1.Mini-batch
batch:之前所用的都是将m个样本放在一起组成向量来就行训练,称为batch,所存在的问题:当样本的数量比较庞大的时候,迭代一次所需要的时间比较多
,这种梯度下降算法成为Batch Gradient Descent
为了解决这一问题引入 Mini-batch Gradient descent

它是将全部样本分成t份子集,然后对每一份子集进行一个单一的训练,这样就会大大提高训练速度 例:假设有5000000个样本,分为5000个子集,每个子集1000份样本,则每次可对这1000样本组成的子集进行一个训练
mini batch gradient descent过程:

T次for循环后,称完成了一次epoch,与batch gradient descent不同的是,一个epoch进行T次梯度下降算法,而batch只进行一次
可以进行多次epoch,每次最好顺序打乱,重新分T组mini-batch,这样有利于训练最佳的模型
2.understand mini-batch gradient descent
cost function下降图如下:
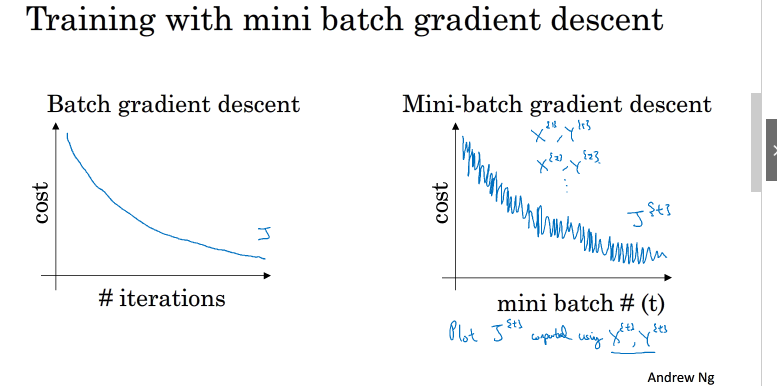
从图中可以看出mini batch 会出现震荡现象,原因:每个子集情况不同,例如可能第一个子集(X {1} ,Y {1} ) 是好的子集,而第二个子集(X {2} ,Y {2} ) 包含了一些噪声noise
mini batch size的选取:

考虑两种极端情况,size=m时,迭代一次所需要的时间过长,前进速度慢; size=1时,称为Stachastic gradient descent,这种情况每个样本的情况不同,所以会产生比较明显的震荡,路线也比较曲折,除此之外,不能使用向量化来提高速度,不过前进速度比较快
选取合适的数量可以融合两者的优点

如果样本数量小于等于2000,可以直接使用batch gradient descent
数量比较大,size的选取一般为2的幂,推荐常用的有64,128,256,512,选择2的幂的原因:计算机存储数据一般都为2的幂,这样设置可以提高运算速度.
3.Exponentially weighted averages
指数加权平均
 θ
θ
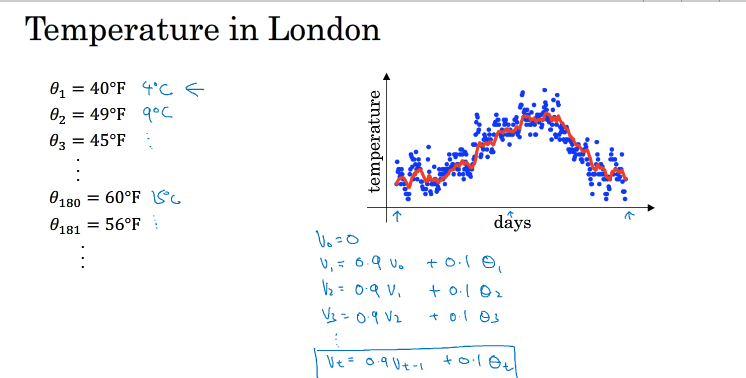
举个例子:上图为伦敦半年的气温曲线,比较震荡,为了能看到整体变化趋势,我们要使它更平滑,我们可以把它移动平均,第t天用Vt=0.9Vt-1+0.1θt,可以得到红色曲线,这种方法叫指数加权平均
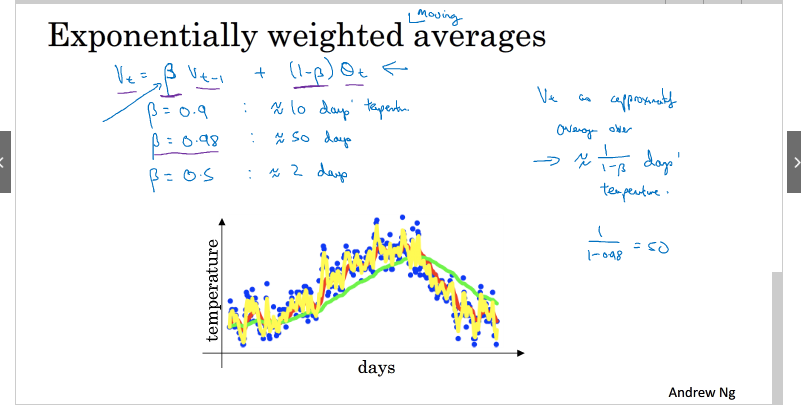
V t =β Vt−1 +(1−β)θt
其中 1/(1-β)为平均的天数
平均的天数越大,曲线越平滑,曲线也会往右移,原因是平均的天数越多,当温度改变时,会减缓这种改变,所以会有一个延迟,造成曲线右移
4.Understand Exponentially weighted averages

