主成份分析,简称为PCA,是一种非监督学习算法,经常被用来进行
通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,选择特征值最大(即方差最大)的k个特征所对应的特征向量组成的矩阵。这样就可以将数据矩阵转换到新的空间当中,实现数据特征的降维。
基于特征值分解协方差矩阵实现PCA算法
基于SVD分解协方差矩阵实现PCA算法。
特征值分解和奇异值分解在机器学习中都是很常见的矩阵分解算法。两者有着很紧密的关系,特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征。
如果一个向量v是矩阵A的特征向量,将一定可以表示成下面的形式:
A
v
=
λ
v
Av=\lambda v
A v = λ v
λ
\lambda
λ
v
v
v
一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。比如说下面的这个矩阵:
M
=
[
3
0
0
1
]
M=\begin{bmatrix} 3 & 0\\ 0 & 1 \end{bmatrix}
M = [ 3 0 0 1 ]
[
3
0
0
1
]
[
x
y
]
=
[
3
x
y
]
\begin{bmatrix} 3 & 0\\ 0 & 1 \end{bmatrix}\begin{bmatrix} x\\ y \end{bmatrix}=\begin{bmatrix} 3x\\ y \end{bmatrix}
[ 3 0 0 1 ] [ x y ] = [ 3 x y ]
[
3
0
0
1
]
\begin{bmatrix} 3 & 0\\ 0 & 1 \end{bmatrix}
[ 3 0 0 1 ]
对于矩阵A,有一组特征向量v,将这组向量进行正交单位化,就能得到一组正交单位向量。特征值分解,就是将矩阵A分解为如下式:
A
=
Q
Σ
Q
−
1
A=Q\Sigma Q^{-1}
A = Q Σ Q − 1
Σ
\Sigma
Σ
Σ
\Sigma
Σ
当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,这个线性变换可能没法通过图片来表示,但是可以想象,这个变换也同样有很多的变化方向,我们通过特征值分解得到的钱N个特征向量,就对应了这个矩阵最重要的N个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵变换,也就是之前说的:提取这个矩阵最重要的特征 。
**总结:**特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多么重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多事情。不过,特征值分解也有很多局限,比如说变换的矩阵必须是方阵。
这里我们用一个简单的方阵来说明特征值分解的步骤。我们的方阵A定义为:
A
=
[
−
1
1
0
−
4
3
0
1
0
2
]
A=\begin{bmatrix} -1 & 1 & 0\\ -4 & 3 & 0\\ 1 & 0 & 2 \end{bmatrix}
A = ⎣ ⎡ − 1 − 4 1 1 3 0 0 0 2 ⎦ ⎤
∣
A
−
λ
E
∣
=
[
−
1
−
λ
1
0
−
4
3
−
λ
0
0
1
0
2
−
λ
]
=
(
2
−
λ
)
[
−
1
−
λ
1
−
4
3
−
λ
]
=
(
2
−
λ
)
(
λ
−
1
)
2
=
0
|A-\lambda E|=\begin{bmatrix} -1-\lambda & 1 & 0\\ -4 & 3-\lambda 0 & 0\\ 1 & 0 & 2-\lambda \end{bmatrix}=(2-\lambda)\begin{bmatrix} -1-\lambda & 1 \\ -4 & 3-\lambda \end{bmatrix}=(2-\lambda)(\lambda-1)^2=0
∣ A − λ E ∣ = ⎣ ⎡ − 1 − λ − 4 1 1 3 − λ 0 0 0 0 2 − λ ⎦ ⎤ = ( 2 − λ ) [ − 1 − λ − 4 1 3 − λ ] = ( 2 − λ ) ( λ − 1 ) 2 = 0
