________________________
bn3c_branch2c (BatchNormalizatio (None, 8, 8, 512) 2048 res3c_branch2c[0][0]
____________________________________________________________________________________________________
add_7 (Add) (None, 8, 8, 512) 0 bn3c_branch2c[0][0]
activation_19[0][0]
____________________________________________________________________________________________________
activation_22 (Activation) (None, 8, 8, 512) 0 add_7[0][0]
____________________________________________________________________________________________________
res3d_branch2a (Conv2D) (None, 8, 8, 128) 65664 activation_22[0][0]
____________________________________________________________________________________________________
bn3d_branch2a (BatchNormalizatio (None, 8, 8, 128) 512 res3d_branch2a[0][0]
____________________________________________________________________________________________________
activation_23 (Activation) (None, 8, 8, 128) 0 bn3d_branch2a[0][0]
____________________________________________________________________________________________________
res3d_branch2b (Conv2D) (None, 8, 8, 128) 147584 activation_23[0][0]
____________________________________________________________________________________________________
bn3d_branch2b (BatchNormalizatio (None, 8, 8, 128) 512 res3d_branch2b[0][0]
____________________________________________________________________________________________________
activation_24 (Activation) (None, 8, 8, 128) 0 bn3d_branch2b[0][0]
____________________________________________________________________________________________________
res3d_branch2c (Conv2D) (None, 8, 8, 512) 66048 activation_24[0][0]
____________________________________________________________________________________________________
bn3d_branch2c (BatchNormalizatio (None, 8, 8, 512) 2048 res3d_branch2c[0][0]
____________________________________________________________________________________________________
add_8 (Add) (None, 8, 8, 512) 0 bn3d_branch2c[0][0]
activation_22[0][0]
____________________________________________________________________________________________________
activation_25 (Activation) (None, 8, 8, 512) 0 add_8[0][0]
____________________________________________________________________________________________________
res4a_branch2a (Conv2D) (None, 4, 4, 256) 131328 activation_25[0][0]
____________________________________________________________________________________________________
bn4a_branch2a (BatchNormalizatio (None, 4, 4, 256) 1024 res4a_branch2a[0][0]
____________________________________________________________________________________________________
activation_26 (Activation) (None, 4, 4, 256) 0 bn4a_branch2a[0][0]
____________________________________________________________________________________________________
res4a_branch2b (Conv2D) (None, 4, 4, 256) 590080 activation_26[0][0]
____________________________________________________________________________________________________
bn4a_branch2b (BatchNormalizatio (None, 4, 4, 256) 1024 res4a_branch2b[0][0]
____________________________________________________________________________________________________
activation_27 (Activation) (None, 4, 4, 256) 0 bn4a_branch2b[0][0]
____________________________________________________________________________________________________
res4a_branch2c (Conv2D) (None, 4, 4, 1024) 263168 activation_27[0][0]
____________________________________________________________________________________________________
res4a_branch1 (Conv2D) (None, 4, 4, 1024) 525312 activation_25[0][0]
____________________________________________________________________________________________________
bn4a_branch2c (BatchNormalizatio (None, 4, 4, 1024) 4096 res4a_branch2c[0][0]
____________________________________________________________________________________________________
bn4a_branch1 (BatchNormalization (None, 4, 4, 1024) 4096 res4a_branch1[0][0]
____________________________________________________________________________________________________
add_9 (Add) (None, 4, 4, 1024) 0 bn4a_branch2c[0][0]
bn4a_branch1[0][0]
____________________________________________________________________________________________________
activation_28 (Activation) (None, 4, 4, 1024) 0 add_9[0][0]
____________________________________________________________________________________________________
res4b_branch2a (Conv2D) (None, 4, 4, 256) 262400 activation_28[0][0]
____________________________________________________________________________________________________
bn4b_branch2a (BatchNormalizatio (None, 4, 4, 256) 1024 res4b_branch2a[0][0]
____________________________________________________________________________________________________
activation_29 (Activation) (None, 4, 4, 256) 0 bn4b_branch2a[0][0]
____________________________________________________________________________________________________
res4b_branch2b (Conv2D) (None, 4, 4, 256) 590080 activation_29[0][0]
____________________________________________________________________________________________________
bn4b_branch2b (BatchNormalizatio (None, 4, 4, 256) 1024 res4b_branch2b[0][0]
