文章目录
1. 回归分析概述
回归分析是处理多变量间相关关系的一种数学方法。相关关系不同于函数关系,函数关系反应变量间严格依存性,简单说就是一个自变量对应一个因变量。而相关分析中,对自变量的每一个取值,因变量可以有多个数值与之对应。在统计上,研究相关关系可以运用 回归分析 和 相关分析。
当自变量为非随机变量而因变量为随机变量时,它们的关系分析成为 回归分析。当自变量和因变量都是随机变量时,它们的关系分析称为 相关分析。回归分析和相关分析往往不加区分。广义上说,相关分析包括回归分析,但是严格说两者是有区别的。
具有相关关系的两个变量 ξ 和 η(ξ:克西、η :伊塔 ),它们之间虽然存在着密切的关系,但不能由一个变量精确地求出另一个变量的值。通常选用 ξ = x 时 η 的数学期望作为对应 ξ = x 时 η 的代表值,因此它反映 ξ = x 条件下 η 取值的平均水平。这样的对应关系称为 回归关系。根据回归分析可以建立变量间的数学表达式,称为 回归方程。回归方程反映自变量在固定条件下因变量的平均状态变化情况。
具有相关关系的变量之间虽然具有某种不确定性,但是通过对现象的不断观察可以探索出它们之间的统计规律,这类统计规律称为 回归关系。有关回归关系理论、计算和分析称为 回归分析。
回归分析可以分为 线性回归分析 和 逻辑回归分析。
2. 线性回归
线性回归就是将输入项分别乘以一些常量,再将结果加起来得到输出。线性回归包括一元线性回归和多远线性回归。
线性回归模型的优缺点
- 优点:快速;没有调节参数;可轻易解释;了理解。
- 缺点:相比其他复杂一些的模型,其预测准确率不高,因为它假设特征和响应之间存在确定的线性关系,这种假设对于非线性的关系,线性模型显然不能很好地进行数据建模。
2.1 简单线性回归分析
线性回归分析中,如果仅有一个自变量与一个因变量,且其关系大致可以用一条直线表示,则称之为 简单线性回归分析。
如果发现因变量 Y 和自变量 X 之间存在高度的正相关,则可以确定一条直线方程,使得所有的数据点尽可能接近这条拟合的直线。
其中
为因变量,
为截距,
为相关系数,
为自变量。
2.2 多元线性回归分析
多元线性回归分析是简单线性回归分析的推广,指的是多个因变量对多个自变量的回归分析。其中最常用的是只限于一个因变量但有多个自变量的情况,也叫做多重回归分析。
其中,
代表截距,
为回归系数。
2.3 非线性回归数据分析
数据挖掘中常用的一些非线性回归模型:
- 渐进回归模型
- 二次曲线模型
- 双曲线模型
3. 用 python 实现一元线性回归
一个简单的线性回归的例子就是房子价值预测问题。一般来说,房子越大,房屋的价值越高。
数据集:input_data.csv
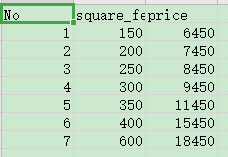
说明:
No:编号
square_feet:平方英尺
price:价格(元/平方英尺)
代码如下:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import linear_model
# 读取数据的函数
def get_data(file_name):
data = pd.read_csv(file_name)
X = []
Y = []
for square_feet, price in zip(data["square_feet"],data["price"]):
X.append([square_feet])
Y.append(price)
return X,Y
# 建立线性模型,并进行预测
def get_linear_model(X, Y, predict_value):
model = linear_model.LinearRegression().fit(X,Y)
pre = model.predict(predict_value)
predictions = {}
predictions["intercept"] = model.intercept_ # 截距值