特征值为
λ
=
2
,
1
(
重
数
是
1
)
\lambda=2,1(重数是1)
λ = 2 , 1 ( 重 数 是 1 )
然后,把每个特征值
λ
\lambda
λ
(
A
−
λ
E
)
x
=
0
(A-\lambda E)x=0
( A − λ E ) x = 0
当
λ
=
2
\lambda=2
λ = 2
(
A
−
2
E
)
x
=
0
(A-2E)x=0
( A − 2 E ) x = 0
(
A
−
2
E
)
=
[
−
3
1
0
−
4
1
0
1
0
0
]
→
[
1
0
0
0
1
0
0
0
0
]
(A-2E)=\begin{bmatrix} -3 & 1 & 0\\ -4 & 1 & 0\\ 1 & 0 & 0 \end{bmatrix}\rightarrow \begin{bmatrix} 1 & 0 & 0\\ 0 & 1 & 0\\ 0 & 0 & 0 \end{bmatrix}
( A − 2 E ) = ⎣ ⎡ − 3 − 4 1 1 1 0 0 0 0 ⎦ ⎤ → ⎣ ⎡ 1 0 0 0 1 0 0 0 0 ⎦ ⎤
解得
x
1
=
0
,
x
2
=
0
x_1=0,x_2=0
x 1 = 0 , x 2 = 0
p
1
=
[
0
0
1
]
p_1=\begin{bmatrix} 0\\ 0\\ 1 \end{bmatrix}
p 1 = ⎣ ⎡ 0 0 1 ⎦ ⎤
当
λ
=
1
\lambda=1
λ = 1
(
A
−
2
E
)
x
=
0
(A-2E)x=0
( A − 2 E ) x = 0
(
A
−
E
)
=
[
−
2
1
0
−
4
2
0
1
0
1
]
→
[
1
0
1
0
1
2
0
0
0
]
(A-E)=\begin{bmatrix} -2 & 1 & 0\\ -4 & 2 & 0\\ 1 & 0 & 1 \end{bmatrix}\rightarrow \begin{bmatrix} 1 & 0 & 1\\ 0 & 1 & 2\\ 0 & 0 & 0 \end{bmatrix}
( A − E ) = ⎣ ⎡ − 2 − 4 1 1 2 0 0 0 1 ⎦ ⎤ → ⎣ ⎡ 1 0 0 0 1 0 1 2 0 ⎦ ⎤
解得
x
1
+
x
3
=
0
,
x
2
+
2
x
3
=
0
x_1+x_3=0,x_2+2x_3=0
x 1 + x 3 = 0 , x 2 + 2 x 3 = 0
p
1
=
[
−
1
−
2
1
]
p_1=\begin{bmatrix} -1\\ -2\\ 1 \end{bmatrix}
p 1 = ⎣ ⎡ − 1 − 2 1 ⎦ ⎤
最后,方阵A的特征值分解为:
A
=
Q
∑
Q
−
1
=
[
0
−
1
−
1
0
−
2
−
2
1
1
1
]
[
2
0
0
0
1
0
0
0
1
]
[
0
−
1
−
1
0
−
2
−
2
1
1
1
]
−
1
A=Q\sum Q^{-1}=\begin{bmatrix} 0 & -1 & -1\\ 0 & -2 & -2\\ 1 & 1 & 1 \end{bmatrix}\begin{bmatrix} 2 & 0 & 0\\ 0 & 1 & 0\\ 0 & 0 & 1 \end{bmatrix}\begin{bmatrix} 0 & -1 & -1\\ 0 & -2 & -2\\ 1 & 1 & 1 \end{bmatrix}^{-1}
A = Q ∑ Q − 1 = ⎣ ⎡ 0 0 1 − 1 − 2 1 − 1 − 2 1 ⎦ ⎤ ⎣ ⎡ 2 0 0 0 1 0 0 0 1 ⎦ ⎤ ⎣ ⎡ 0 0 1 − 1 − 2 1 − 1 − 2 1 ⎦ ⎤ − 1
我们前面讲了很多特征值、特征向量和特征值分解,而且基于我们以前学习的线性代数知识、利用特征值分解提取特征矩阵是一个容易理解并且便于实现的方法。但是为什么还存在奇异值分解呢?特征值分解最大的问题是只能针对方阵,即
n
∗
n
n*n
n ∗ n
举个例子:
奇异值分解是一个能使用与任意矩阵的一种分解方式,对于任意矩阵A总是存在一个奇异值分解:
