在低维下,数据更容易进行处理。其相关特征可能在数据中明确地显示出来。通常而言,我们再应用其他机器学习算法之前,必须先识别出其相关特征。
13.1 降维技术
始终贯穿本书的一个难题就是对数据和结果的展示,这是因为文字图像是二维的,而在通常情况下数据不是如此。有时我们会显示三维图像或者只显示其相关特征,但是数据往往拥有超出显示能力的更多特征。数据显示并非大规模特征下的唯一难题,对数据进行简化还有如下一系列原因:
- 使得数据集更易使用;
- 降低很多算法的计算开销;
- 去除噪声;
- 使得结果易懂。
在已标注与未标注的数据上都有降维技术。这里我们将主要关注为标注数据上的降维技术,该技术同时也可以应用于已标注的数据。
第一种降维的方法称为主成分分析(PCA)。在PCA中,数据从原来的坐标系转换到了新的坐标系,新坐标系的选择是由数据本身决定的。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴的选择和第一个坐标轴正交且具有最大方差的方向。该过程一直重复,重复次数为原始数据中特征的数目。我们会发现,大部分方差都包含在最前面的几个新坐标轴中。因此,我们可以忽略余下的坐标轴,即对数据进行了降维处理。
另外一种降维技术是因子分析。在因子分析中,我们假设在观察数据的生成中有一些观察不到的隐变量。假设观察数据是这些隐变量和某些噪声的线性组合。那么隐变量的数据可能比观察数据的数目少,也就是说通过找到隐变量就可以实现数据的降维。因子分析已经应用于社会科学、金融和其他领域中了。
还有一种降维技术就是独立成分分析(ICA)。ICA假设数据是从n个数据源生成的,这一点和因子分析有些类似。假设数据为多个数据源的混合观察结果这些数据源之间在统计上是相互独立的,而在PCA中只假设数据是不相关的。同因子分析一样如果数据源的数目少于观察数据的数目,则可以实现降维过程。
13.2 PCA
主成分分析
优点:降低数据的复杂性,识别最重要的多个特征。
缺点:不一定需要,且可能损失有用信息。
适用数据类型:数值型数据。
13.2.1 移动坐标轴
考虑下图中大量数据点。如果要求我们画出一条直线,这条线要尽可能覆盖这些点,那么最长的得线可能是哪条?下图3条直线中B最长。在PCA中,我们对数据的坐标进行了旋转,该旋转的过程取决于数据的本身。第一条坐标轴旋转到覆盖数据的最大方差位置,即图中的直线B。数据的最大方差给出了数据的最重要信息。
在选择了覆盖数据最大差异性的坐标轴之后,我们选择了第二条坐标轴。假如该坐标轴与第一条坐标轴垂直,它就是覆盖数据次大差异性的坐标轴。这里更严谨的说法就是正交。当然,在二维平面下,垂直和正交是一回事。图中直线C就是第二条坐标轴。利用PCA我们将数据坐标轴旋转至数据角度上的那些最重要的方向。

坐标轴的旋转并没有减少数据的维度。 下图包含着3个不同的类别。要区分这3个类别,可以使用决策树。我们还记得决策树每次都是基于一个特征来做决策的。可以发现,在x轴上能够找到一些值,这些值能够很好地将这3个类别分开。这样,我们就可能得到一些规则,比如当(x≤5)时,数据属于类别0。如果使用SVM这样稍微复杂一点的分类器,我们就会得到很好地分类面和分类规则,比如当(w0*x+w1*y+b)>0时,数据也属于类别0。SVM可能比决策树得到更好的分类间隔,但是分类超平面却很难解释。
通过PCA进行降维处理,我们就可以同时获得SVM和决策树的优点:一方面,得到了和决策树一-样简单的分类器,同时分类间隔和SVM一样好。考察第二张图,其中的数据来自于上面的图并经PCA转换之后绘制而成的。如果仅使用原始数据,那么这里的间隔会比决策树的间隔更大。另外,由于只需要考虑一维信息,因此数据就可以通过比SVM简单得多的很容易采用的规则进行区分。

在上图中,我们只需要一维信息即可,因为另一维信息只是对分类缺乏贡献的噪声数据。在二维平面下,这一点看上去微不足道,但是如果在高维空间下则意义重大。
