一、降维技术
数据往往拥有大规模的特征。这会导致利用学习算法进行分析时,造成很大的困扰。因此,数据降维就显得尤为重要。
其优点:
- 使得数据集更易使用;
- 降低很多算法的计算开销;
- 去除噪声;
- 使得结果易懂。
常见的降维技术:
- 主成分分析(Principal Component Analysis, PCA )。在PCA中,数据从原来的坐标系转换到了新的坐标系,新坐标系的选择是由数据本身决定的。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴的选择和第一个坐标轴正交且具有最大方差 的方向。该过程一直重复,重复次数为原始数据中特征的数目。我们会发现,大部分方差都包含在最前面的几个新坐标轴中。因此,我们可以忽略余下的坐标轴,即对数据进行了降维处理。
- 因子分析(Factor Analysis)。在因子分析中,我们假设在观察数据的生成中有一些观察不到的隐变量 (latent variable)。假设观察数据是这些隐变量和某些噪声的线性组合。那么隐变量的数据可能比观察数据的数目少,也就是说通过找到隐变量就可以实现数据的降维。因子分析已经应用于社会科学、金融和其他领域中了。
- 独立成分分析(Independent Component Analysis,ICA )。ICA假设数据是从N个数据源生成的,这一点和因子分析有些类似。 假设数据为多个数据源的混合观察结果,这些数据源之间在统计上是相互独立的,而在PCA中只假设数据是不相关的。同因子分析一样, 如果数据源的数目少于观察数据的数目,则可以实现降维过程。
二、主成分分析(PCA)
2.1 基本原理


特征值分析
特征值分析是线性代数中的一个领域,它能够通过数据的一般格式来揭示数据的“ 真实”结构,即我们常说的特征向量和特征值。在等式中,v是特征向量,
是特征值。特征值都是简单的标量值,因此
代表的是:如果特征向量v被某个矩阵A左乘,那么它就 等于某个标量
乘以v。幸运的是,Numpy中有寻找特征向量和特征值的模块linalg , 它有eig()方法,该方法用于求解特征向量和特征值。
2.2 代码实现
# -*- coding: utf-8 -*-
"""
Created on Fri May 18 09:19:29 2018
@author: lizihua
"""
from numpy import *
def loadDataSet(fileName, delim = '\t'):
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [list(map(float,line)) for line in stringArr]
return mat(datArr)
def pca(dataMat, topNfeat = 9999999):
meanVals = mean(dataMat,axis = 0) #求列平均值,若dataMat是m*n,则,meanVals是1*n
meanRemoved = dataMat - meanVals
#每列代表一个方差,求协方差矩阵
covMat = cov(meanRemoved, rowvar = 0) #shape为n*n
#linalg.eig()求特征向量和特征值
eigVals,eigVects = linalg.eig(mat(covMat))
#shape(eigVals):n*1 shape(eigVects):n*n
#将特征值eigVals从小到大排列,并将其排序索引返回给eigValInd
eigValInd = argsort(eigVals)
#选取topNfeat个最大的特征值
eigValInd = eigValInd[:-(topNfeat+1):-1]
#将特征向量按照特征值从小到大排列(按列排),选取前topNfeat个最大特征值对应的特征向量
redEigVects = eigVects[:,eigValInd] #shape为n*topNfeat
#将数据转换到新空间(原始数据*topNfeat个特征向量)
#lowDDataMat是映射到低维空间的数据:shape为 m*topNfeat
lowDDataMat = meanRemoved *redEigVects
#利用降维矩阵,重构原始数据reconMat,
#redEigVects是标准正交矩阵,所以redEigVects*redEigVectS.T是n*n的1矩阵
#reconMat = (lowDDataMat *redEigVects.T) +meanVals
#reconMat = (((dataMat - meanVals) *redEigVects )*redEigVects.T) +meanVals=dataMat
return lowDDataMat,reconMat
if __name__ == "__main__":
dataMat = loadDataSet('testSet.txt')
lowDMat, reconMat = pca(dataMat, 1)
print("lowDMat的形状:",shape(lowDMat))
print("reconMat的形状:",shape(reconMat))
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(dataMat[:,0].flatten().A[0],dataMat[:,1].flatten().A[0],marker = '^',s=90)
ax.scatter(reconMat[:,0].flatten().A[0],reconMat[:,1].flatten().A[0],marker = 'o',s=50,c='red')
2.3 结果显示
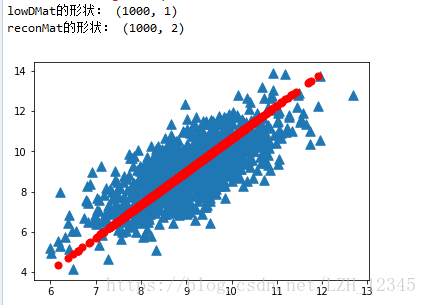
三、小结
降维技术使得数据变得更易使用, 并且它们往往能够去除数据中的噪声, 使得其他机器学习任务更加精确。降维往往作为预处理步骤, 在数据应用到其他算法之前清洗数据。有很多技术可以用于数据降维,在这些技术中,独立成分分析、因子分析和主 成分分析比较流行,其中又以主成分分析应用最广泛。
PCA可以从数据中识别其主要特征,它是通过沿着数据最大方差方向旋转坐标轴来实现的。选择方差最大的方向作为第一条坐标轴,后续坐标轴则与前面的坐标轴正交。协方差矩阵上的特征值分析可以用一系列的正交坐标轴来获取。