predictions["coefficient"] = model.coef_ # 回归系数(斜率)
predictions["predictted_value"] = pre
return predictions
# 显示线性拟合模型结果
def show_linear_line(X,Y):
model = linear_model.LinearRegression().fit(X,Y)
plt.scatter(X,Y)
plt.plot(X,model.predict(X),color="red")
plt.title("Prediction of House")
plt.xlabel("square feet")
plt.ylabel("price")
plt.show()
# 定义主函数
def main():
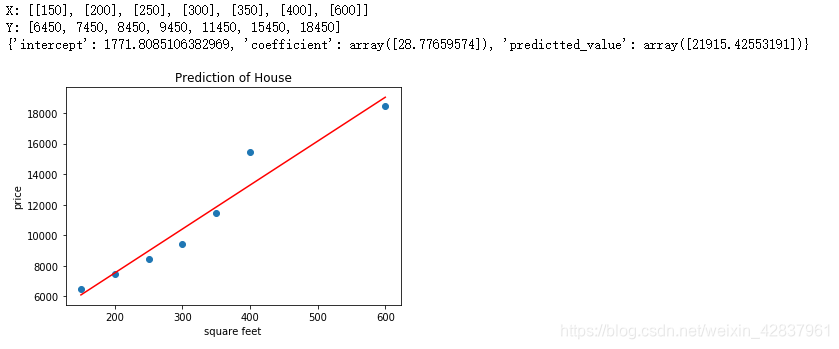
X, Y = get_data("input_data.csv")
print("X:",X)
print("Y:",Y)
predictions = get_linear_model(X,Y,[[700]])
print(predictions)
show_linear_line(X,Y)
main()
结果截图:
4. 用 python 实现多元线性回归
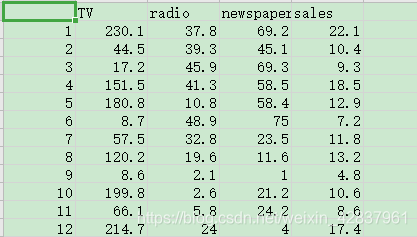
当结果值影响因素有多个时,可以采用多元线性回归模型。例如:商品的销售额可能与电视广告投入、收音机广告投入和报纸广告投入有关系,可以有:
数据集:Advertising.csv
代码如下:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import explained_variance_score,\
mean_absolute_error,mean_squared_error,median_absolute_error,r2_score
# 1.读取数据
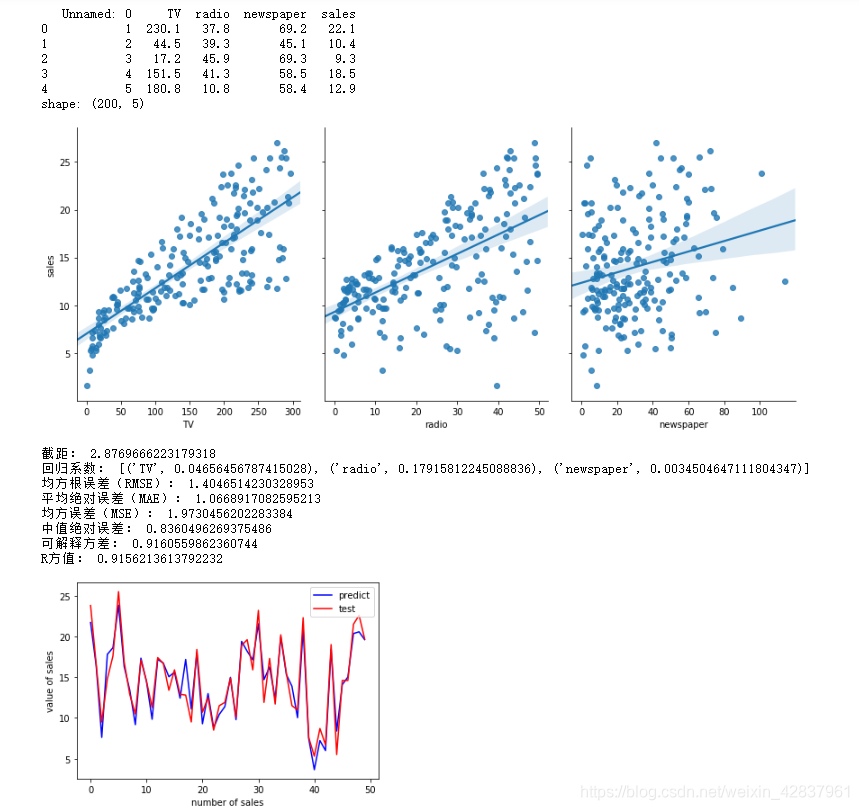
data = pd.read_csv("Advertising.csv")
print(data.head())
print("shape:",data.shape)
# 2.分析数据
sns.pairplot(data, x_vars=["TV","radio","newspaper"], y_vars="sales",height=5,aspect=0.8,kind="reg")
plt.show()
# 3.建立线性回归模型
# (1)使用 pandas 构建 X(特征向量)和 y(标签列)
feature_cols = ["TV","radio","newspaper"]
X = data[feature_cols]
y = data["sales"]
# (2)构建训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=1) # 25% 测试
# (3)构建线性回归模型并训练
model = LinearRegression().fit(X_train,y_train)
# (4)输出模型结果
print("截距:",model.intercept_)
coef = zip(feature_cols, model.coef_)
print("回归系数:",list(coef))
# 4. 预测
y_pred = model.predict(X_test)
# 5. 评价
# 这个是自己写函数计算
sum_mean = 0
for i in range(len(y_pred)):
sum_mean += (y_pred[i] - y_test.values[i])**2
sum_erro = np.sqrt(sum_mean/len(y_test))
print("均方根误差(RMSE):",sum_erro)