我们已经对PCA的基本过程做出了简单的阐述,接下来就可以通过代码来实现PCA过程。前面曾提到的第一个主成分就是从数据差异性最大(即方差最大)的方向提取出来的,第二个主成分则来自于数据差异性次大的方向,并且该方向与第一个主成分方向正交。通过数据集的协方差矩阵及其特征值分析,我们就可以求得这些主成分的值。
一旦得到了协方差矩阵的特征向量,我们就可以保留最大的N个值。这些特征向量也给出了N个最重要特征的真实结构。我们可以通过将数据乘上这N个特征向量而将它转换到新的空间。
13.2.2 在NumPy中实现PCA
将数据转换成前N个主成分的伪码大致如下:

建立一个名为pca.py的文件并加入下列代码:
from numpy import *
def loadDataSet(fileName, delim='\t'):
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [list(map(float,line)) for line in stringArr]
return mat(datArr)
def pca(dataMat, topNfeat=9999999):
meanVals = mean(dataMat, axis=0)
meanRemoved = dataMat - meanVals #remove mean
covMat = cov(meanRemoved, rowvar=0)
eigVals,eigVects = linalg.eig(mat(covMat))
eigValInd = argsort(eigVals) #sort, sort goes smallest to largest
eigValInd = eigValInd[:-(topNfeat+1):-1] #cut off unwanted dimensions
redEigVects = eigVects[:,eigValInd] #reorganize eig vects largest to smallest
lowDDataMat = meanRemoved * redEigVects#transform data into new dimensions
reconMat = (lowDDataMat * redEigVects.T) + meanVals
return lowDDataMat, reconMat代码包含了通常的NumPy导入和 loadDataSet() 函数。这里的 loadDataSet() 函数和前面章节中的版本有所不同,因为这里使用了两个list comprehension来构建矩阵。
pca() 函数有两个参数:第一个参数是用于进行PCA操作的数据集,第二个参数topNfeat则是一个可选参数,即应用的N个特征。如果不指定topNfeat的值,那么函数就会返回前9999999个特征,或者原始数据中的全部特征。
首先计算并减去原始数据集的平均值。然后,计算协方差矩阵及其特征值,接着利用 argsort() 函数对特征值进行从小到大的排序。根据特征值排序结果的逆序就可以得到topNfeat个最大的特征向量。这些特征向量将构成后面对数据进行转换的矩阵,该矩阵则利用N个特征将原始数据转换到新空间中。最后,原始数据被重构后返回用于调试,同时降维之后的数据集也被返回了。
import pca
from numpy import *
import matplotlib
import matplotlib.pyplot as plt
# 在文件中加入一个由1000个数据点组成的数据集,并通过如下命令将该数据集调入内存
dataMat = pca.loadDataSet('testSet.txt')
# 在数据集上进行PCA操作
lowDMat,reconMat = pca.pca(dataMat,1)