A
=
U
Σ
V
T
A=U\Sigma V^T
A = U Σ V T
假设A是一个mn的矩阵,那么得到的U是一个m m的方阵,U里面的正交向量被称为左奇异向量。
Σ
\Sigma
Σ n的矩阵,
Σ
\Sigma
Σ
V
T
V^T
V T n的矩阵,它里面的正交向量被称为右奇异值向量。而且一般来讲,我们会将
Σ
\Sigma
Σ
**思考:**虽说上面奇异值分解等式成立,但是如何求得左奇异值向量、右奇异值向量和奇异值呢?
(
A
T
A
)
v
i
=
λ
i
v
i
(A^TA)v_i=\lambda_iv_i
( A T A ) v i = λ i v i
v
i
v_i
v i
(
A
A
T
)
u
i
=
λ
i
u
i
(AA^T)u_i=\lambda_iu_i
( A A T ) u i = λ i u i
u
i
u_i
u i
A
T
A
A^TA
A T A
A
A
T
AA^T
A A T
A
=
U
Σ
V
T
⇒
A
T
=
V
Σ
T
U
T
⇒
A
T
A
=
V
Σ
T
U
T
U
Σ
V
T
=
V
Σ
2
V
T
A=U\Sigma V^T\Rightarrow A^T=V\Sigma^TU^T\Rightarrow A^TA=V\Sigma^TU^TU\Sigma V^T=V\Sigma^2V^T
A = U Σ V T ⇒ A T = V Σ T U T ⇒ A T A = V Σ T U T U Σ V T = V Σ 2 V T
上式证明中使用了
U
T
U
=
I
,
Σ
T
Σ
=
Σ
2
U^TU=I,\Sigma^T\Sigma=\Sigma^2
U T U = I , Σ T Σ = Σ 2
A
T
A
A^TA
A T A
A
A
T
AA^T
A A T
补充定义:
U
∈
M
n
(
R
)
满
足
U
T
U
=
I
,
则
U
是
实
正
交
矩
阵
U\in M_n(R)满足U^TU=I,则U是实正交矩阵
U ∈ M n ( R ) 满 足 U T U = I , 则 U 是 实 正 交 矩 阵
a)第一种:
A
=
U
Σ
V
T
⇒
A
V
⇒
U
Σ
V
T
V
⇒
A
V
=
U
Σ
⇒
A
v
i
=
σ
u
i
⇒
σ
i
=
A
v
i
u
i
A=U\Sigma V^T\Rightarrow AV\Rightarrow U\Sigma V^TV\Rightarrow AV = U\Sigma\Rightarrow Av_i=\sigma u_i\Rightarrow \sigma_i=\frac{Av_i}{u_i}
A = U Σ V T ⇒ A V ⇒ U Σ V T V ⇒ A V = U Σ ⇒ A v i = σ u i ⇒ σ i = u i A v i
b)第二种
通过上面的证明,我们还可以看出,特征值举证等于奇异值矩阵的平方,也就是说特征值和奇异值满足如下关系:
σ
i
=
λ
i
\sigma_i=\sqrt{\lambda_i}
σ i = λ i
σ
i
\sigma_i
σ i
σ
i
\sigma_i
σ i
Σ
\Sigma
Σ
思考: n的矩阵A,你把它分解成m m的矩阵U、mn的矩阵
Σ
\Sigma
Σ n的矩阵
V
T
V^T
V T
这三个矩阵中任何一个的维度似乎一点也不比A的维度小,而且还要做两次矩阵的乘法,这不是把简单的事情变得更加复杂了吗?
答案:
Σ
\Sigma
Σ
σ
i
\sigma_i
σ i
A
m
∗
n
≈
U
m
∗
n
Σ
r
∗
r
V
r
∗
n
T
A_{m*n}\approx U_{m*n}\Sigma_{r*r}V_{r*n}^T
A m ∗ n ≈ U m ∗ n Σ r ∗ r V r ∗ n T 所以在奇异值分解中r的取值很重要,就是在计算精度和事件空间之间做选择。
这里我们用一个简单的矩阵来说明奇异值分解的步骤。我们的矩阵A定义为:
[
0
1
1
1
1
0
]
\begin{bmatrix} 0 & 1 \\ 1 & 1\\ 1 & 0 \end{bmatrix}
⎣ ⎡ 0 1 1 1 1 0 ⎦ ⎤
A
T
A
A^TA
A T A
A
A
T
AA^T
A A T
A
T
A
=
[
0
1
1
1
1
0
]
[
0
1
1
1
1
0
]
=
[
2
1
1
2
]
A^TA=\begin{bmatrix} 0 & 1 &1\\ 1 & 1&0\\ \end{bmatrix}\begin{bmatrix} 0 & 1 \\ 1 & 1\\ 1 & 0 \end{bmatrix}=\begin{bmatrix} 2 & 1 \\ 1 & 2\\ \end{bmatrix}
A T A = [ 0 1 1 1 1 0 ] ⎣ ⎡ 0 1 1 1 1 0 ⎦ ⎤ = [ 2 1 1 2 ]
A
A
T
=
[
0
1
1
1
1
0
]
[
0
1
1
1
1
0
]
=
[
1
1
0
1
2
1
0
1
1
]
AA^T=\begin{bmatrix} 0 & 1 \\ 1 & 1\\ 1 & 0 \end{bmatrix}\begin{bmatrix} 0 & 1 &1\\ 1 & 1&0\\ \end{bmatrix}=\begin{bmatrix} 1 & 1 &0\\ 1 & 2&1\\ 0 & 1& 1 \end{bmatrix}
A A T = ⎣ ⎡ 0 1 1 1 1 0 ⎦ ⎤ [ 0 1 1 1 1 0 ] = ⎣ ⎡ 1 1 0 1 2 1 0 1 1 ⎦ ⎤
A
T
A
A^TA
A T A
A
A
T
AA^T
A A T
A
T
A
A^TA
A T A
λ
1
=
3
;
v
1
=
[
1
2
1
2
]
;
λ
2
=
1
;
v
2
=
[
1
2
1
2
]
;
\lambda_1=3; v_1=\begin{bmatrix} \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} \end{bmatrix};\lambda_2=1;v_2=\begin{bmatrix} \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} \end{bmatrix};
λ 1 = 3 ; v 1 = [ 2
1 2
1 ] ; λ 2 = 1 ; v 2 = [ 2
1 2
1 ] ;
A
A
T
AA^T
A A T
λ
1
=
3
;
u
1
=
[
1
6
2
6
1
6
]
;
λ
2
=
1
;
u
2
=
[
1
2
0
−
1
2
]
;
λ
3
=
0
;
u
3
=
[
1
3
−
1
3
1
3
]
;
\lambda_1=3;u_1=\begin{bmatrix} \frac{1}{\sqrt{6}} \\ \frac{2}{\sqrt{6}} \\ \frac{1}{\sqrt{6}} \end{bmatrix};\lambda_2=1;u_2=\begin{bmatrix} \frac{1}{\sqrt{2}} \\ 0 \\ \frac{-1}{\sqrt{2}} \end{bmatrix};\lambda_3=0;u_3=\begin{bmatrix} \frac{1}{\sqrt{3}} \\ \frac{-1}{\sqrt{3}} \\ \frac{1}{\sqrt{3}} \end{bmatrix};
λ 1 = 3 ; u 1 = ⎣ ⎢ ⎡ 6
1 6
2 6
1 ⎦ ⎥ ⎤ ; λ 2 = 1 ; u 2 = ⎣ ⎡ 2
1 0 2
− 1 ⎦ ⎤ ; λ 3 = 0 ; u 3 = ⎣ ⎢ ⎡ 3
1 3
− 1 3
1 ⎦ ⎥ ⎤ ;
σ
i
=
λ
i
\sigma_i=\sqrt{\lambda_i}
σ i = λ i
3
\sqrt{3}
3
最后,我们得到A的奇异值分解为:
A
=
U
Σ
V
T
=
[
1
6
1
2
1
3
2
6
0
−
1
3
1
6
−
1
2
1
3
]
[
3
0
0
1
0
0
]
[
1
2
1
2
1
2
1
2
]
A=U\Sigma V^T=\begin{bmatrix} \frac{1}{\sqrt{6}} & \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{3}} \\ \frac{2}{\sqrt{6}} & 0 & \frac{-1}{\sqrt{3}}\\ \frac{1}{\sqrt{6}} & \frac{-1}{\sqrt{2}} & \frac{1}{\sqrt{3}} \end{bmatrix}\begin{bmatrix} \sqrt{3} & 0 \\ 0 & 1 \\ 0 & 0 \end{bmatrix}\begin{bmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{bmatrix}
A = U Σ V T = ⎣ ⎢ ⎡ 6
1 6
2 6
1 2
1 0 2
− 1 3
1 3
− 1 3
1 ⎦ ⎥ ⎤ ⎣ ⎡ 3
0 0 0 1 0 ⎦ ⎤ [ 2
1 2
1 2
1 2
1 ]
异值分解的应用有很多,比如:用SVD解PCA、潜在语言索引也依赖于SVD算法。可以说,SVD是矩阵分解、降维、压缩、特征学习的一个基础的工具,所以SVD在机器学习领域相当的重要。
1)降维:
通过奇异值分解的公式,我们可以很容易看出来,原来矩阵A的特征有n维。经过SVD分解后,可以用前r个非零奇异值对应的奇异向量表示矩阵A的主要特征,这样就把矩阵A进行了降维。
2)压缩:
通过奇异值分解的公式,我们可以看出来,矩阵A经过SVD分解后,要表示原来的大矩阵A,我们只需要存储U、Σ、V三个较小的矩阵即可。而这三个较小规模的矩阵占用内存上也是远远小于原有矩阵A的,这样SVD分解就起到了压缩的作用。
样本均值:
x
ˉ
=
1
n
∑
i
=
1
N
x
i
\bar x = \frac{1}{n}\sum_{i=1}^Nx_i
x ˉ = n 1 i = 1 ∑ N x i
样本方差:
S
2
=
1
n
−
1
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
S^2=\frac{1}{n-1}\sum_{i=1}^n(x_i-\bar x)^2
S 2 = n − 1 1 i = 1 ∑ n ( x i − x ˉ ) 2
样本X和样本Y的协方差
C
o
v
(
X
,
Y
)
=
E
[
(
X
−
E
(
X
)
)
(
Y
−
E
(
Y
)
)
]
=
1
n
−
1
∑
i
=
1
n
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
Cov(X,Y)=E[(X-E(X))(Y-E(Y))]=\frac{1}{n-1}\sum_{i=1}^n(x_i-\bar x)(y_i-\bar y)
C o v ( X , Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] = n − 1 1 i = 1 ∑ n ( x i − x ˉ ) ( y i − y ˉ )
由上面的公式,我们可以得到以下结论:
(1)方差的计算公式是针对一维特征,即针对同一特征不同样本的取值来进行计算得到;而协方差则必须要求至少满足二维特征;方差是协方差的特殊情况。
(2)方差和协方差的除数是n-1,这是为了得到方差和协方差的无偏估计。
协方差为正时,说明X和Y是正相关关系;协方差为负时,说明X和Y是负相关关系;协方差为0时,说明X和Y是相互独立。Cov(X,X)就是X的方差。当样本是n维数据时,它们的协方差实际上式协方差矩阵(对称方阵)。例如,对于3维数据(x,y,z),计算它的协方差就是:
C
o
v
(
X
,
Y
,
Z
)
=
[
C
o
v
(
x
,
x
)
C
o
v
(
x
,
y
)
C
o
v
(
x
,
z
)
C
o
v
(
y
,
x
)
C
o
v
(
y
,
y
)
C
o
v
(
y
,
x
)
C
o
v
(
z
,
x
)
C
o
v
(
z
,
x
)
C
o
v
(
z
,
z
)
]
Cov(X,Y,Z)=\begin{bmatrix} Cov(x,x) & Cov(x,y) &Cov(x,z) \\ Cov(y,x) & Cov(y,y) & Cov(y,x)\\ Cov(z,x) & Cov(z,x) & Cov(z,z) \end{bmatrix}
C o v ( X , Y , Z ) = ⎣ ⎡ C o v ( x , x ) C o v ( y , x ) C o v ( z , x ) C o v ( x , y ) C o v ( y , y ) C o v ( z , x ) C o v ( x , z ) C o v ( y , x ) C o v ( z , z ) ⎦ ⎤
散度矩阵定义为:
S
=
∑
k
=
1
n
(
x
k
−
m
)
(
x
k
−
m
)
T
S=\sum_{k=1}^n(x_k-m)(x_k-m)^T
S = k = 1 ∑ n ( x k − m ) ( x k − m ) T
m
=
1
n
∑
k
=
1
n
x
k
m=\frac{1}{n}\sum_{k=1}^nx_k
m = n 1 k = 1 ∑ n x k
对于数据X的散度矩阵为:
X
X
T
XX^T
X X T
其实协方差矩阵和三都矩阵关系密切,散度矩阵就是协方差矩阵乘以(总数据量-1)。因此它们的特征值和特征向量是一样的。这里值得注意的是,散度矩阵是SVD奇异值分解的一步,因此PCA和SVD是由很大联系的。
输入数据集:
X
=
{
x
1
,
x
2
,
x
3
,
…
,
x
n
}
X=\{x_1,x_2,x_3,\dots,x_n\}
X = { x 1 , x 2 , x 3 , … , x n }
需要降到K维
1)去平均值(即去中心化),即每一位特征减去各自的平均值
2)计算协方差矩阵
1
n
X
X
T
\frac{1}{n}XX^T
n 1 X X T
注:这里除或不除n或n-1,其实对求出的特征向量没有影响。
3)用特征值分解方法求协方差矩阵
1
n
X
X
T
\frac{1}{n}XX^T
n 1 X X T
4)对特征值从大到小排序,选择其中最大的k个,然后将其对应的k个特征向量分别作为行向量组成特征向量矩阵P。
5)将数据转换到k个特征向量构建的新空间中,即Y=PX。
例子
X
=
[
−
1
−
1
0
2
0
−
2
0
0
1
1
]
X=\begin{bmatrix} -1 & -1 & 0 &2 & 0\\ -2 & 0 & 0 &1 & 1 \end{bmatrix}
X = [ − 1 − 2 − 1 0 0 0 2 1 0 1 ]
以X为例,我们用PCA方法将这两行数据降到一行。
1)因为X矩阵的每行已经是零均值,所以不需要去平均值。
2)求协方差矩阵:
C
=
1
5
[
−
1
−
1
0
2
0
−
2
0
0
1
1
]
[
−
1
−
2
−
1
0
0
0
2
1
0
1
]
=
[
6
5
4
5
4
5
6
5
]
C=\frac{1}{5}\begin{bmatrix} -1 & -1 & 0 &2 & 0\\ -2 & 0 & 0 &1 & 1 \end{bmatrix}\begin{bmatrix} -1 & -2\\ -1 & 0\\ 0 & 0\\ 2 & 1\\ 0&1 \end{bmatrix}=\begin{bmatrix} \frac{6}{5} & \frac{4}{5}\\ \frac{4}{5}&\frac{6}{5} \end{bmatrix}
C = 5 1 [ − 1 − 2 − 1 0 0 0 2 1 0 1 ] ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ − 1 − 1 0 2 0 − 2 0 0 1 1 ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ = [ 5 6 5 4 5 4 5 6 ]
3)求协方差矩阵的特征值与特征向量。
求解后的特征值为:
λ
1
=
2
,
λ
2
=
2
5
\lambda_1=2,\lambda_2=\frac{2}{5}
λ 1 = 2 , λ 2 = 5 2
对应的特征向量为:
c
1
=
[
1
1
]
,
c
2
=
[
−
1
1
]
c_1=\begin{bmatrix} 1\\ 1 \end{bmatrix},c_2=\begin{bmatrix} -1\\ 1 \end{bmatrix}
c 1 = [ 1 1 ] , c 2 = [ − 1 1 ]
其中对应的特征向量分别是一个通解
c
1
c_1
c 1
c
2
c_2
c 2
[
1
2
1
2
]
,
[
−
1
2
1
2
]
\begin{bmatrix} \frac{1}{\sqrt{2}}\\ \frac{1}{\sqrt{2}} \end{bmatrix},\begin{bmatrix} -\frac{1}{\sqrt{2}}\\ \frac{1}{\sqrt{2}} \end{bmatrix}
[ 2
1 2
1 ] , [ − 2
1 2
1 ]
4)求得矩阵P为:
P
=
[
1
2
1
2
−
1
2
1
2
]
P=\begin{bmatrix} \frac{1}{\sqrt{2}}&\frac{1}{\sqrt{2}}\\ -\frac{1}{\sqrt{2}}&\frac{1}{\sqrt{2}} \end{bmatrix}
P = [ 2
1 − 2
1 2
1 2
1 ]
5)最后我们用P的第一行乘以数据矩阵X,就得到了降维后的表示:
Y
=
[
1
2
1
2
]
[
−
1
−
1
0
2
0
−
2
0
0
1
1
]
=
[
−
3
2
−
1
2
0
3
2
−
1
2
]
Y=\begin{bmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{bmatrix}\begin{bmatrix} -1 & -1 & 0 &2 & 0\\ -2 & 0 & 0 &1 & 1 \end{bmatrix}=\begin{bmatrix} -\frac{3}{\sqrt{2}} & -\frac{1}{\sqrt{2}}&0&\frac{3}{\sqrt{2}}&-\frac{1}{\sqrt{2}} \end{bmatrix}
Y = [ 2
1 2
1 ] [ − 1 − 2 − 1 0 0 0 2 1 0 1 ] = [ − 2
3 − 2
1 0 2
3 − 2
1 ]
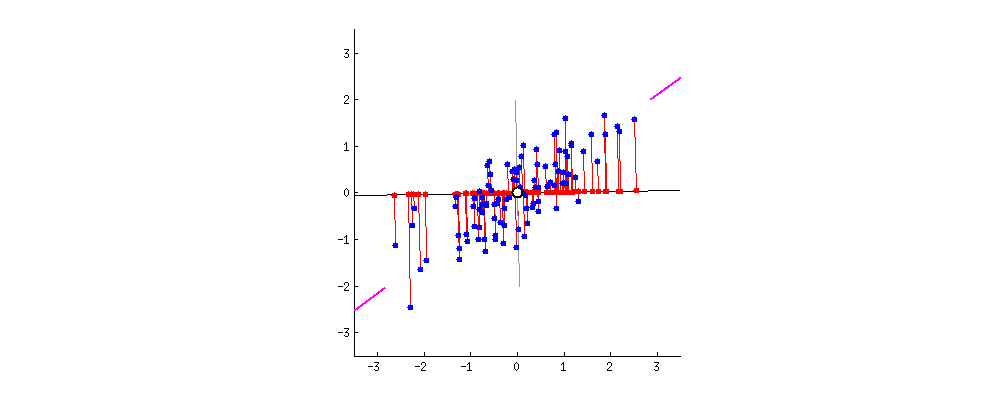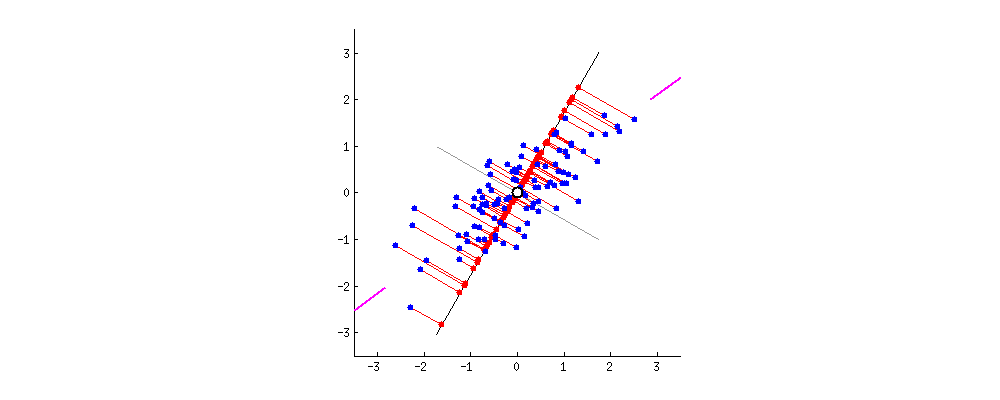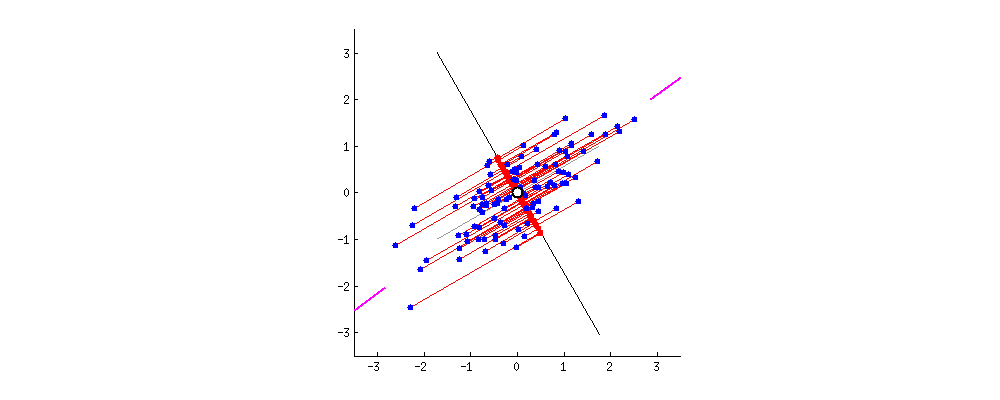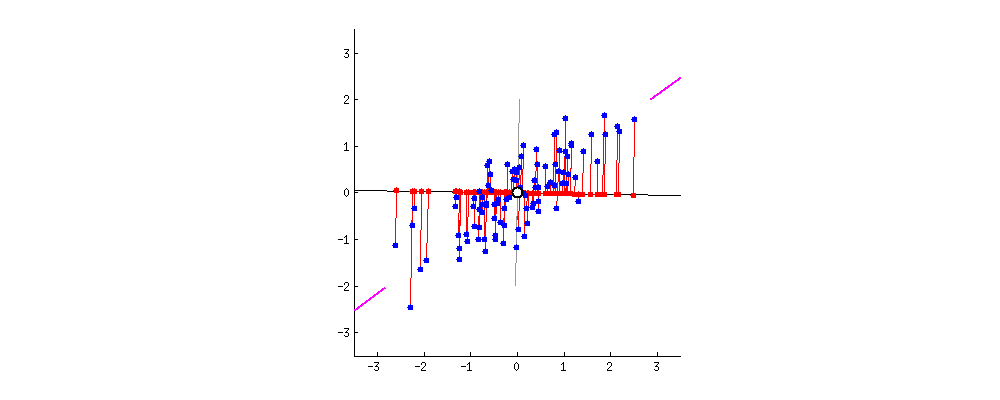
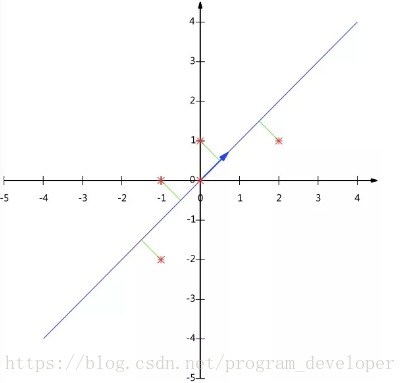
效果如下图所示
注意:
输入数据集:
X
=
{
x
1
,
x
2
,
x
3
,
…
,
x
n
}
X=\{x_1,x_2,x_3,\dots,x_n\}
X = { x 1 , x 2 , x 3 , … , x n }
需要降到K维
1)去平均值(即去中心化),即每一位特征减去各自的平均值
2)计算协方差矩阵
1
n
X
X
T
\frac{1}{n}XX^T
n 1 X X T
注:这里除或不除n或n-1,其实对求出的特征向量没有影响。
3)用SVD计算协方差矩阵
1
n
X
X
T
\frac{1}{n}XX^T
n 1 X X T
4)对特征值从大到小排序,选择其中最大的k个,然后将其对应的k个特征向量分别作为行向量组成特征向量矩阵P。
5)将数据转换到k个特征向量构建的新空间中,即Y=PX。
在PCA降维中,我们需要找到样本协方差矩阵
X
X
T
XX^T
X X T
当样本数多、样本特征数也多的时候,这个计算还是很大的。
当我们用SVD分解协方差矩阵的时候SVD有两个好处:
1.有一些SVD的实现算法可以先不求出协方差矩阵
X
X
T
XX^T
X X T
2.注意到PCA仅仅使用了我们SVD的左奇异矩阵,没有使用到右奇异值矩阵,那么右奇异值矩阵有什么用呢?假设我们的样本是
m
∗
n
m*n
m ∗ n
X
T
X
X^TX
X T X
k
∗
n
k*n
k ∗ n
V
T
V^T
V T
X
m
∗
k
′
=
X
m
∗
n
V
n
∗
k
T
X^{'}_{m*k}=X_{m*n}V_{n*k}^T
X m ∗ k ′ = X m ∗ n V n ∗ k T
m
∗
k
m*k
m ∗ k
X
′
X^{'}
X ′
m
∗
n
m*n
m ∗ n
##Python实现PCA
import numpy as np
import matplotlib.pyplot as plt
def pca(X,k):#k is the components you want
#mean of each feature
n_samples, n_features = X.shape
mean=np.array([np.mean(X[:,i]) for i in range(n_features)])
#normalization
norm_X=X-mean
#scatter matrix
scatter_matrix=np.dot(np.transpose(norm_X),norm_X)
#Calculate the eigenvectors and eigenvalues
eig_val, eig_vec = np.linalg.eig(scatter_matrix)
eig_pairs = [(np.abs(eig_val[i]), eig_vec[:,i]) for i in range(n_features)]
# sort eig_vec based on eig_val from highest to lowest
eig_pairs.sort(reverse=True)
# select the top k eig_vec
feature=np.array([ele[1] for ele in eig_pairs[:k]])
#get new data
data=np.dot(norm_X,np.transpose(feature))
return data
X = np.array([[-1, 1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
X_pca=pca(X,1)
X_pca
array([[-0.50917706],