# 这个是调用已有函数,以后就直接用
print("平均绝对误差(MAE):",mean_absolute_error(y_test,y_pred))
print("均方误差(MSE):",mean_squared_error(y_test,y_pred))
print("中值绝对误差:",median_absolute_error(y_test,y_pred))
print("可解释方差:",explained_variance_score(y_test,y_pred))
print("R方值:",r2_score(y_test,y_pred))
# 绘制 ROC 曲线
plt.plot(range(len(y_pred)),y_pred,"b",label="predict")
plt.plot(range(len(y_pred)),y_test,"r",label="test")
plt.xlabel("number of sales")
plt.ylabel("value of sales")
plt.legend(loc="upper right")
plt.show()
结果截图:
说明:
- pandas 两个主要的数据结构是 Series 和 DataFrame;Series 类似于一维数组,它由一组数据及一组与之有关的数据标签(及索引)组成;DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型。DataFrame 既有行索引也有列索引。
- 在分析数据时,使用了 seaborn 包,这个包数据可视化效果更好。其实 seaborn 包 也属于 Matplotlib 的内部包,只是需要单独安装。
- scikit-learn 要求 X 是一个特征矩阵,y 是一个 Numpy 向量。因此,X 可以是 pandas 的 DataFrame,y 可以是 pandas 的 Series。
- 对于分类问题,评价测度是准确率,但其不适用于回归问题,因此使用针对连续数值的评价测度(evaluation metrics)。
5. 逻辑回归
逻辑回归也被称为广义线性回归模型,它与线性回归模型的形式基本上相同,最大的区别就在于它们的因变量不同,如果是连续的,就是多重线性回归;如果是二项分布,就是逻辑回归(Logistic);逻辑回归实际上是一种分类方法,主要用于二分类问题(即输出只有两种,分别代表两个类别)。
逻辑回归的过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证这个求解模型的好坏。
逻辑回归的优缺点
- 优点:速度快,适合二分类问题;简单。易于理解,可以直接看到各个特征的权重;能容易地更新模型吸收新的数据。
- 缺点:对数据和场景的适应能力有局限性,不如决策树算法强。
逻辑回归的常规步骤
- 寻找 函数(预测函数)
- 构造 函数(损失函数)
- 想办法使 函数最小并求得回归参数 (θ)
5.1 构造预测函数(假设函数)
二类分类问题的概率与自变量之间的关系图形往往是一个 S 型曲线,采用 sigmoid 函数实现,函数形式:

对于线性边界情况,边界形式如下:
说明:
为输入数据的特征,
为回归系数,也可以理解为权重
。
最佳参数:
构造预测函数为:
sigmod 函数输出是介于 (0,1) 之间的,中间值是 0.5。
的输出也是介于 (0,1) 之间的,也就表明了数据属于某一类别的概率。例如,
则说明当前数据属于 A 类;
则说明当前数据属于 B 类。所以 sigmod 函数看成样本数据的概率密度函数。
函数
的值有特殊的含义,它表示结果取 1 的概率,因此对于输入
分类结果为类别 1 和类别 0 的概率分别为:
5.2 构造损失函数
机器学习模型中把 单个样本 的预测值与真实值的差称为 损失,一般情况下,损失越小,模型越好(有可能存在 过拟合)。用于计算损失的函数称为 损失函数(Loss Function)。模型的每一次预测的好坏用损失函数度量。
代价函数 (Cost Function)是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