____________________________________________________________________________________________________
activation_30 (Activation) (None, 4, 4, 256) 0 bn4b_branch2b[0][0]
____________________________________________________________________________________________________
res4b_branch2c (Conv2D) (None, 4, 4, 1024) 263168 activation_30[0][0]
____________________________________________________________________________________________________
bn4b_branch2c (BatchNormalizatio (None, 4, 4, 1024) 4096 res4b_branch2c[0][0]
____________________________________________________________________________________________________
add_10 (Add) (None, 4, 4, 1024) 0 bn4b_branch2c[0][0]
activation_28[0][0]
____________________________________________________________________________________________________
activation_31 (Activation) (None, 4, 4, 1024) 0 add_10[0][0]
____________________________________________________________________________________________________
res4c_branch2a (Conv2D) (None, 4, 4, 256) 262400 activation_31[0][0]
____________________________________________________________________________________________________
bn4c_branch2a (BatchNormalizatio (None, 4, 4, 256) 1024 res4c_branch2a[0][0]
____________________________________________________________________________________________________
activation_32 (Activation) (None, 4, 4, 256) 0 bn4c_branch2a[0][0]
____________________________________________________________________________________________________
res4c_branch2b (Conv2D) (None, 4, 4, 256) 590080 activation_32[0][0]
____________________________________________________________________________________________________
bn4c_branch2b (BatchNormalizatio (None, 4, 4, 256) 1024 res4c_branch2b[0][0]
____________________________________________________________________________________________________
activation_33 (Activation) (None, 4, 4, 256) 0 bn4c_branch2b[0][0]
____________________________________________________________________________________________________
res4c_branch2c (Conv2D) (None, 4, 4, 1024) 263168 activation_33[0][0]
____________________________________________________________________________________________________
bn4c_branch2c (BatchNormalizatio (None, 4, 4, 1024) 4096 res4c_branch2c[0][0]
____________________________________________________________________________________________________
add_11 (Add) (None, 4, 4, 1024) 0 bn4c_branch2c[0][0]
activation_31[0][0]
____________________________________________________________________________________________________
activation_34 (Activation) (None, 4, 4, 1024) 0 add_11[0][0]
____________________________________________________________________________________________________
res4d_branch2a (Conv2D) (None, 4, 4, 256) 262400 activation_34[0][0]
____________________________________________________________________________________________________
bn4d_branch2a (BatchNormalizatio (None, 4, 4, 256) 1024 res4d_branch2a[0][0]
____________________________________________________________________________________________________
activation_35 (Activation) (None, 4, 4, 256) 0 bn4d_branch2a[0][0]
____________________________________________________________________________________________________
res4d_branch2b (Conv2D) (None, 4, 4, 256) 590080 activation_35[0][0]
____________________________________________________________________________________________________
bn4d_branch2b (BatchNormalizatio (None, 4, 4, 256) 1024 res4d_branch2b[0][0]
____________________________________________________________________________________________________
activation_36 (Activation) (None, 4, 4, 256) 0 bn4d_branch2b[0][0]
____________________________________________________________________________________________________
res4d_branch2c (Conv2D) (None, 4, 4, 1024) 263168 activation_36[0][0]
____________________________________________________________________________________________________
bn4d_branch2c (BatchNormalizatio (None, 4, 4, 1024) 4096 res4d_branch2c[0][0]
____________________________________________________________________________________________________
add_12 (Add) (None, 4, 4, 1024) 0 bn4d_branch2c[0][0]
activation_34[0][0]
____________________________________________________________________________________________________
activation_37 (Activation) (None, 4, 4, 1024) 0 add_12[0][0]
____________________________________________________________________________________________________
res4e_branch2a (Conv2D) (None, 4, 4, 256) 262400 activation_37[0][0]
____________________________________________________________________________________________________
bn4e_branch2a (BatchNormalizatio (None, 4, 4, 256) 1024 res4e_branch2a[0][0]
____________________________________________________________________________________________________
activation_38 (Activation) (None, 4, 4, 256) 0 bn4e_branch2a[0][0]
____________________________________________________________________________________________________
res4e_branch2b (Conv2D) (None, 4, 4, 256) 590080 activation_38[0][0]
____________________________________________________________________________________________________
bn4e_branch2b (BatchNormalizatio (None, 4, 4, 256) 1024 res4e_branch2b[0][0]
____________________________________________________________________________________________________
activation_39 (Activation) (None, 4, 4, 256) 0 bn4e_branch2b[0][0]
____________________________________________________________________________________________________
res4e_branch2c (Conv2D) (None, 4, 4, 1024) 263168 activation_39[0][0]
____________________________________________________________________________________________________
bn4e_branch2c (BatchNormalizatio (None, 4, 4, 1024) 4096 res4e_branch2c[0][0]
____________________________________________________________________________________________________
add_13 (Add) (None, 4, 4, 1024) 0 bn4e_branch2c[0][0]
activation_37[0][0]
____________________________________________________________________________________________________
activation_40 (Activation) (None, 4, 4, 1024) 0 add_13[0][0]
____________________________________________________________________________________________________
res4f_branch2a (Conv2D) (None, 4, 4, 256) 262400 activation_40[0][0]
____________________________________________________________________________________________________
bn4f_branch2a (BatchNormalizatio (None, 4, 4, 256) 1024 res4f_branch2a[0][0]
____________________________________________________________________________________________________
activation_41 (Activation) (None, 4, 4, 256) 0 bn4f_branch2a[0][0]
____________________________________________________________________________________________________
res4f_branch2b (Conv2D) (None, 4, 4, 256) 590080 activation_41[0][0]
____________________________________________________________________________________________________
bn4f_branch2b (BatchNormalizatio (None, 4, 4, 256) 1024 res4f_branch2b[0][0]
____________________________________________________________________________________________________
activation_42 (Activation) (None, 4, 4, 256) 0 bn4f_branch2b[0][0]
____________________________________________________________________________________________________
res4f_branch2c (Conv2D) (None, 4, 4, 1024) 263168 activation_42[0][0]
____________________________________________________________________________________________________
bn4f_branch2c (BatchNormalizatio (None, 4, 4, 1024) 4096 res4f_branch2c[0][0]
____________________________________________________________________________________________________
add_14 (Add) (None, 4, 4, 1024) 0 bn4f_branch2c[0][0]
activation_40[0][0]
____________________________________________________________________________________________________
activation_43 (Activation) (None, 4, 4, 1024) 0 add_14[0][0]
____________________________________________________________________________________________________
res5a_branch2a (Conv2D) (None, 2, 2, 512) 524800 activation_43[0][0]
____________________________________________________________________________________________________
bn5a_branch2a (BatchNormalizatio (None, 2, 2, 512) 2048 res5a_branch2a[0][0]
____________________________________________________________________________________________________
activation_44 (Activation) (None, 2, 2, 512) 0 bn5a_branch2a[0][0]
____________________________________________________________________________________________________
res5a_branch2b (Conv2D) (None, 2, 2, 512) 2359808 activation_44[0][0]
____________________________________________________________________________________________________
bn5a_branch2b (BatchNormalizatio (None, 2, 2, 512) 2048 res5a_branch2b[0][0]
____________________________________________________________________________________________________
activation_45 (Activation) (None, 2, 2, 512) 0 bn5a_branch2b[0][0]
____________________________________________________________________________________________________
res5a_branch2c (Conv2D) (None, 2, 2, 2048) 1050624 activation_45[0][0]
____________________________________________________________________________________________________
res5a_branch1 (Conv2D) (None, 2, 2, 2048) 2099200 activation_43[0][0]
____________________________________________________________________________________________________
bn5a_branch2c (BatchNormalizatio (None, 2, 2, 2048) 8192 res5a_branch2c[0][0]
____________________________________________________________________________________________________
bn5a_branch1 (BatchNormalization (None, 2, 2, 2048) 8192 res5a_branch1[0][0]
____________________________________________________________________________________________________
add_15 (Add) (None, 2, 2, 2048) 0 bn5a_branch2c[0][0]
bn5a_branch1[0][0]
____________________________________________________________________________________________________
activation_46 (Activation) (None, 2, 2, 2048) 0 add_15[0][0]
____________________________________________________________________________________________________
res5b_branch2a (Conv2D) (None, 2, 2, 512) 1049088 activation_46[0][0]
____________________________________________________________________________________________________
bn5b_branch2a (BatchNormalizatio (None, 2, 2, 512) 2048 res5b_branch2a[0][0]