指数加权平均展开如上
我们已经知道了指数加权平均的递推公式。实际应用中,为了减少内存的使用,我们可以使用这样的语句来实现指数加权平均算法
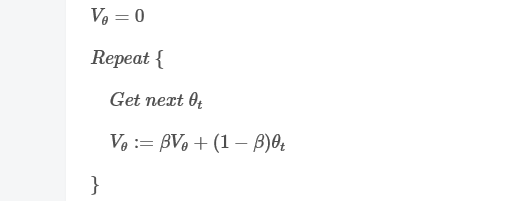
3.Bias correction in exponentially weighted average

之前我们令β=0.98所得到的绿线实际上是经过偏差修正的曲线,原曲线如上图的紫线
偏差修正公式如上图右侧部分:刚开始的时候1-βt,由于t比较小,所以也比较小,修正的比较大,随着t的增加,1-βt越来越接近1,修正效果越来越弱
值得一提的是,机器学习中,偏移校正并不是必须的。因为,在迭代一次次数后(t较大),V t 受初始值影响微乎其微,紫色曲线与绿色曲线基本重合。所以,一般可以忽略初始迭代过程,等到一定迭代之后再取值,这样就不需要进行偏移校正了。
6.Gradient descent with monument
动量梯度下降算法

传统的梯度下降方向只与每一点的方向有关,这样会发生一些震荡,尤其是w和b相差比较大的情况下,导致前进的比较缓慢
如果对梯度进行一个指数加权平均,那么每一点的方向不仅与当前方向有关,也会与当前方向有关,梯度下降会趋近平滑,前进速度会更快速
表达式如下:
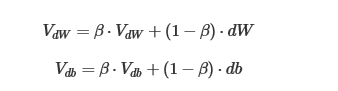
从动量角度分析:dw,db看作加速度,β看作摩擦力,Vdw,Vdb表示现在要求的速度,现在的速度被摩擦力和加速度一起限制,能限制Vdw瞬变
动量梯度下降算法实现如下:

另一种实现方式是上图紫色部分,不过不推荐用那种,那样学习因子α(为α/(1−β) )也会受β影响,调节参数β时,涉及到α,不利于调节
其中β常设为0.9,也就是相当于平均10个梯度
7.RMSprop
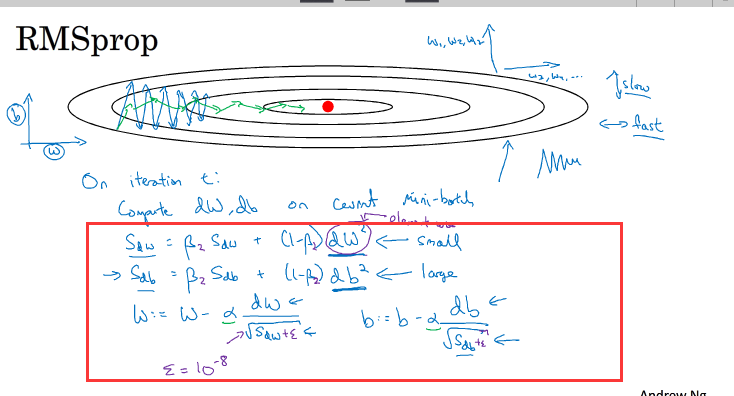
RMSprop是另一种优化梯度下降的算法,它的表达式如上图所示
原理:我们把水平方向看作w,垂直方向看作b,由图中可以看出b方向震荡大,w方向震荡小,即dw小,db大,即上式中的Sdw小,Sdb大
 这样相除以后就会较大,
这样相除以后就会较大,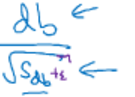 这个相除就较小,所加的ξ是为了防止分母为0
这个相除就较小,所加的ξ是为了防止分母为0
8.Adam optimization algorithm
adam优化算法