与多元线性回归所采用的最小二乘法的参数估计相对应,最大似然法是逻辑回归所采用的参数估计法。其原理是找到这样一个参数,可以让样本数据所包含的观察值被观察到的可能性最大。这种寻找最大可能性的方法需要反复计算,对计算能力有很高的要求。最大似然法的优点是大样本数据中参数的估计稳定、偏差小、估计方差小。
接下来使用概率论中极大似然估计的方法求解损失函数(需要大家有概率论和高数的知识储备,后面有说明):
首先得到概率函数为:
因为样本数据(m 个)独立,所以它们的联合分布可以表示为各边际分布的乘积,取 似然函数为:
取对数似然函数:
最大似然估计就是要求使
取最大值时的
,这里可以使用 梯度上升法 求解,求得的
就是要求的最佳参数:
基于最大似然估计推导得到的
函数和
函数如下:
上面的分段函数可以合并为一条式子:
说明:
- 梯度是求函数关于各个变量的偏导数,所以它代表函数值增长最快的方向。
- 梯度上升算法求函数的最大值,梯度下降算法求函数的最小值。
- 梯度上升法迭代公式:
其中 为步长,步长决定了梯度在迭代过程中,每一步沿梯度方向前进的长度。( 也称为 学习率)
梯度下降公式就是将 + 号改为 - 号。
5.3 梯度下降法求解最小值
因为要求损失函数 最小值,所以采用梯度下降的方法。
1.
更新过程
更新过程可以写成:
2. 向量化
约定训练数据的矩阵形式如下,
的每一行为一条训练样本,而每一列为不同的特征取值:
的参数
为一列向量,所以实现
函数时要支持列向量作为参数,并返回列向量。
的更新过程可以改为:
3. 正则化
过拟合 即过分拟合了训练数据,使得模型的复杂度提高,泛化能力较差(对未知数据的预测能力)。
可以使用正则化解决过拟合问题,正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项或惩罚项。正则化一般是模型复杂度的单调递增函数,模型越复杂,正则化项就越大。
正则项可以采取不同的形式,在回归问题中取平方损失,就是参数的
范数,也可以取
范数。取平方损失时,模型的损失函数变为:
说明:
- 系数乘以 是因为减小个别较大极端值对损失函数的影响,乘以一个小于 1 的系数,可以看做是减小噪声(极端值)。也可以是 , ,但一般选择 。
- λ 是正则项系数:
- 如果它的值很大,说明对模型的复杂度惩罚大,对拟合数据的损失惩罚小,这样它就不会过分拟合数据,在训练数据上的偏差较大,在未知数据上的方差较小,可能出现欠拟合的现象。
- 如果它的值很小,说明比较注重对训练数据的拟合,在训练数据上偏差会小,但是可能导致过拟合。
正则化后的梯度下降算法
的更新变为:
6. 用 Python 实现逻辑回归
数据集:data.csv
说明:一共 100 条数据,前两列是数据的两个特征,第三列是分类结果(标签列)
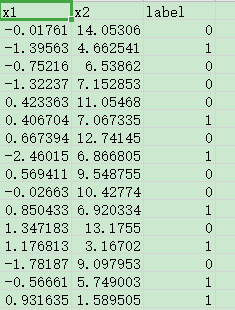
代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 定义读取数据函数
def loadDateSet(filename):
df = pd.read_csv(filename) # 读取数据
m = df.shape[0] # m为数据条数
df["x0"] = np.ones((m,1)) # 为数据增加一列值为 1.0 的数据
data = df[["x0","x1","x2"]] # 为数据的特征 x0,x1,x2
label = df["label"] # 标签列
return data,label
# 定义sigmod函数
def sigmod(x):
return 1.0 /(1 + np.exp(-x))
# 返回权重函数
def gradAscent(data,label):
m,n = data.shape # m(行数)=100,n(列数)=3(特征数)
data = np.mat(data) # 将数据转化为矩阵 100*3