# lowDMat包含了降维之后的矩阵,这里是个一维矩阵,进行检查
print(shape(lowDMat))
# 通过如下命令将将为后的数据和原始数据一起绘制出来
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(dataMat[:,0].flatten().A[0],dataMat[:,1].flatten().A[0],marker='^',s=90)
ax.scatter(reconMat[:,0].flatten().A[0],reconMat[:,1].flatten().A[0],marker='o',s=50,c='red')
plt.show()
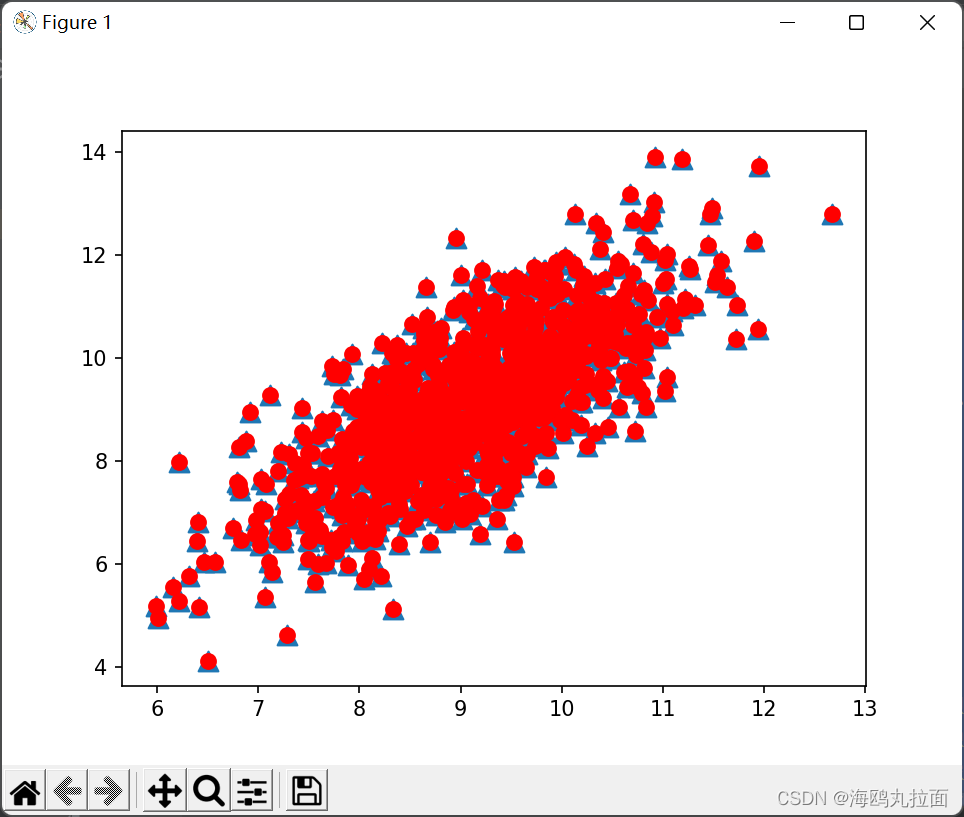
作图为topNfeat设定为1时的图像,返回了1个最大的特征向量,即红色圆点数据。右图返回了原始数据中的全部特征,蓝色三角形点均被红色圆点标记。
13.3 示例:利用PCA对半导体制造数据降维
选用的数据中包含很多缺失值,缺失值是以NaN(Not a Number)标识的。
def replaceNanWithMean():
datMat = loadDataSet('secom.data', ' ')
numFeat = shape(datMat)[1]
for i in range(numFeat):
meanVal = mean(datMat[nonzero(~isnan(datMat[:,i].A))[0],i]) #计算所有非NaN的平均值
datMat[nonzero(isnan(datMat[:,i].A))[0],i] = meanVal #将所有NaN置为平均值代码首先打开了数据集并计算出了其特征的数目,然后再在所有的特征上进行循环。对于每个特征,首先计算出那些非NaN值的平均值,然后将所有NaN替换为平均值。
去除所有NaN,接下来考虑在该函数集上应用PCA。首先确认所需特征和可以去除特征的数目。PCA会给出数据中所包含的信息量。
import pca
from numpy import *
# 将数据集中所有的NaN替换成平均值
dataMat = pca.replaceNanWithMean()
# 去除均值
meanVals = mean(dataMat,axis=0)# 纵向平均值
meanRemoved = dataMat - meanVals
# 计算协方差矩阵
covMat = cov(meanRemoved,rowvar=0)
eigVals,eigVects = linalg.eig(mat(covMat))
print(eigVals)
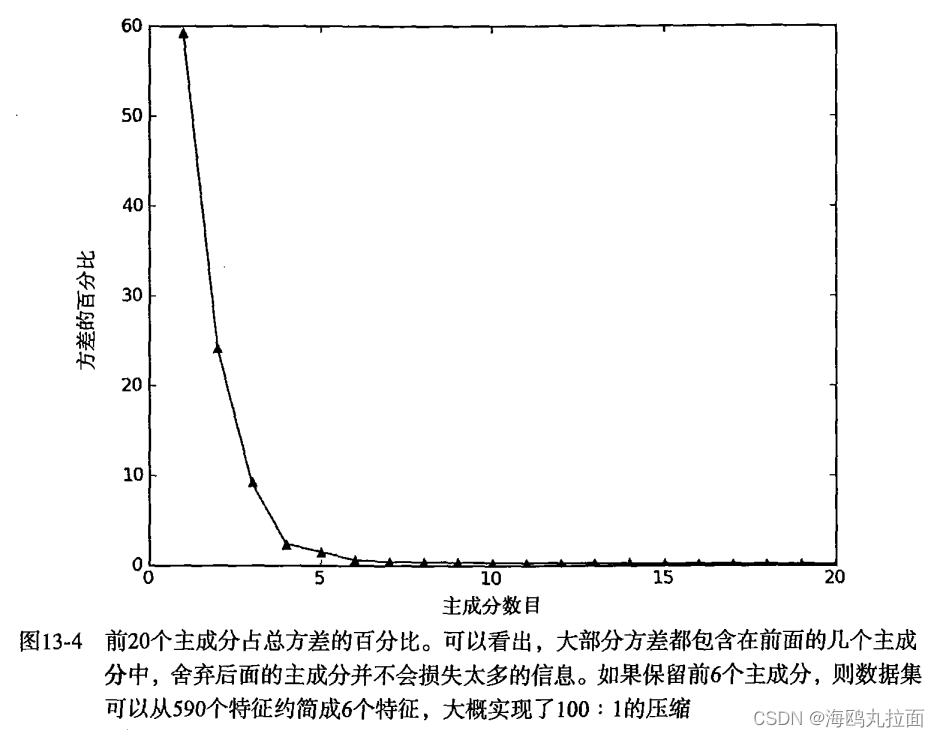
运行结果会得到许多值。其中有超过20%的特征值都是0,这意味着这些特征都是其他特征的副本,也就是说,它们可以通过其他特征来表示,而本身并不提供额外的信息。最前面15个值的数量级大于105,实际上那以后的值都变得非常小。这告诉我们只有部分重要特征,重要特征的数目也很快就会下降。数值中有一些小的负值,它们主要源自数值误差,应该四舍五入成0。
下图中给出了总方差的百分比,可以发现,在开始几个主成分之后,方差就会迅速下降。
13.4 小结
降维技术使得数据变得更易使用,并且它们往往能够去除数据中的噪声,使得其他机器学习任务更加精确。降维往往作为预处理步骤,在数据应用到其他算法之前清洗数据。有很多技术可以用于数据降维,在这些技术中,独立成分分析、因子分析和主成分分析比较流行,其中又以主成分分析应用最广泛。
PCA可以从数据中识别其主要特征,它是通过沿着数据最大方差方向旋转坐标轴来实现的。选择方差最大的方向作为第一条坐标轴,后续坐标轴则与前面的坐标轴正交。协方差矩阵上的特征值分析可以用一系列的正交坐标轴来获取。