算法实现如上图,结合动量梯度下降算法和Rmsprop算法特征
各个参数一般设置如下:

一般只要对β1,β2进行调试
2.9 Learning rate decay
学习率下降

如果我们不对学习率进行一个下降,那么当梯度下降到最优值附近的时候,,步长依然较大,这样就会出现一个震荡,从而离最优值较远
因此我们要对学习率进行一个下降,常用的学习率表达式下降如下:

除此之外还有:

10.The problem of local optima
局部最优问题
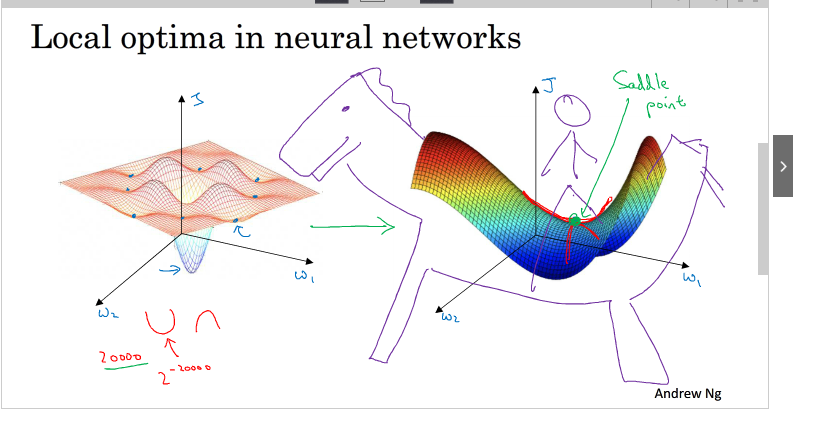
在使用梯度下降算法时可能会发生局部最优情况,如图所示,当参数较多的时候,凹槽也会较多,往往该参数的最优值不是在凹槽底部,而是在其他地方,上图右边绿点梯度为0,并不是最优值,最优值还在其下,如下图
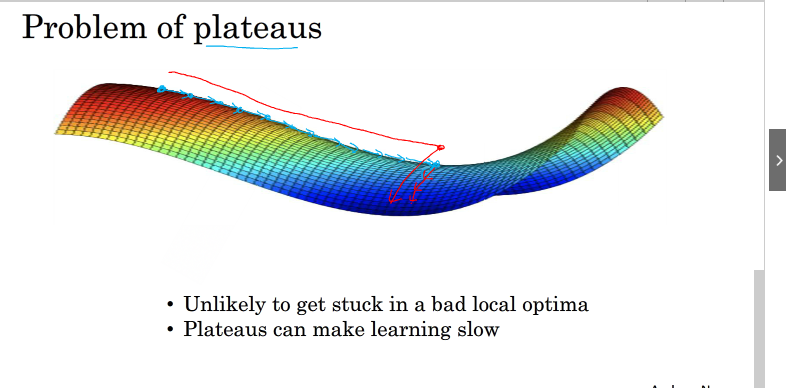
在这种情况下,曲线较为平滑,梯度下降到上图红点所需要的时间长,下降到红点之后,由于随机扰动,梯度一般能够离开saddle point,继续前进,只是在plateaus上花费了太多时间。
当然我们之前所介绍的动量梯度下降算法,RMSprop,Adam能有效解决这个问题