数据降维即降低数据的维度,将原始高维特征空间中的点向一个低维度空间投影,新的空间维度低于原始特征空间,所以维度减少。在这个过程中,特征发生了根本性的变化,原始特征消失了(虽然新的特征也保持了原始特征的一些性质)。数据降维一方面可以解决维度灾难,降低复杂度。另一方面可以更好的认识和理解数据。
--------------------------------------------------------------------------
截至目前,数据降维的方法很多。从不同角度有不同的分类:
-
根据数据的特性可分为以下几种:
-
线性降维:主成分分析(Principal Component Analysis, PCA),线性判别分析(Linear Discriminant Analysis, LDA )等。
-
非线性降维:核方法(核主成分分析KPCA,KFDA),二维化和张量化(常见算法如二维主分量分析、二维线性判别分析、二维典型相关分析),流行学习[等距映射(ISOMap),拉普拉斯特征映射(LE),局部线性嵌入(LLE)]等。
-
根据是否考虑和使用数据的监督信息可分为以下几类:
-
无监督降维:PCA
-
有监督降维:LDA
-
半监督降维:半监督概率PCA ,半监督判别分析SDA
另外数据处理中通常会遇到特征维度比样本数量多的多的情况,如果直接运用模型处理,效果不一定好。一是因为冗余的特征会带来一些噪声,影响计算结果。二是因为无关的特征会加大计算量,耗费时间和资源。通常会把数据变换一下,数据变换的目的不仅是为了降维,还可以消除特征之间的关联性,并发现一些潜在的特征变量。
-----------------------------------------------------------------------------
主成分分析(PCA):
PCA的本质就是发现一些投影方向,使得数据在这些投影方向上方差最大,而且这些投影方向是互相正交的。即寻找新的正交基,然后计算原始数据在这些正交基上投影的方差。方差越大,说明在对应的正交基上包含了更多的信息量。输入空间经过旋转投影后,输出集合第一个向量包含了信号的大部分能量(即方差)。第二个向量与第一个向量正交,它包含了剩余能量的大部分。第三个向量与前两个向量正交,包含了剩余能量的大部分。以此类推。假设在N维空间中,可以找到N个这样相互正交的投影方向,取前r个去近似原始的N维空间,这样就从一个N维空间压缩到r维空间了。
方差:
方差(Variance)是度量一组数据的分散程度。方差越大,数据越分散。数据在某个特征维度上越分散,说明该特征越重要。方差是各个样本与样本均值的差的平方和的均值:
协方差:
协方差(Covariance)是度量两个变量的变动的同步程度,也就是度量两个变量线性相关性程度。如果协方差大于0表示一个变量增大是另一个变量也会增大,即正相关,协方差小于0表示一个变量增大是另一个变量会减小,即负相关。等于0表示不相关。
协方差矩阵:
协方差矩阵(Covariance matrix)由数据集中两两变量的协方差组成。矩阵的第(i,j)个元素是数据集中第i和第j个元素的协方差。
PCA 的基本实现过程:
- 计算样本每一列的平均值,然后所有的样本减去对应的均值。
- 计算整个样本的协方差矩阵。(协方差矩阵是度量维度间的差异,而非样本间差异。协方差矩阵的主对角线上的元素是各个维度上的方差)
- 计算协方差的特征值和特征向量矩阵计算协方差的特征值和特征向量矩阵。
- 将特征值按照从到到小的顺序排列,选择其中较大的k个,然后将其对应的k个特征向量分别作为列向量组成特征向量矩阵。
- 原始数据乘以组成的特征向量矩阵,得到样本点在选取的特征向量的投影。
PCA代码:
def eigValPct(eigVals, percentage):
sortArray = sort(eigVals) #特征值排序
sorAtrray = sortArray[::-1] #返转从大到小排列特征值
sumArray = sum(sortArray) #所有特征值求和
for i in sortArray:
tempsum = 0
num = 0
tempsum += i
num += 1
if tempsum >= sumArray * percentage: #前i个特征值的和大于所有特征值的占比
return num
def pca(dataMat, percentage=0.9):
meanMat = mean(dataMat, axis = 0) # 按列求均值
Mat = dataMat - meanMat # 均值化
covMat = cov(Mat, rowvar = 0) #求协方差
eigVals, eigVects = linalg.eig(mat(covMat)) #求出特征值和特征向量
k = eigValPct(eigVals, percentage)
eigVals = sort(eigVals)
eigVals = eigVals[::-1]
eigValues = eigVals[:k] #取前k个特征值
eigVectors = eigVects[:, eigValues] # 特征值对应的特征向量
DeMat = dataMat * eigVectors #将原始数据投影到主成分上得到的低维数据
return DeMat
PCA降维实例(数据是随便填写的):
import pandas as pd
path = './data'
data = pd.read_table(path) #读取数据
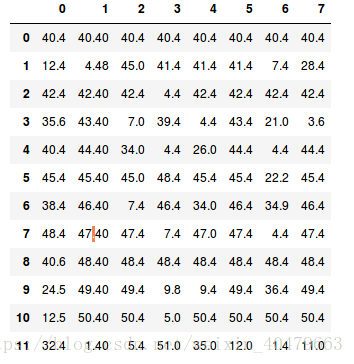
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(data) #使用数据拟合
pca.components_ #返回模型的各个特征向量

pca.explained_variance_ #返回模型的各个特征值
HM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDQ3OTY2Mw==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
pca.explained_variance_ratio_ #返回模型各个成分各自的方差百分比
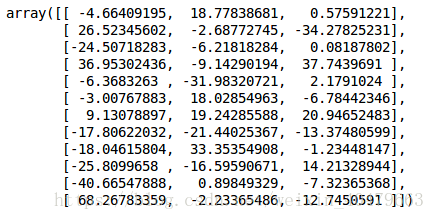
可以看到前3个特征所占比率有15%以上所以选择降维后的特征维度数目为3

pca = PCA(3)
pca.fit(data)
low = pca.transform(data) #降维
low
主要参数:
与PCA 相关的类都在sklearn.decomposition包中。最常使用的就是sklearn.decomposition.PCA,在使用这个PCA 时候基本不需要调参数,一般来说只需要指定需要降到的维度,或者希望降维后的主成分的方差和占原始维度所有特征方差和的比率阈值就可以了。

- copy:是否拷贝一份原始数据,一般为True.如果为False,就会在原始数据上进行降维。
- n_components:用户指定希望降维后的特征维度数目。
- whiten:是否白化。所谓白化就是对降维后的数据每个特征进行归一化,让方差都为1。对于PCA本身来说一般不需要白化,后续如果还有数据处理动作,可以考虑白化。
- svd_solver:即指定奇异值分解SVD的方法。特征分解是奇异值分解SVD的一个特例,一般PCA库都是基于SVD实现的。(后续会讲解SVD)