____________________________________________________________________________________________________
activation_47 (Activation) (None, 2, 2, 512) 0 bn5b_branch2a[0][0]
____________________________________________________________________________________________________
res5b_branch2b (Conv2D) (None, 2, 2, 512) 2359808 activation_47[0][0]
____________________________________________________________________________________________________
bn5b_branch2b (BatchNormalizatio (None, 2, 2, 512) 2048 res5b_branch2b[0][0]
____________________________________________________________________________________________________
activation_48 (Activation) (None, 2, 2, 512) 0 bn5b_branch2b[0][0]
____________________________________________________________________________________________________
res5b_branch2c (Conv2D) (None, 2, 2, 2048) 1050624 activation_48[0][0]
____________________________________________________________________________________________________
bn5b_branch2c (BatchNormalizatio (None, 2, 2, 2048) 8192 res5b_branch2c[0][0]
____________________________________________________________________________________________________
add_16 (Add) (None, 2, 2, 2048) 0 bn5b_branch2c[0][0]
activation_46[0][0]
____________________________________________________________________________________________________
activation_49 (Activation) (None, 2, 2, 2048) 0 add_16[0][0]
____________________________________________________________________________________________________
res5c_branch2a (Conv2D) (None, 2, 2, 512) 1049088 activation_49[0][0]
____________________________________________________________________________________________________
bn5c_branch2a (BatchNormalizatio (None, 2, 2, 512) 2048 res5c_branch2a[0][0]
____________________________________________________________________________________________________
activation_50 (Activation) (None, 2, 2, 512) 0 bn5c_branch2a[0][0]
____________________________________________________________________________________________________
res5c_branch2b (Conv2D) (None, 2, 2, 512) 2359808 activation_50[0][0]
____________________________________________________________________________________________________
bn5c_branch2b (BatchNormalizatio (None, 2, 2, 512) 2048 res5c_branch2b[0][0]
____________________________________________________________________________________________________
activation_51 (Activation) (None, 2, 2, 512) 0 bn5c_branch2b[0][0]
____________________________________________________________________________________________________
res5c_branch2c (Conv2D) (None, 2, 2, 2048) 1050624 activation_51[0][0]
____________________________________________________________________________________________________
bn5c_branch2c (BatchNormalizatio (None, 2, 2, 2048) 8192 res5c_branch2c[0][0]
____________________________________________________________________________________________________
add_17 (Add) (None, 2, 2, 2048) 0 bn5c_branch2c[0][0]
activation_49[0][0]
____________________________________________________________________________________________________
activation_52 (Activation) (None, 2, 2, 2048) 0 add_17[0][0]
____________________________________________________________________________________________________
avg_pool (AveragePooling2D) (None, 1, 1, 2048) 0 activation_52[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 2048) 0 avg_pool[0][0]
____________________________________________________________________________________________________
fc6 (Dense) (None, 6) 12294 flatten_1[0][0]
====================================================================================================
Total params: 23,600,006
Trainable params: 23,546,886
Non-trainable params: 53,120
____________________________________________________________________________________________________
</code></span>Finally, run the code below to visualize your ResNet50. You can also download a .png picture of your model by going to “File -> Open…-> model.png”.
<span style="color:#000000"><code class="language-python">plot_model(model, to_file=<span style="color:#009900">'model.png'</span>)
SVG(model_to_dot(model).create(prog=<span style="color:#009900">'dot'</span>, format=<span style="color:#009900">'svg'</span>))</code></span>
What you should remember:
- Very deep “plain” networks don’t work in practice because they are hard to train due to vanishing gradients.
- The skip-connections help to address the Vanishing Gradient problem. They also make it easy for a ResNet block to learn an identity function.
- There are two main type of blocks: The identity block and the convolutional block.
- Very deep Residual Networks are built by stacking these blocks together.
References
This notebook presents the ResNet algorithm due to He et al. (2015). The implementation here also took significant inspiration and follows the structure given in the github repository of Francois Chollet:
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun - Deep Residual Learning for Image Recognition (2015)
- Francois Chollet’s github repository: https://github.com/fchollet/deep-learning-models/blob/master/resnet50.py