label = np.mat(label).T # 将标签转化为矩阵 100*1
weights = np.ones((n,1)) # 初始化回归系数,每个系数初始化为 1.0,三行一列
maxCricles = 5000 # 迭代次数
alpha = 0.001 # 步长(学习率)
for i in range(maxCricles):
h =sigmod(data*weights) # 将数据的特征值*系数的值作为 sigmod函数的输入
error = label - h # 计算每个样本的sigmod函数输出与标签的差值
weights = weights + alpha*data.T*error # 更新权重
#print("第 {} 次循环,error[0]= {}".format(i + 1, error[0]))
return weights
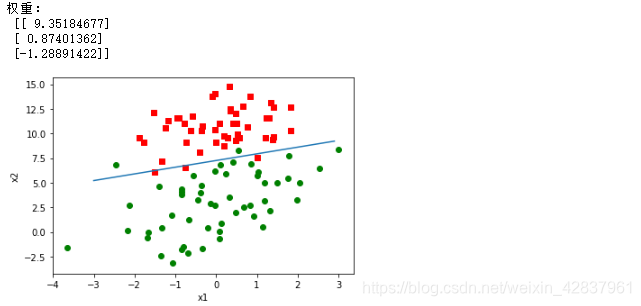
# 画出最终分类的图
def plotBestFit(data,label,weights):
data = np.array(data) # 将数据转化为数组
weights = np.array(weights) # 将权重转化为数组
m = data.shape[0] # 数据的条数m
x0 = []; y0 = []; # 标签为0的数据点的x坐标,y坐标
x1 = []; y1 = []; # 标签为1的数据点的x坐标,y坐标
for i in range(m):
if label[i] == 0:
x0.append(data[i,1]); y0.append(data[i,2])
else:
x1.append(data[i,1]); y1.append(data[i,2])
plt.scatter(x0,y0,c="red",marker="s")
plt.scatter(x1,y1,c="green")
x = np.arange(-3.0,3.0,0.1) # 直线的x坐标
y = (-weights[0] - weights[1]*x)/weights[2] # 直线的y坐标
plt.plot(x,y)
plt.xlabel("x1")
plt.ylabel("x2")
plt.show()
# 定义主函数
def main():
weights = gradAscent(data,label)
print("权重:\n",weights)
plotBestFit(data,label,weights)
main()
结果截图:
下面的代码是用 python 直接写好的逻辑回归函数:以后直接使用。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# 1.读取数据
data = pd.read_csv("data.csv")
print(data.head())
print("shape:",data.shape)
# 2.建立逻辑回归模型
#(1)构建 X(特征向量)和 y(标签列)
feature_cols = ["x1","x2"]
X = data[feature_cols]
y = data["label"]
#(2)构建训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=1) # 25% 测试
#(3)构建逻辑回归模型并训练
model = LogisticRegression().fit(X_train,y_train)
#(4)输出模型结果
print("截距:",model.intercept_)
print("回归系数:",model.coef_)
# 3.预测
y_pred = model.predict([[0.5564,-1.5543]])
print("预测类别:",y_pred)
# 4.评价模型准确率
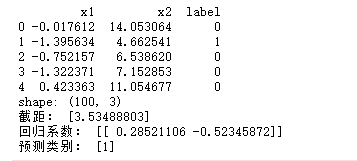
model.score(X_test,y_test)
运行结果截图: