一.概念
LLE:Locally linear embedding(局部线性嵌入算法)是一种非线性降维算法,它能够使降维后的数据较好地保持原有流形结构。LLE可以说是流形学习方法最经典的工作之一。和传统的PCA,LDA等关注样本方差的降维方法相比,LLE关注于降维时保持样本局部的线性特征,由于LLE在降维时保持了样本的局部特征。
二.算法
LLE算法认为每一个数据点都可以由其近邻点的线性加权组合构造得到。算法的主要步骤分为三步:(1)寻找每个样本点的k个近邻点;(2)由每个样本点的近邻点计算出该样本点的局部重建权值矩阵;(3)由该样本点的局部重建权值矩阵和其近邻点计算出该样本点的输出值。
三.sklearn提供的API
sklearn的manifold提供了LLE方法(LocallyLinearEmbedding)
主要参数:
def __init__(self, n_neighbors=5, n_components=2, reg=1E-3,
eigen_solver='auto', tol=1E-6, max_iter=100,
method='standard', hessian_tol=1E-4, modified_tol=1E-12,
neighbors_algorithm='auto', random_state=None, n_jobs=1):
self.n_neighbors = n_neighbors
self.n_components = n_components
self.reg = reg
self.eigen_solver = eigen_solver
self.tol = tol
self.max_iter = max_iter
self.method = method
self.hessian_tol = hessian_tol
self.modified_tol = modified_tol
self.random_state = random_state
self.neighbors_algorithm = neighbors_algorithm
self.n_jobs = n_jobs
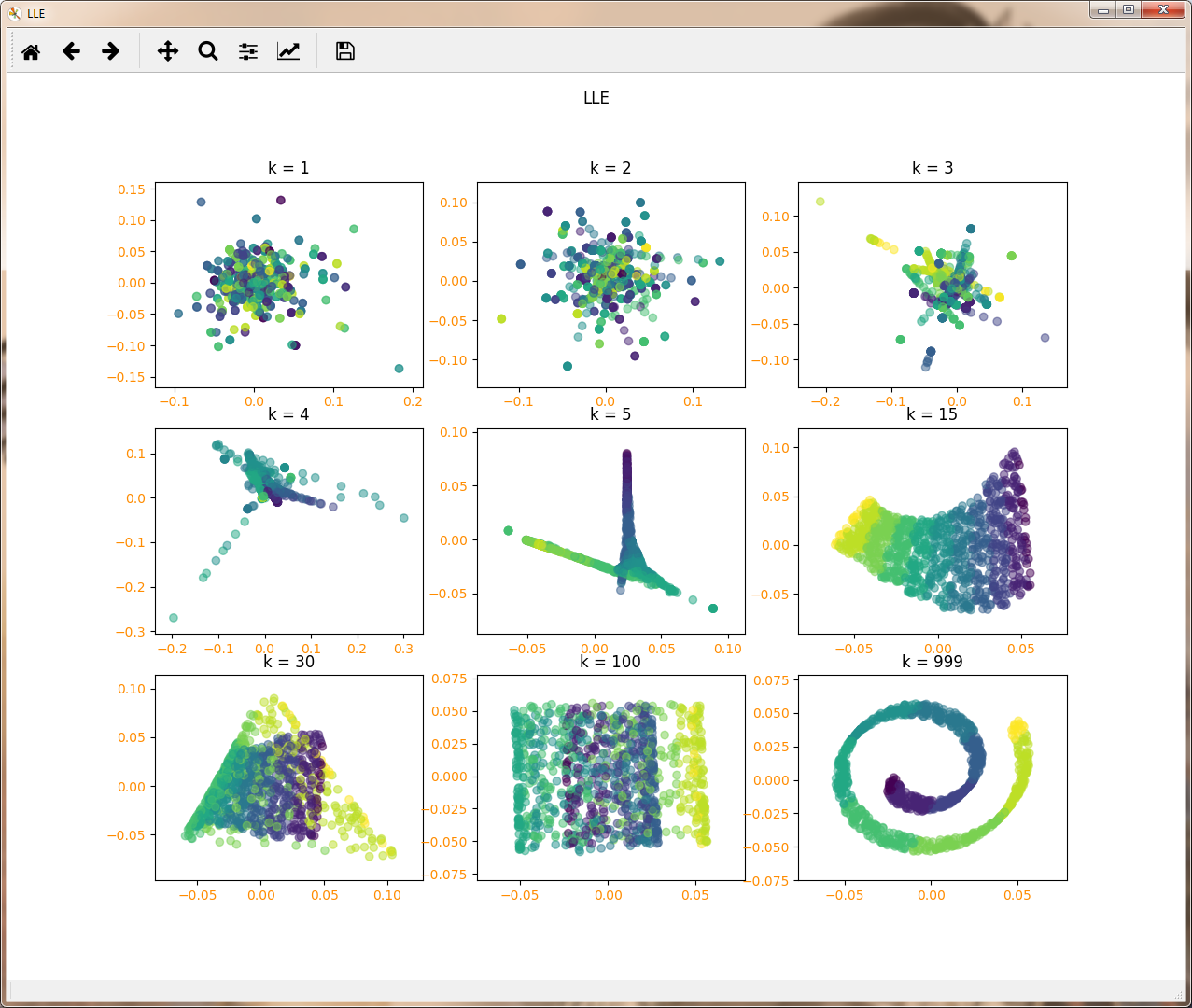
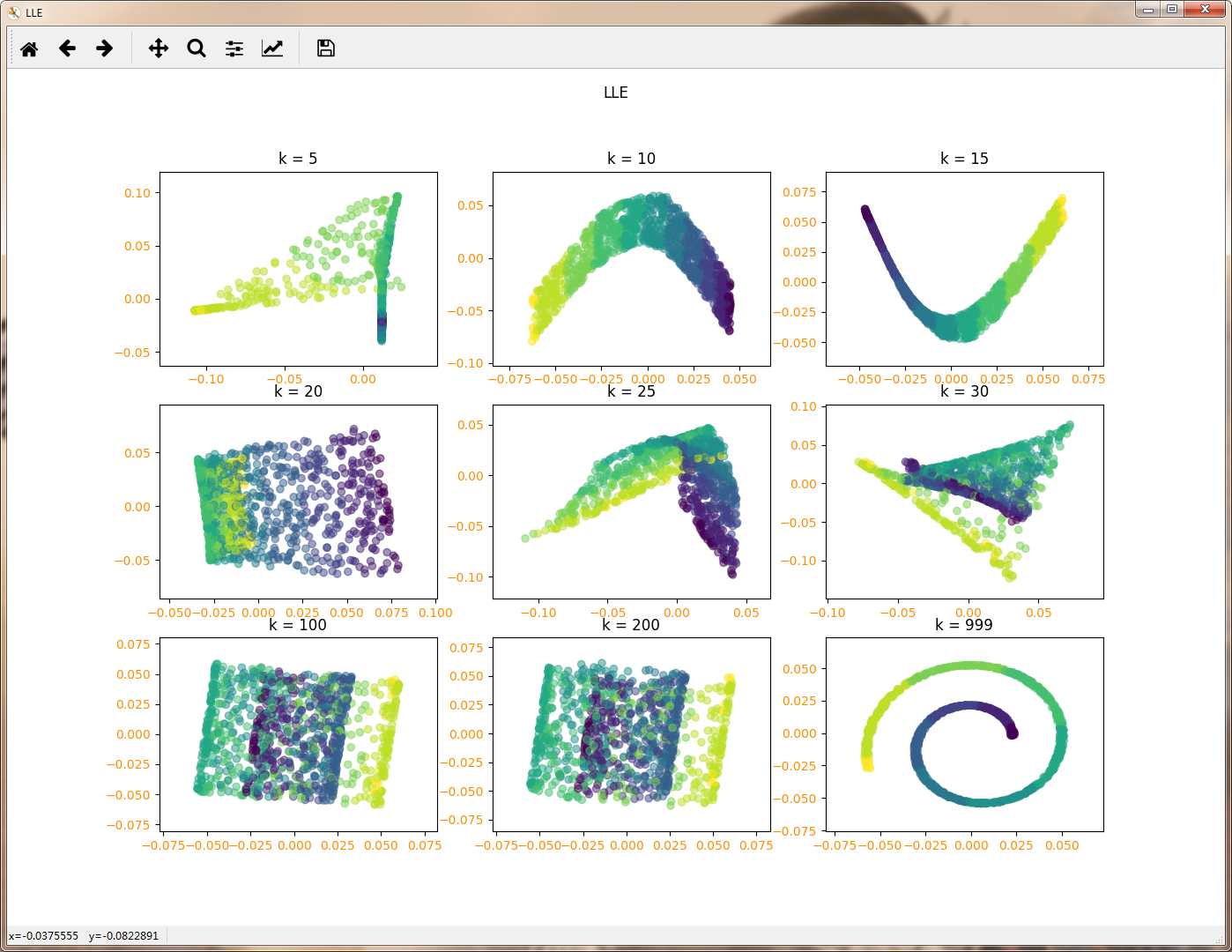
n_neighbors:即我们搜索样本的近邻的个数,最重要的就是这个,默认是5。 n_neighbors个数越大,则建立样本局部关系的时间会越大,也就意味着算法的复杂度会增加。当然n_neighbors个数越大,则降维后样本的局部关系会保持的更好。在下一节我们可以通过具体的例子看出这一点。一般来说,如果算法运行时间可以接受,我们可以尽量选择一个比较大一些的n_neighbors。
n_components:即我们降维到的维数。如果我们降维的目的是可视化,则一般可以选择2-5维。
reg :正则化系数,在n_neighbors大于n_components时,即近邻数大于降维的维数时,由于我们的样本权重矩阵不是满秩的,LLE通过正则化来解决这个问题。默认是0.001。一般不用管这个参数。当近邻数远远的大于降维到的维数时可以考虑适当增大这个参数。
eigen_solver:特征分解的方法。有‘arpack’和‘dense’两者算法选择。当然也可以选择'auto'让scikit-learn自己选择一个合适的算法。‘arpack’和‘dense’的主要区别是‘dense’一般适合于非稀疏的矩阵分解。而‘arpack’虽然可以适应稀疏和非稀疏的矩阵分解,但在稀疏矩阵分解时会有更好算法速度。当然由于它使用一些随机思想,所以它的解可能不稳定,一般需要多选几组随机种子来尝试。
method: 即LLE的具体算法。LocallyLinearEmbedding支持4种LLE算法,分别是'standard'对应我们标准的LLE算法,'hessian'对应原理篇讲到的HLLE算法,'modified'对应原理篇讲到的MLLE算法,‘ltsa’对应原理篇讲到的LTSA算法。默认是'standard'。一般来说HLLE/MLLE/LTSA算法在同样的近邻数n_neighbors情况下,运行时间会比标准的LLE长,当然降维的效果会稍微好一些。如果你对降维后的数据局部效果很在意,那么可以考虑使用HLLE/MLLE/LTSA或者增大n_neighbors,否则标准的LLE就可以了。需要注意的是使用MLLE要求n_neighbors > n_components,而使用HLLE要求n_neighbors > n_components * (n_components + 3) / 2
neighbors_algorithm:这个是k近邻的搜索方法,和KNN算法的使用的搜索方法一样。算法一共有三种,第一种是蛮力实现,第二种是KD树实现,第三种是球树实现。这三种方法在K近邻法(KNN)原理小结中都有讲述,如果不熟悉可以去复习下。对于这个参数,一共有4种可选输入,‘brute’对应第一种蛮力实现,‘kd_tree’对应第二种KD树实现,‘ball_tree’对应第三种的球树实现, ‘auto’则会在上面三种算法中做权衡,选择一个拟合最好的最优算法。需要注意的是,如果输入样本特征是稀疏的时候,无论我们选择哪种算法,最后scikit-learn都会去用蛮力实现‘brute’。个人的经验,如果样本少特征也少,使用默认的 ‘auto’就够了。 如果数据量很大或者特征也很多,用"auto"建树时间会很长,效率不高,建议选择KD树实现‘kd_tree’,此时如果发现‘kd_tree’速度比较慢或者已经知道样本分布不是很均匀时,可以尝试用‘ball_tree’。而如果输入样本是稀疏的,无论你选择哪个算法最后实际运行的都是‘brute’。
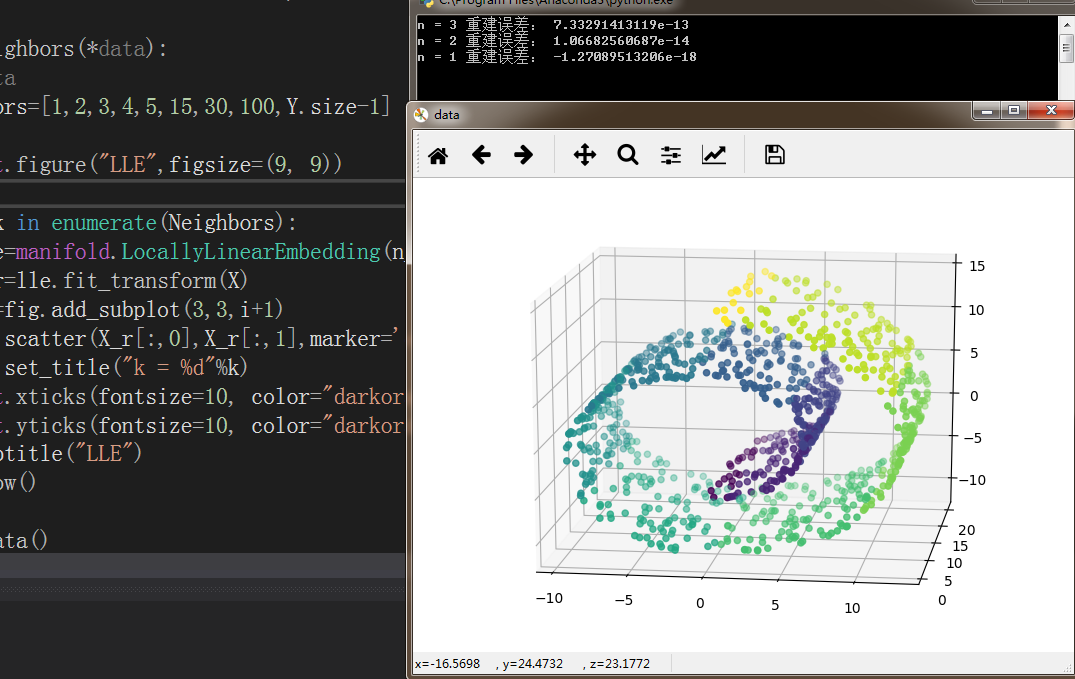
实例代码:瑞士卷
import numpy as np
import operator
import matplotlib.pyplot as plt
from sklearn import datasets,decomposition,manifold
from itertools import cycle
from mpl_toolkits.mplot3d import Axes3D
def load_data():
swiss_roll =datasets.make_swiss_roll(n_samples=1000)
return swiss_roll[0],np.floor(swiss_roll[1])
def LLE_components(*data):
X,Y=data
for n in [3,2,1]:
lle=manifold.LocallyLinearEmbedding(n_components=n)
lle.fit(X)
print("n = %d 重建误差:"%n,lle.reconstruction_error_)
def LLE_neighbors(*data):
X,Y=data
Neighbors=[1,2,3,4,5,15,30,100,Y.size-1]
fig=plt.figure("LLE",figsize=(9, 9))
for i,k in enumerate(Neighbors):
lle=manifold.LocallyLinearEmbedding(n_components=2,n_neighbors=k,eigen_solver='dense')
X_r=lle.fit_transform(X)
ax=fig.add_subplot(3,3,i+1)
ax.scatter(X_r[:,0],X_r[:,1],marker='o',c=Y,alpha=0.5)
ax.set_title("k = %d"%k)
plt.xticks(fontsize=10, color="darkorange")
plt.yticks(fontsize=10, color="darkorange")
plt.suptitle("LLE")
plt.show()
X,Y=load_data()
fig = plt.figure('data')
ax = Axes3D(fig)
ax.scatter(X[:, 0], X[:, 1], X[:, 2],marker='o',c=Y)
LLE_components(X,Y)
LLE_neighbors(X,Y)
四.总结
LLE算法计算复杂度相对较小,实现也算比较容易。且可以学习任意维的局部线性的低维流形。但是对数据的流形分布特征有严格的要求。比如不能是闭合流形,不能是稀疏的数据集,不能是分布不均匀的数据集等等。通过上述代码也能看出,算法对最近邻样本数的选择非常敏感,不同的最近邻数对最后的降维结果有很大影响。
五.相关学习资源
http://blog.csdn.net/xiaomibaozi/article/details/69951477